fastText_multilingual
1.0.0
Tenga en cuenta que este repositorio ya no es mantenido activamente por Babylon Health. Para obtener más ayuda, comuníquese con los autores del papel.
Facebook recientemente vectores de palabras de código abierto en 89 idiomas. Sin embargo, estos vectores son monolingües; lo que significa que si bien las palabras similares dentro de un idioma comparten vectores similares, las palabras de traducción de diferentes idiomas no tienen vectores similares. En un artículo reciente en ICLR 2017, mostramos cómo se puede usar el SVD para aprender una transformación lineal (una matriz), que alinea los vectores monolingües de dos idiomas en un solo espacio de vectores. En este repositorio proporcionamos 78 matrices, que pueden usarse para alinear la mayoría de los idiomas de FastText en un solo espacio.
Este lectura explica cómo se deben usar las matrices. También presentamos una tarea de evaluación simple, donde mostramos que podemos predecir con éxito las traducciones de palabras en múltiples idiomas. Nuestro procedimiento se basa en recopilar diccionarios de capacitación bilingües de pares de palabras en dos idiomas, ¡pero notablemente podemos predecir con éxito las traducciones de palabras entre pares de idiomas para los cuales no teníamos un diccionario de entrenamiento!
Los incrustaciones de palabras definen la similitud entre dos palabras por el producto interno normalizado de sus vectores. Las matrices en este repositorio colocan lenguajes en un solo espacio, sin cambiar ninguna de estas relaciones de similitud monolingüe . Cuando usa los vectores multilingües resultantes para tareas monolingües, funcionarán exactamente lo mismo que los vectores originales. Para obtener más información sobre los incrustaciones de Word, consulte el blog de Colah o la introducción de Sam a las representaciones vectoriales.
Tenga en cuenta que desde que lanzamos este repositorio Facebook ha lanzado 204 idiomas adicionales; Sin embargo, las palabras vectores de los 90 idiomas originales no han cambiado, y las transformaciones proporcionadas en este repositorio seguirán funcionando. Si desea aprender sus propias matrices de alineación, proporcionamos un ejemplo en align_your_own.ipynb.
Si usa este repositorio, cite:
Vectores de palabras bilingües fuera de línea, transformaciones ortogonales y el softmax invertido
Samuel L. Smith, David HP Turban, Steven Hamblin y Nils Y. Hammerla
ICLR 2017 (pista de conferencia)
Clone una copia local de este repositorio y descargue los vectores FastText que necesita desde aquí. Voy a suponer que has descargado los vectores para francés y ruso en el formato de texto. Digamos que queremos comparar la similitud de "chat" y "кот". Cargamos la palabra vectores:
from fasttext import FastVector
fr_dictionary = FastVector ( vector_file = 'wiki.fr.vec' )
ru_dictionary = FastVector ( vector_file = 'wiki.ru.vec' )Podemos extraer la palabra vectores y calcular su similitud de coseno:
fr_vector = fr_dictionary [ "chat" ]
ru_vector = ru_dictionary [ "кот" ]
print ( FastVector . cosine_similarity ( fr_vector , ru_vector ))
# Result should be 0.02La similitud cosena se extiende entre -1 y 1. Parece que "chat" y "кот" no son similares ni diferentes. Pero ahora aplicamos las transformaciones para alinear los dos diccionarios en un solo espacio:
fr_dictionary . apply_transform ( 'alignment_matrices/fr.txt' )
ru_dictionary . apply_transform ( 'alignment_matrices/ru.txt' )Y reevaluar la similitud de coseno:
print ( FastVector . cosine_similarity ( fr_dictionary [ "chat" ], ru_dictionary [ "кот" ]))
# Result should be 0.43Resulta que "Chat" y "кот" son bastante similares después de todo. Esto es bueno, ya que ambos significan "gato".
De los 89 idiomas proporcionados por Facebook, 78 son compatibles con la API de Google Translate. Primero obtuvimos las 10,000 palabras más comunes en el vocabulario de ajuste fast -texto inglés, y luego usamos la API para traducir estas palabras en los 78 idiomas disponibles. Dividimos este vocabulario en dos, asignando las primeras 5000 palabras al diccionario de entrenamiento y el segundo 5000 al diccionario de prueba.
