fastText_multilingual
1.0.0
請注意,該存儲庫不再由Babylon Health積極維護。為了進一步的幫助,請與紙質作者聯繫。
Facebook最近以89種語言開源的單詞向量。但是這些矢量是單語的。這意味著,儘管一種語言中的類似單詞共享相似的向量,但來自不同語言的翻譯單詞沒有相似的向量。在ICLR 2017上最近的一篇論文中,我們展示瞭如何使用SVD來學習線性轉換(矩陣),該線性轉換(矩陣)與單個向量空間中的兩種語言相一致。在此存儲庫中,我們提供了78個矩陣,可以用來對齊單個空間中的大多數FastText語言。
此讀書我解釋了應如何使用矩陣。我們還提出了一個簡單的評估任務,我們表明我們能夠成功預測多種語言的單詞翻譯。我們的程序依賴於用兩種語言收集單語言培訓字典,但是非常明顯的是,我們能夠成功預測我們沒有培訓詞典的語言對之間的單詞翻譯!
單詞嵌入通過其向量的標準化內部產物來定義兩個單詞之間的相似性。此存儲庫中語言中的矩陣在一個空間中,而沒有更改這些單語的任何相似性關係。當您將結果多語言向量用於單語任務時,它們的性能與原始向量完全相同。要了解有關單詞嵌入的更多信息,請查看Colah的博客或Sam對向量表示的介紹。
請注意,自從我們發布此存儲庫以來,Facebook已發布了另外204種語言;但是,原始90種語言的矢量詞沒有更改,並且該存儲庫中提供的轉換仍然可以正常工作。如果您想學習自己的對齊矩陣,我們將在align_your_own.ipynb中提供一個示例。
如果您使用此存儲庫,請引用:
離線雙語詞向量,正交轉換和倒置的軟詞
塞繆爾·史密斯(Samuel L.
ICLR 2017(會議軌道)
克隆此存儲庫的本地副本,然後從這裡下載您需要的FastText Vectors。我將假設您以文本格式下載了法語和俄語的向量。假設我們想比較“聊天”和“自志”的相似性。我們加載vectors一詞:
from fasttext import FastVector
fr_dictionary = FastVector ( vector_file = 'wiki.fr.vec' )
ru_dictionary = FastVector ( vector_file = 'wiki.ru.vec' )我們可以提取矢量一詞併計算它們的餘弦相似性:
fr_vector = fr_dictionary [ "chat" ]
ru_vector = ru_dictionary [ "кот" ]
print ( FastVector . cosine_similarity ( fr_vector , ru_vector ))
# Result should be 0.02餘弦相似性在-1到1之間。似乎“聊天”和“自志”既不相似也不相似。但是現在,我們將轉換應用於一個空間中的兩個詞典:
fr_dictionary . apply_transform ( 'alignment_matrices/fr.txt' )
ru_dictionary . apply_transform ( 'alignment_matrices/ru.txt' )並重新評估餘弦的相似性:
print ( FastVector . cosine_similarity ( fr_dictionary [ "chat" ], ru_dictionary [ "кот" ]))
