fastText_multilingual
1.0.0
このリポジトリは、バビロンヘルスによって積極的に維持されなくなったことに注意してください。さらなる支援のために、紙の著者に連絡してください。
Facebookは最近、89の言語でオープンソースのワードベクトルをオープンしました。ただし、これらのベクトルは単一言語です。言語内の同様の単語は同様のベクトルを共有しているが、異なる言語からの翻訳語には同様のベクトルがないことを意味します。 ICLR 2017の最近の論文では、SVDを使用して線形変換(マトリックス)を学習する方法を示しました。これは、単一のベクトル空間の2つの言語から単一言語のベクトルを揃えます。このリポジトリでは、78のマトリックスを提供します。これを使用して、単一のスペースでFastText言語の大部分を整列させることができます。
このREADMEは、マトリックスの使用方法を説明しています。また、単純な評価タスクも提示します。ここでは、複数の言語での単語の翻訳を正常に予測できることが示されています。私たちの手順は、2つの言語で単語ペアのバイリンガルトレーニング辞書の収集に依存していますが、驚くべきことに、トレーニング辞書がない言語ペア間の単語の翻訳をうまく予測することができます。
単語埋め込みは、ベクトルの正規化された内積によって2つの単語間の類似性を定義します。このリポジトリのマトリックスは、これらの単一言語の類似性の関係を変更することなく、単一のスペースに言語を配置します。結果の多言語ベクトルを単一言語タスクに使用する場合、それらは元のベクトルとまったく同じように実行されます。 Word Embeddingsの詳細については、ColahのブログまたはSamのベクトル表現の紹介をご覧ください。
このリポジトリFacebookがリリースされて以来、さらに204の言語をリリースしたことに注意してください。ただし、元の90言語の単語ベクトルは変更されておらず、このリポジトリで提供される変換は引き続き機能します。独自のアライメントマトリックスを学びたい場合は、align_your_own.ipynbで例を示します。
このリポジトリを使用する場合は、引用してください。
オフラインのバイリンガルワードベクトル、直交変換、逆のソフトマックス
サミュエルL.スミス、デビッドHPターバン、スティーブンハンブリン、ニルスY.ハンメーラ
ICLR 2017(会議トラック)
このリポジトリのローカルコピーをクローンし、ここから必要なFastTextベクターをダウンロードします。フランス語とロシア語のベクトルをテキスト形式でダウンロードしたと仮定します。 「チャット」と「賛美」の類似性を比較したいとしましょう。ベクトルという単語をロードします。
from fasttext import FastVector
fr_dictionary = FastVector ( vector_file = 'wiki.fr.vec' )
ru_dictionary = FastVector ( vector_file = 'wiki.ru.vec' )ベクトルという単語を抽出し、それらのコサインの類似性を計算できます。
fr_vector = fr_dictionary [ "chat" ]
ru_vector = ru_dictionary [ "кот" ]
print ( FastVector . cosine_similarity ( fr_vector , ru_vector ))
# Result should be 0.02コサインの類似性は-1〜1の間で実行されます。「チャット」と「謝人」は類似していないようです。しかし、次に、変換を適用して、2つの辞書を単一のスペースに揃えます。
fr_dictionary . apply_transform ( 'alignment_matrices/fr.txt' )
ru_dictionary . apply_transform ( 'alignment_matrices/ru.txt' )コサインの類似性を再評価します。
print ( FastVector . cosine_similarity ( fr_dictionary [ "chat" ], ru_dictionary [ "кот" ]))
# Result should be 0.43結局のところ、「チャット」と「賛美」はかなり似ています。どちらも「猫」を意味するので、これは良いことです。
Facebookが提供する89の言語のうち、78はGoogle Translate APIによってサポートされています。最初に英語の高速テキスト語彙で10,000の最も一般的な単語を取得し、APIを使用してこれらの単語を利用可能な78の言語に変換します。この語彙を2つに分割し、最初の5000語をトレーニング辞書に割り当て、2番目の5000語をテスト辞書に割り当てました。
このブログで調整手順について説明しました。 2つの言語で2セットの単語ベクトルと翻訳ペアの小さなバイリンガル辞書が必要です。ソース言語をターゲットに合わせるマトリックスを生成します。 Googleは英語の単語を英語以外のフレーズに翻訳することがあります。これらの場合、フレーズに含まれる単語ベクトルを平均します。
78の言語すべてを単一のスペースに配置するために、すべての言語を英語のベクトルに揃えます(英語のマトリックスはアイデンティティです)。
手順が機能することを証明するために、トレーニング辞書には見られない単語の翻訳を予測できます。簡単にするために、最近の隣人による翻訳を予測します。たとえば、「犬」をスウェーデン語に翻訳したい場合は、「犬」という単語ベクトルとコサインの類似性が最も高いスウェーデン語のベクトルを見つけるだけです。
