fastText_multilingual
1.0.0
请注意,该存储库不再由Babylon Health积极维护。为了进一步的帮助,请与纸质作者联系。
Facebook最近以89种语言开源的单词向量。但是这些矢量是单语的。这意味着,尽管一种语言中的类似单词共享相似的向量,但来自不同语言的翻译单词没有相似的向量。在ICLR 2017上最近的一篇论文中,我们展示了如何使用SVD来学习线性转换(矩阵),该线性转换(矩阵)与单个向量空间中的两种语言相一致。在此存储库中,我们提供了78个矩阵,可以用来对齐单个空间中的大多数FastText语言。
此读书我解释了应如何使用矩阵。我们还提出了一个简单的评估任务,我们表明我们能够成功预测多种语言的单词翻译。我们的程序依赖于用两种语言收集单语言培训字典,但是非常明显的是,我们能够成功预测我们没有培训词典的语言对之间的单词翻译!
单词嵌入通过其向量的标准化内部产物来定义两个单词之间的相似性。此存储库中语言中的矩阵在一个空间中,而没有更改这些单语的任何相似性关系。当您将结果多语言向量用于单语任务时,它们的性能与原始向量完全相同。要了解有关单词嵌入的更多信息,请查看Colah的博客或Sam对向量表示的介绍。
请注意,自从我们发布此存储库以来,Facebook已发布了另外204种语言;但是,原始90种语言的矢量词没有更改,并且该存储库中提供的转换仍然可以正常工作。如果您想学习自己的对齐矩阵,我们将在align_your_own.ipynb中提供一个示例。
如果您使用此存储库,请引用:
离线双语词向量,正交转换和倒置的软词
塞缪尔·史密斯(Samuel L.
ICLR 2017(会议轨道)
克隆此存储库的本地副本,然后从这里下载您需要的FastText Vectors。我将假设您以文本格式下载了法语和俄语的向量。假设我们想比较“聊天”和“自志”的相似性。我们加载vectors一词:
from fasttext import FastVector
fr_dictionary = FastVector ( vector_file = 'wiki.fr.vec' )
ru_dictionary = FastVector ( vector_file = 'wiki.ru.vec' )我们可以提取矢量一词并计算它们的余弦相似性:
fr_vector = fr_dictionary [ "chat" ]
ru_vector = ru_dictionary [ "кот" ]
print ( FastVector . cosine_similarity ( fr_vector , ru_vector ))
# Result should be 0.02余弦相似性在-1到1之间。似乎“聊天”和“自志”既不相似也不相似。但是现在,我们将转换应用于一个空间中的两个词典:
fr_dictionary . apply_transform ( 'alignment_matrices/fr.txt' )
ru_dictionary . apply_transform ( 'alignment_matrices/ru.txt' )并重新评估余弦的相似性:
print ( FastVector . cosine_similarity ( fr_dictionary [ "chat" ], ru_dictionary [ "кот" ]))
# Result should be 0.43事实证明,“聊天”和“见人”毕竟非常相似。这很好,因为它们都表示“猫”。
在Facebook提供的89种语言中,有78种由Google Translate API支持。我们首先在英语FastText词汇中获得了10,000个最常见的单词,然后使用API将这些单词翻译成78种可用的语言。我们将此词汇分为两分,将前5000个单词分配给训练词典,第二个5000个单词分配给了测试词典。
我们在此博客中描述了对齐过程。它需要两种单词向量和两种语言的翻译对的小型双语词典。并生成一个矩阵,该矩阵将源语言与目标保持一致。有时,Google会将英语单词翻译成非英语短语,在这些情况下,我们平均该短语中包含的vectors一词。
要将所有78种语言都放在一个空间中,我们将每种语言与英语向量保持一致(英语矩阵是身份)。
为了证明该过程有效,我们可以预测训练词典中未看到的单词的翻译。为简单起见,我们预测最近邻居的翻译。因此,例如,如果我们想将“狗”翻译成瑞典语,我们会发现瑞典语向量与“狗”词向量相似的瑞典语向量最高。