# Result should be 0.43事實證明,“聊天”和“見人”畢竟非常相似。這很好,因為它們都表示“貓”。
在Facebook提供的89種語言中,有78種由Google Translate API支持。我們首先在英語FastText詞彙中獲得了10,000個最常見的單詞,然後使用API將這些單詞翻譯成78種可用的語言。我們將此詞彙分為兩分,將前5000個單詞分配給訓練詞典,第二個5000個單詞分配給了測試詞典。
我們在此博客中描述了對齊過程。它需要兩種單詞向量和兩種語言的翻譯對的小型雙語詞典。並生成一個矩陣,該矩陣將源語言與目標保持一致。有時,Google會將英語單詞翻譯成非英語短語,在這些情況下,我們平均該短語中包含的vectors一詞。
要將所有78種語言都放在一個空間中,我們將每種語言與英語向量保持一致(英語矩陣是身份)。
為了證明該過程有效,我們可以預測訓練詞典中未看到的單詞的翻譯。為簡單起見,我們預測最近鄰居的翻譯。因此,例如,如果我們想將“狗”翻譯成瑞典語,我們會發現瑞典語向量與“狗”詞向量相似的瑞典語向量最高。
首先,讓我們測試從英語到其他所有語言的翻譯性能。對於每個語言對,我們從測試詞典中提取一組2500個單詞對。精度@n表示,在該集合中的2500個目標單詞中,真實翻譯是源單詞最接近的鄰居之一。如果對齊完全隨機,我們希望Precision @1約為0.0004。
| 目標語言 | Precision @1 | Precision @5 | Precision @10 |
|---|---|---|---|
| fr | 0.73 | 0.86 | 0.88 |
| pt | 0.73 | 0.86 | 0.89 |
| es | 0.72 | 0.85 | 0.88 |
| 它 | 0.70 | 0.86 | 0.89 |
| NL | 0.68 | 0.83 | 0.86 |
| 不 | 0.68 | 0.85 | 0.89 |
| da | 0.66 | 0.84 | 0.88 |
| CA | 0.66 | 0.81 | 0.86 |
| SV | 0.65 | 0.82 | 0.86 |
| CS | 0.64 | 0.81 | 0.85 |
| ro | 0.63 | 0.81 | 0.85 |
| de | 0.62 | 0.75 | 0.78 |
| pl | 0.62 | 0.79 | 0.83 |
| 胡 | 0.61 | 0.80 | 0.84 |
| fi | 0.61 | 0.80 | 0.84 |
| EO | 0.61 | 0.80 | 0.85 |
| ru | 0.60 | 0.78 | 0.82 |
| GL | 0.60 | 0.77 | 0.82 |
| MK | 0.58 | 0.79 | 0.84 |
| ID | 0.58 | 0.81 | 0.86 |
| BG | 0.57 | 0.77 | 0.82 |
| 多發性硬化症 | 0.57 | 0.81 | 0.86 |
| 英國 | 0.57 | 0.75 | 0.79 |
| sh | 0.56 | 0.77 | 0.81 |
| 人力資源 | 0.56 | 0.75 | 0.80 |
| tr | 0.56 | 0.77 | 0.81 |
| SL | 0.56 | 0.77 | 0.82 |
| El | 0.54 | 0.75 | 0.80 |