Describimos el procedimiento de alineación en este blog. Se necesitan dos conjuntos de vectores de palabras y un pequeño diccionario bilingüe de pares de traducción en dos idiomas; y genera una matriz que alinea el lenguaje de origen con el objetivo. A veces, Google traduce una palabra en inglés a una frase no inglesa, en estos casos promediamos la palabra vectores contenidos en la frase.
Para colocar los 78 idiomas en un solo espacio, alineamos cada idioma con los vectores ingleses (la matriz inglesa es la identidad).
Para demostrar que el procedimiento funciona, podemos predecir las traducciones de palabras que no se ven en el diccionario de entrenamiento. Por simplicidad predecimos las traducciones de los vecinos más cercanos. Entonces, por ejemplo, si quisiéramos traducir "perro" al sueco, simplemente encontraríamos el vector de palabras sueco cuya similitud coseno con el vector de palabras "perro" es el más alto.
Lo primero es lo primero, probemos el rendimiento de la traducción del inglés al cualquier otro idioma. Para cada par de idiomas, extraemos un conjunto de 2500 pares de palabras del diccionario de prueba. La precisión @n denota la probabilidad de que, de las 2500 palabras objetivo en este conjunto, la verdadera traducción fue uno de los n vecinos más cercanos de la palabra fuente. Si la alineación fuera completamente aleatoria, esperaríamos que la precisión @1 sea alrededor de 0.0004.
| Lengua de llegada | Precisión @1 | Precisión @5 | Precisión @10 |
|---|---|---|---|
| fría | 0.73 | 0.86 | 0.88 |
| PT | 0.73 | 0.86 | 0.89 |
| cepalle | 0.72 | 0.85 | 0.88 |
| él | 0.70 | 0.86 | 0.89 |
| nl | 0.68 | 0.83 | 0.86 |
| No | 0.68 | 0.85 | 0.89 |
| cañón | 0.66 | 0.84 | 0.88 |
| California | 0.66 | 0.81 | 0.86 |
| SV | 0.65 | 0.82 | 0.86 |
| CS | 0.64 | 0.81 | 0.85 |
| RO | 0.63 | 0.81 | 0.85 |
| Delaware | 0.62 | 0.75 | 0.78 |
| por favor | 0.62 | 0.79 | 0.83 |
| Hu | 0.61 | 0.80 | 0.84 |
| FI | 0.61 | 0.80 | 0.84 |
| EO | 0.61 | 0.80 | 0.85 |
| freno | 0.60 | 0.78 | 0.82 |
| GL | 0.60 | 0.77 | 0.82 |
| mk | 0.58 | 0.79 | 0.84 |
| identificación | 0.58 | 0.81 | 0.86 |
| BG | 0.57 | 0.77 | 0.82 |
| EM | 0.57 | 0.81 | 0.86 |
| Reino Unido | 0.57 | 0.75 | 0.79 |
| mierda | 0.56 | 0.77 | 0.81 |
| hora | 0.56 | 0.75 | 0.80 |
| TR | 0.56 | 0.77 | 0.81 |
| SLE | 0.56 | 0.77 | 0.82 |
| El | 0.54 | 0.75 | 0.80 |
| sk | 0.54 | 0.75 | 0.81 |
| en | 0.53 | 0.73 | 0.78 |