首先,让我们测试从英语到其他所有语言的翻译性能。对于每个语言对,我们从测试词典中提取一组2500个单词对。精度@n表示,在该集合中的2500个目标单词中,真实翻译是源单词最接近的邻居之一。如果对齐完全随机,我们希望Precision @1约为0.0004。
| 目标语言 | Precision @1 | Precision @5 | Precision @10 |
|---|---|---|---|
| fr | 0.73 | 0.86 | 0.88 |
| pt | 0.73 | 0.86 | 0.89 |
| es | 0.72 | 0.85 | 0.88 |
| 它 | 0.70 | 0.86 | 0.89 |
| NL | 0.68 | 0.83 | 0.86 |
| 不 | 0.68 | 0.85 | 0.89 |
| da | 0.66 | 0.84 | 0.88 |
| CA | 0.66 | 0.81 | 0.86 |
| SV | 0.65 | 0.82 | 0.86 |
| CS | 0.64 | 0.81 | 0.85 |
| ro | 0.63 | 0.81 | 0.85 |
| de | 0.62 | 0.75 | 0.78 |
| pl | 0.62 | 0.79 | 0.83 |
| 胡 | 0.61 | 0.80 | 0.84 |
| fi | 0.61 | 0.80 | 0.84 |
| EO | 0.61 | 0.80 | 0.85 |
| ru | 0.60 | 0.78 | 0.82 |
| GL | 0.60 | 0.77 | 0.82 |
| MK | 0.58 | 0.79 | 0.84 |
| ID | 0.58 | 0.81 | 0.86 |
| BG | 0.57 | 0.77 | 0.82 |
| 多发性硬化症 | 0.57 | 0.81 | 0.86 |
| 英国 | 0.57 | 0.75 | 0.79 |
| sh | 0.56 | 0.77 | 0.81 |
| 人力资源 | 0.56 | 0.75 | 0.80 |
| tr | 0.56 | 0.77 | 0.81 |
| SL | 0.56 | 0.77 | 0.82 |
| El | 0.54 | 0.75 | 0.80 |
| SK | 0.54 | 0.75 | 0.81 |
| 等 | 0.53 | 0.73 | 0.78 |
| Sr | 0.53 | 0.72 | 0.77 |
| AF | 0.52 | 0.75 | 0.80 |
| 上尉 | 0.50 | 0.72 | 0.79 |
| ar | 0.48 | 0.69 | 0.75 |
| BS | 0.47 | 0.70 | 0.77 |
| LV | 0.47 | 0.68 | 0.75 |
| 欧盟 | 0.46 | 0.68 | 0.75 |
| fa | 0.45 | 0.68 | 0.75 |
| hy | 0.43 | 0.66 | 0.73 |
| 平方英尺 | 0.43 | 0.65 | 0.71 |
| 是 | 0.43 | 0.64 | 0.70 |
| ZH | 0.40 | 0.68 | 0.75 |
| ka | 0.40 | 0.63 | 0.71 |
| CY | 0.39 | 0.63 | 0.71 |
| 你好 | 0.39 | 0.58 | 0.63 |
| AZ | 0.38 | 0.60 | 0.67 |
| ko | 0.37 | 0.58 | 0.66 |
| TE | 0.36 | 0.56 | 0.63 |
| KK | 0.35 | 0.60 | 0.68 |
| 他 | 0.33 | 0.45 | 0.48 |
| FY | 0.33 | 0.52 | 0.60 |
| vi | 0.31 | 0.53 | 0.62 |
| ta | 0.31 | 0.50 | 0.56 |
| BN | 0.30 | 0.49 | 0.56 |
| ur | 0.29 | 0.52 | 0.61 |
| 是 | 0.29 | 0.51 | 0.59 |
| TL | 0.28 | 0.51 | 0.59 |
| kn | 0.28 | 0.43 | 0.46 |
| 古 | 0.25 | 0.44 | 0.51 |
| Mn | 0.25 | 0.49 | 0.58 |
| uz | 0.24 | 0.43 | 0.51 |
| SI | 0.22 | 0.40 | 0.45 |
| ML | 0.21 | 0.35 | 0.39 |