| SK | 0.54 | 0.75 | 0.81 |
| 等 | 0.53 | 0.73 | 0.78 |
| Sr | 0.53 | 0.72 | 0.77 |
| AF | 0.52 | 0.75 | 0.80 |
| 上尉 | 0.50 | 0.72 | 0.79 |
| ar | 0.48 | 0.69 | 0.75 |
| BS | 0.47 | 0.70 | 0.77 |
| LV | 0.47 | 0.68 | 0.75 |
| 歐盟 | 0.46 | 0.68 | 0.75 |
| fa | 0.45 | 0.68 | 0.75 |
| hy | 0.43 | 0.66 | 0.73 |
| 平方英尺 | 0.43 | 0.65 | 0.71 |
| 是 | 0.43 | 0.64 | 0.70 |
| ZH | 0.40 | 0.68 | 0.75 |
| ka | 0.40 | 0.63 | 0.71 |
| CY | 0.39 | 0.63 | 0.71 |
| 你好 | 0.39 | 0.58 | 0.63 |
| AZ | 0.38 | 0.60 | 0.67 |
| ko | 0.37 | 0.58 | 0.66 |
| TE | 0.36 | 0.56 | 0.63 |
| KK | 0.35 | 0.60 | 0.68 |
| 他 | 0.33 | 0.45 | 0.48 |
| FY | 0.33 | 0.52 | 0.60 |
| vi | 0.31 | 0.53 | 0.62 |
| ta | 0.31 | 0.50 | 0.56 |
| BN | 0.30 | 0.49 | 0.56 |
| ur | 0.29 | 0.52 | 0.61 |
| 是 | 0.29 | 0.51 | 0.59 |
| TL | 0.28 | 0.51 | 0.59 |
| kn | 0.28 | 0.43 | 0.46 |
| 古 | 0.25 | 0.44 | 0.51 |
| Mn | 0.25 | 0.49 | 0.58 |
| uz | 0.24 | 0.43 | 0.51 |
| SI | 0.22 | 0.40 | 0.45 |
| ML | 0.21 | 0.35 | 0.39 |
| 肯 | 0.20 | 0.40 | 0.49 |
| 先生 | 0.20 | 0.37 | 0.44 |
| Th | 0.20 | 0.33 | 0.38 |
| 洛杉磯 | 0.19 | 0.34 | 0.42 |
| JA | 0.18 | 0.44 | 0.56 |
| NE | 0.16 | 0.33 | 0.38 |
| PA | 0.16 | 0.32 | 0.38 |
| TG | 0.14 | 0.31 | 0.39 |
| 公里 | 0.12 | 0.26 | 0.30 |
| 我的 | 0.10 | 0.19 | 0.23 |
| 磅 | 0.09 | 0.18 | 0.21 |
| 毫克 | 0.07 | 0.18 | 0.25 |
| CEB | 0.06 | 0.13 | 0.18 |
如您所見,對齊比隨機好得多!通常,該程序最適合其他歐洲語言,例如法語,葡萄牙語和西班牙語。我們使用2500個單詞對,因為測試字典中有5000個單詞,並非Google翻譯API實際上都存在於FastText詞彙中。