| sr | 0.53 | 0.72 | 0.77 |
| AF | 0.52 | 0.75 | 0.80 |
| teniente | 0.50 | 0.72 | 0.79 |
| Arkansas | 0.48 | 0.69 | 0.75 |
| bs | 0.47 | 0.70 | 0.77 |
| lv | 0.47 | 0.68 | 0.75 |
| UE | 0.46 | 0.68 | 0.75 |
| fa | 0.45 | 0.68 | 0.75 |
| hy | 0.43 | 0.66 | 0.73 |
| sq | 0.43 | 0.65 | 0.71 |
| ser | 0.43 | 0.64 | 0.70 |
| zh | 0.40 | 0.68 | 0.75 |
| ka | 0.40 | 0.63 | 0.71 |
| cy | 0.39 | 0.63 | 0.71 |
| Hola | 0.39 | 0.58 | 0.63 |
| Arizona | 0.38 | 0.60 | 0.67 |
| KO | 0.37 | 0.58 | 0.66 |
| TE | 0.36 | 0.56 | 0.63 |
| kk | 0.35 | 0.60 | 0.68 |
| él | 0.33 | 0.45 | 0.48 |
| insulto | 0.33 | 0.52 | 0.60 |
| VI | 0.31 | 0.53 | 0.62 |
| ejército de reserva | 0.31 | 0.50 | 0.56 |
| bn | 0.30 | 0.49 | 0.56 |
| tu | 0.29 | 0.52 | 0.61 |
| es | 0.29 | 0.51 | 0.59 |
| TL | 0.28 | 0.51 | 0.59 |
| Kn | 0.28 | 0.43 | 0.46 |
| Gu | 0.25 | 0.44 | 0.51 |
| Minnesota | 0.25 | 0.49 | 0.58 |
| Uz | 0.24 | 0.43 | 0.51 |
| si | 0.22 | 0.40 | 0.45 |
| ml | 0.21 | 0.35 | 0.39 |
| Kentucky | 0.20 | 0.40 | 0.49 |
| señor | 0.20 | 0.37 | 0.44 |
| th | 0.20 | 0.33 | 0.38 |
| la | 0.19 | 0.34 | 0.42 |
| ja | 0.18 | 0.44 | 0.56 |
| nordeste | 0.16 | 0.33 | 0.38 |
| Pensilvania | 0.16 | 0.32 | 0.38 |
| tg | 0.14 | 0.31 | 0.39 |
| km | 0.12 | 0.26 | 0.30 |
| mi | 0.10 | 0.19 | 0.23 |
| lb | 0.09 | 0.18 | 0.21 |
| mg | 0.07 | 0.18 | 0.25 |
| CEB | 0.06 | 0.13 | 0.18 |
Como puede ver, ¡la alineación es consistentemente mucho mejor que al azar! En general, el procedimiento funciona mejor para otros idiomas europeos como francés, portugués y español. Usamos 2500 pares de palabras, debido a las 5000 palabras en el diccionario de prueba, no todas las palabras que se encuentran en Google Translate API están realmente presentes en el vocabulario FastText.
Ahora hagamos algo mucho más emocionante, evaluemos el rendimiento de la traducción entre todos los pares de idiomas posibles. Exhibimos este rendimiento de traducción en el mapa de calor a continuación, donde el color de un elemento denota la precisión @1 cuando se traduce desde el idioma de la fila al idioma de la columna.
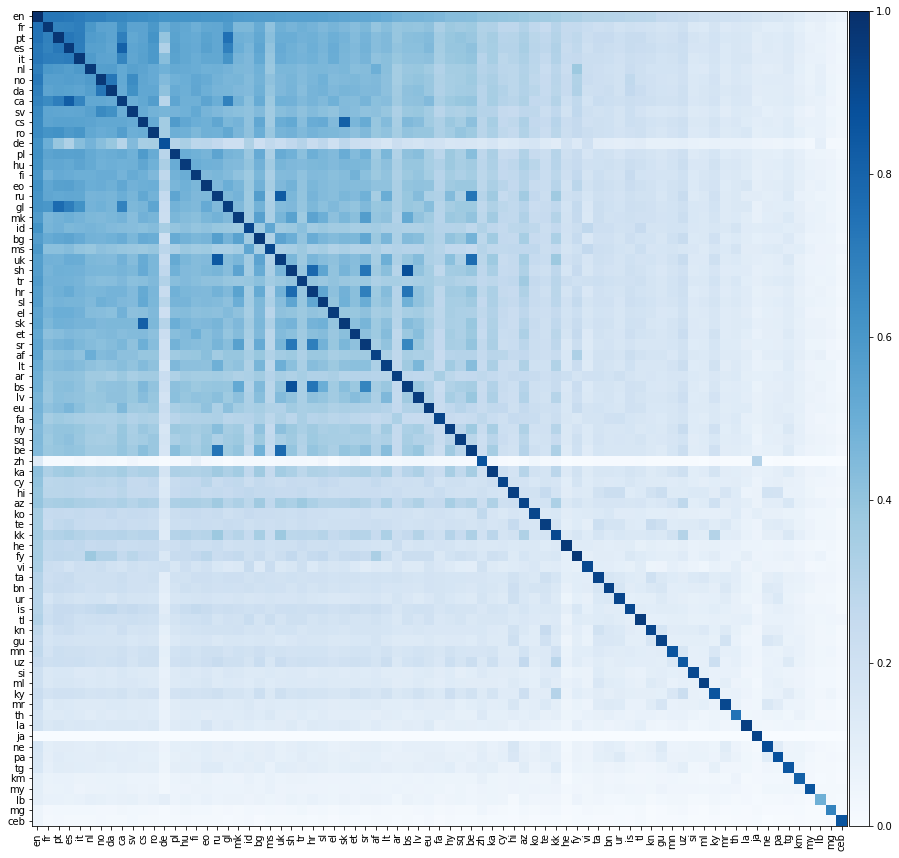
Debemos enfatizar que todos los idiomas estaban alineados solo con el inglés . No proporcionamos diccionarios de capacitación entre pares de idiomas que no son ingleses. Sin embargo, todavía somos capaces de predecir con éxito traducciones entre pares de idiomas que no son de inglés notablemente con precisión.