| 肯 | 0.20 | 0.40 | 0.49 |
| 先生 | 0.20 | 0.37 | 0.44 |
| Th | 0.20 | 0.33 | 0.38 |
| 洛杉矶 | 0.19 | 0.34 | 0.42 |
| JA | 0.18 | 0.44 | 0.56 |
| NE | 0.16 | 0.33 | 0.38 |
| PA | 0.16 | 0.32 | 0.38 |
| TG | 0.14 | 0.31 | 0.39 |
| 公里 | 0.12 | 0.26 | 0.30 |
| 我的 | 0.10 | 0.19 | 0.23 |
| 磅 | 0.09 | 0.18 | 0.21 |
| 毫克 | 0.07 | 0.18 | 0.25 |
| CEB | 0.06 | 0.13 | 0.18 |
如您所见,对齐比随机好得多!通常,该程序最适合其他欧洲语言,例如法语,葡萄牙语和西班牙语。我们使用2500个单词对,因为测试字典中有5000个单词,并非Google翻译API实际上都存在于FastText词汇中。
现在,让我们做一些更令人兴奋的事情,让我们评估所有可能的语言对之间的翻译性能。我们在下面的热图上展示了这种翻译性能,其中元素的颜色表示precision @1当从行语言翻译成列的语言时。
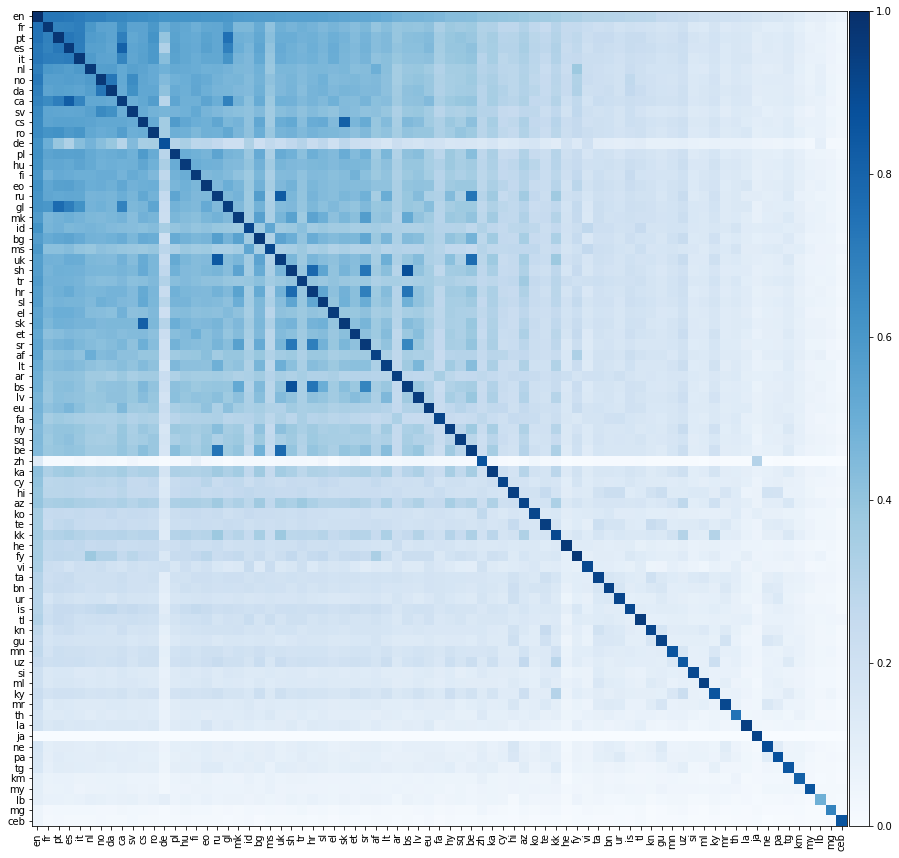
我们应该强调的是,所有语言都仅与英语保持一致。我们没有在非英语语言对之间提供培训词典。然而,我们仍然能够非常准确地对非英语语言对之间的翻译进行成功。
我们希望上面的矩阵的对角线元素是1,因为一种语言应该完美地转化为自身。但是,实际上,这并不总是发生,因为我们通过将常见的英语单词翻译成其他语言来构建培训和测试词典。有时,多个英语单词转化为相同的非英语单词,因此在测试集中可能会多次出现相同的非英语单词。我们尚未正确考虑这一点,从而降低了翻译性能。
刻薄的是,即使我们只是将语言直接与英语保持一致,有时一种语言比英语更像是另一种非英语语言!我们可以计算两种语言的配对精度;从语言1到语言2的平均精度,反之亦然。我们还可以计算英语对精度;从英语到语言1以及英语到语言2的精确度的平均值。在下面,我们列出了对层间精度的所有语言对超过英语对的精度:
| 语言1 | 语言2 | 配对精度 @1 | 英语对精度 @1 |
|---|---|---|---|
| BS | sh | 0.88 | 0.52 |
| ru | 英国 | 0.84 | 0.58 |
| CA | es | 0.82 | 0.69 |
| CS | SK | 0.82 | 0.59 |
| 人力资源 | sh | 0.78 | 0.56 |
| 是 | 英国 | 0.77 | 0.50 |
| GL | pt | 0.76 | 0.66 |
| BS | 人力资源 | 0.74 | 0.52 |
| 是 | ru | 0.73 | 0.51 |
| da | 不 | 0.73 | 0.67 |
| Sr | sh | 0.73 | 0.54 |
| pt | es | 0.72 | 0.72 |
| CA | pt | 0.70 | 0.69 |
| GL | es | 0.70 | 0.66 |
| 人力资源 | Sr | 0.69 | 0.54 |
| CA | GL | 0.68 | 0.63 |
| BS | Sr | 0.67 | 0.50 |
| MK | Sr | 0.56 | 0.55 |
| KK | 肯 | 0.30 | 0.28 |
所有这些语言对具有非常紧密的语言根源。例如,上面的第一对是波斯尼亚人和塞尔伯 - 克罗地亚人;波斯尼亚是塞尔博 - 克罗地亚人的变体。第二对是俄罗斯和乌克兰人。两种东拉语言。看来两种语言越相似,它们的fastText载体的几何形状越相似。导致改进的翻译性能。
此存储库中提供的矩阵是正交的。直观地,每个矩阵可以分解为一系列旋转和反射。旋转和反射不会改变向量空间中任意两个点之间的距离;因此,语言中单词向量之间的内在产品没有改变,只有不同语言的矢量之间的内部产品受到影响。
关于这个主题有许多很棒的论文。我们在下面列出了其中的一些:
许多读者对我们在此存储库中使用的培训和测试词典表示了兴趣。我们本来希望上传这些,但是,尽管我们没有采取法律建议,但我们担心这可以解释为打破Google Translate API的条款。
转换矩阵分布在Creative Commons归因与共享许可证3.0下。