現在,讓我們做一些更令人興奮的事情,讓我們評估所有可能的語言對之間的翻譯性能。我們在下面的熱圖上展示了這種翻譯性能,其中元素的顏色表示precision @1當從行語言翻譯成列的語言時。
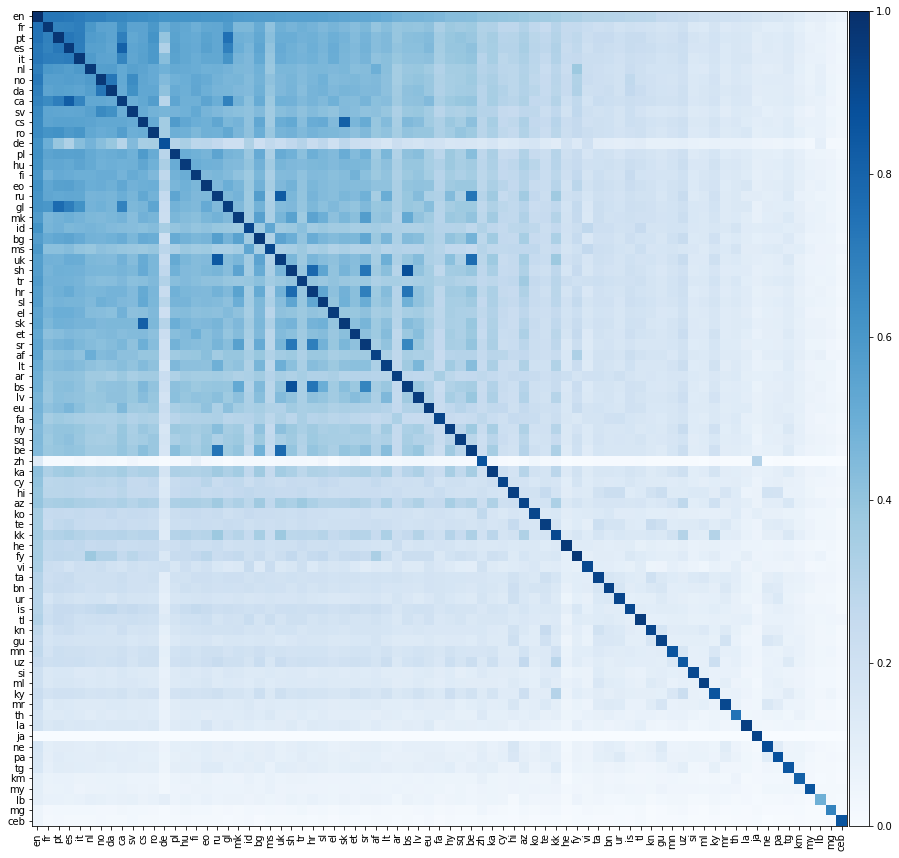
我們應該強調的是,所有語言都僅與英語保持一致。我們沒有在非英語語言對之間提供培訓詞典。然而,我們仍然能夠非常準確地對非英語語言對之間的翻譯進行成功。
我們希望上面的矩陣的對角線元素是1,因為一種語言應該完美地轉化為自身。但是,實際上,這並不總是發生,因為我們通過將常見的英語單詞翻譯成其他語言來構建培訓和測試詞典。有時,多個英語單詞轉化為相同的非英語單詞,因此在測試集中可能會多次出現相同的非英語單詞。我們尚未正確考慮這一點,從而降低了翻譯性能。
刻薄的是,即使我們只是將語言直接與英語保持一致,有時一種語言比英語更像是另一種非英語語言!我們可以計算兩種語言的配對精度;從語言1到語言2的平均精度,反之亦然。我們還可以計算英語對精度;從英語到語言1以及英語到語言2的精確度的平均值。在下面,我們列出了對層間精度的所有語言對超過英語對的精度:
| 語言1 | 語言2 | 配對精度 @1 | 英語對精度 @1 |
|---|---|---|---|
| BS | sh | 0.88 | 0.52 |
| ru | 英國 | 0.84 | 0.58 |
| CA | es | 0.82 | 0.69 |
| CS | SK | 0.82 | 0.59 |
| 人力資源 | sh | 0.78 | 0.56 |
| 是 | 英國 | 0.77 | 0.50 |
| GL | pt | 0.76 | 0.66 |
| BS | 人力資源 | 0.74 | 0.52 |
| 是 | ru | 0.73 | 0.51 |
| da | 不 | 0.73 | 0.67 |
| Sr | sh | 0.73 | 0.54 |
| pt | es | 0.72 | 0.72 |
| CA | pt | 0.70 | 0.69 |
| GL | es | 0.70 | 0.66 |
| 人力資源 | Sr | 0.69 | 0.54 |
| CA | GL | 0.68 | 0.63 |
| BS | Sr | 0.67 | 0.50 |
| MK | Sr | 0.56 | 0.55 |
| KK | 肯 | 0.30 | 0.28 |
所有這些語言對具有非常緊密的語言根源。例如,上面的第一對是波斯尼亞人和塞爾伯 - 克羅地亞人;波斯尼亞是塞爾博 - 克羅地亞人的變體。第二對是俄羅斯和烏克蘭人。兩種東拉語言。看來兩種語言越相似,它們的fastText載體的幾何形狀越相似。導致改進的翻譯性能。
此存儲庫中提供的矩陣是正交的。直觀地,每個矩陣可以分解為一系列旋轉和反射。旋轉和反射不會改變向量空間中任意兩個點之間的距離;因此,語言中單詞向量之間的內在產品沒有改變,只有不同語言的矢量之間的內部產品受到影響。
關於這個主題有許多很棒的論文。我們在下面列出了其中的一些:
許多讀者對我們在此存儲庫中使用的培訓和測試詞典表示了興趣。我們本來希望上傳這些,但是,儘管我們沒有採取法律建議,但我們擔心這可以解釋為打破Google Translate API的條款。
轉換矩陣分佈在Creative Commons歸因與共享許可證3.0下。