Esperamos que los elementos diagonales de la matriz anterior sean 1, ya que un idioma debería traducirse perfectamente para sí mismo. Sin embargo, en la práctica, esto no siempre ocurre, porque construimos los diccionarios de capacitación y prueba traduciendo palabras comunes en inglés a los otros idiomas. A veces, varias palabras en inglés se traducen en la misma palabra no inglesa, por lo que la misma palabra que no es inglés puede aparecer varias veces en el conjunto de pruebas. No hemos contabilizado correctamente esto, lo que reduce el rendimiento de la traducción.
Intriquetamente, a pesar de que solo alineamos directamente los idiomas al inglés, ¡a veces un idioma se traduce mejor a otro idioma no inglés que al inglés! Podemos calcular la precisión entre pares de dos idiomas; La precisión promedio del lenguaje 1 al idioma 2 y viceversa. También podemos calcular la precisión del par de inglés; El promedio de la precisión del inglés al idioma 1 y del inglés al idioma 2. A continuación enumeramos todos los pares de idiomas para los cuales la precisión entre pares excede la precisión del par de inglés:
| Idioma 1 | Idioma 2 | Precisión entre pares @1 | Precisión de par de inglés @1 |
|---|---|---|---|
| bs | mierda | 0.88 | 0.52 |
| freno | Reino Unido | 0.84 | 0.58 |
| California | cepalle | 0.82 | 0.69 |
| CS | sk | 0.82 | 0.59 |
| hora | mierda | 0.78 | 0.56 |
| ser | Reino Unido | 0.77 | 0.50 |
| GL | PT | 0.76 | 0.66 |
| bs | hora | 0.74 | 0.52 |
| ser | freno | 0.73 | 0.51 |
| cañón | No | 0.73 | 0.67 |
| sr | mierda | 0.73 | 0.54 |
| PT | cepalle | 0.72 | 0.72 |
| California | PT | 0.70 | 0.69 |
| GL | cepalle | 0.70 | 0.66 |
| hora | sr | 0.69 | 0.54 |
| California | GL | 0.68 | 0.63 |
| bs | sr | 0.67 | 0.50 |
| mk | sr | 0.56 | 0.55 |
| kk | Kentucky | 0.30 | 0.28 |
Todos estos pares de idiomas comparten raíces lingüísticas muy cercanas. Por ejemplo, el primer par anterior es bosnio y serboatiano; Bosnian es una variante de serboatiano. El segundo par es ruso y ucraniano; Ambos idiomas del este-eslavos. Parece que cuanto más similares son dos idiomas, más similares la geometría de sus vectores FastText; conduciendo a un mejor rendimiento de la traducción.
Las matrices proporcionadas en este repositorio son ortogonales. Intuitivamente, cada matriz se puede descomponer en una serie de rotaciones y reflexiones. Las rotaciones y las reflexiones no cambian la distancia entre dos puntos en un espacio vectorial; y, en consecuencia, ninguno de los productos internos entre los vectores de palabras dentro de un idioma se cambia, solo se ven afectados los productos internos entre las palabras vectores de diferentes idiomas.
Hay varios artículos excelentes sobre este tema. Hemos enumerado algunos de ellos a continuación:
Varios lectores han expresado interés en los diccionarios de capacitación y prueba que utilizamos en este repositorio. Sin embargo, nos hubiera gustado cargarlos, si bien no hemos recibido asesoramiento legal, nos preocupa que esto pueda interpretarse como rompiendo los términos de la API de traducción de Google.
Las matrices de transformación se distribuyen bajo la Licencia de Attributación de Commons Creative Commons 3.0 .