まず最初に、翻訳パフォーマンスを英語から他のすべての言語にテストしましょう。各言語ペアについて、テスト辞書から2500ワードのペアのセットを抽出します。精密@Nは、このセットの2500のターゲットワードのうち、真の翻訳がソースワードの最近の最近隣接の1つである可能性を示します。アライメントが完全にランダムである場合、精度 @1は約0.0004になると予想されます。
| ターゲット言語 | 精度 @1 | 精度 @5 | 精度 @10 |
|---|---|---|---|
| fr | 0.73 | 0.86 | 0.88 |
| pt | 0.73 | 0.86 | 0.89 |
| es | 0.72 | 0.85 | 0.88 |
| それ | 0.70 | 0.86 | 0.89 |
| NL | 0.68 | 0.83 | 0.86 |
| いいえ | 0.68 | 0.85 | 0.89 |
| da | 0.66 | 0.84 | 0.88 |
| ca | 0.66 | 0.81 | 0.86 |
| SV | 0.65 | 0.82 | 0.86 |
| CS | 0.64 | 0.81 | 0.85 |
| ro | 0.63 | 0.81 | 0.85 |
| de | 0.62 | 0.75 | 0.78 |
| pl | 0.62 | 0.79 | 0.83 |
| 胡 | 0.61 | 0.80 | 0.84 |
| fi | 0.61 | 0.80 | 0.84 |
| EO | 0.61 | 0.80 | 0.85 |
| ru | 0.60 | 0.78 | 0.82 |
| GL | 0.60 | 0.77 | 0.82 |
| MK | 0.58 | 0.79 | 0.84 |
| id | 0.58 | 0.81 | 0.86 |
| BG | 0.57 | 0.77 | 0.82 |
| MS | 0.57 | 0.81 | 0.86 |
| 英国 | 0.57 | 0.75 | 0.79 |
| sh | 0.56 | 0.77 | 0.81 |
| HR | 0.56 | 0.75 | 0.80 |
| tr | 0.56 | 0.77 | 0.81 |
| Sl | 0.56 | 0.77 | 0.82 |
| エル | 0.54 | 0.75 | 0.80 |
| SK | 0.54 | 0.75 | 0.81 |
| et | 0.53 | 0.73 | 0.78 |
| sr | 0.53 | 0.72 | 0.77 |
| af | 0.52 | 0.75 | 0.80 |
| lt | 0.50 | 0.72 | 0.79 |
| ar | 0.48 | 0.69 | 0.75 |
| BS | 0.47 | 0.70 | 0.77 |
| lv | 0.47 | 0.68 | 0.75 |
| 欧州連合 | 0.46 | 0.68 | 0.75 |
| FA | 0.45 | 0.68 | 0.75 |
| hy | 0.43 | 0.66 | 0.73 |
| sq | 0.43 | 0.65 | 0.71 |
| なれ | 0.43 | 0.64 | 0.70 |
| Zh | 0.40 | 0.68 | 0.75 |
| KA | 0.40 | 0.63 | 0.71 |
| cy | 0.39 | 0.63 | 0.71 |
| こんにちは | 0.39 | 0.58 | 0.63 |
| AZ | 0.38 | 0.60 | 0.67 |
| KO | 0.37 | 0.58 | 0.66 |
| te | 0.36 | 0.56 | 0.63 |
| KK | 0.35 | 0.60 | 0.68 |
| 彼 | 0.33 | 0.45 | 0.48 |
| FY | 0.33 | 0.52 | 0.60 |
| vi | 0.31 | 0.53 | 0.62 |
| ta | 0.31 | 0.50 | 0.56 |
| bn | 0.30 | 0.49 | 0.56 |
| ウル | 0.29 | 0.52 | 0.61 |
| は | 0.29 | 0.51 | 0.59 |
| TL | 0.28 | 0.51 | 0.59 |
| kn | 0.28 | 0.43 | 0.46 |
| gu | 0.25 | 0.44 | 0.51 |
| Mn | 0.25 | 0.49 | 0.58 |
| uz | 0.24 | 0.43 | 0.51 |
| si | 0.22 | 0.40 | 0.45 |
| ml | 0.21 | 0.35 | 0.39 |
| ky | 0.20 | 0.40 | 0.49 |
| 氏 | 0.20 | 0.37 | 0.44 |
| th | 0.20 | 0.33 | 0.38 |
| la | 0.19 | 0.34 | 0.42 |
| JA | 0.18 | 0.44 | 0.56 |
| ne | 0.16 | 0.33 | 0.38 |
| PA | 0.16 | 0.32 | 0.38 |
| TG | 0.14 | 0.31 | 0.39 |
| km | 0.12 | 0.26 | 0.30 |
| 私の | 0.10 | 0.19 | 0.23 |
| ポンド | 0.09 | 0.18 | 0.21 |
| mg | 0.07 | 0.18 | 0.25 |
| CEB | 0.06 | 0.13 | 0.18 |
ご覧のとおり、アラインメントは一貫してランダムよりもはるかに優れています!一般に、この手順は、フランス語、ポルトガル語、スペイン語などの他のヨーロッパ言語に最適です。テスト辞書の5000語のために2500ワードのペアを使用していますが、Google Translate APIで見つかったすべての単語が実際にFastTextの語彙に存在するわけではありません。
それでは、もっとエキサイティングなことをしましょう。すべての可能な言語ペア間の翻訳パフォーマンスを評価しましょう。下のヒートマップでこの翻訳パフォーマンスを示します。ここでは、要素の色は、行の言語から列の言語に翻訳するときに精度 @1を示します。
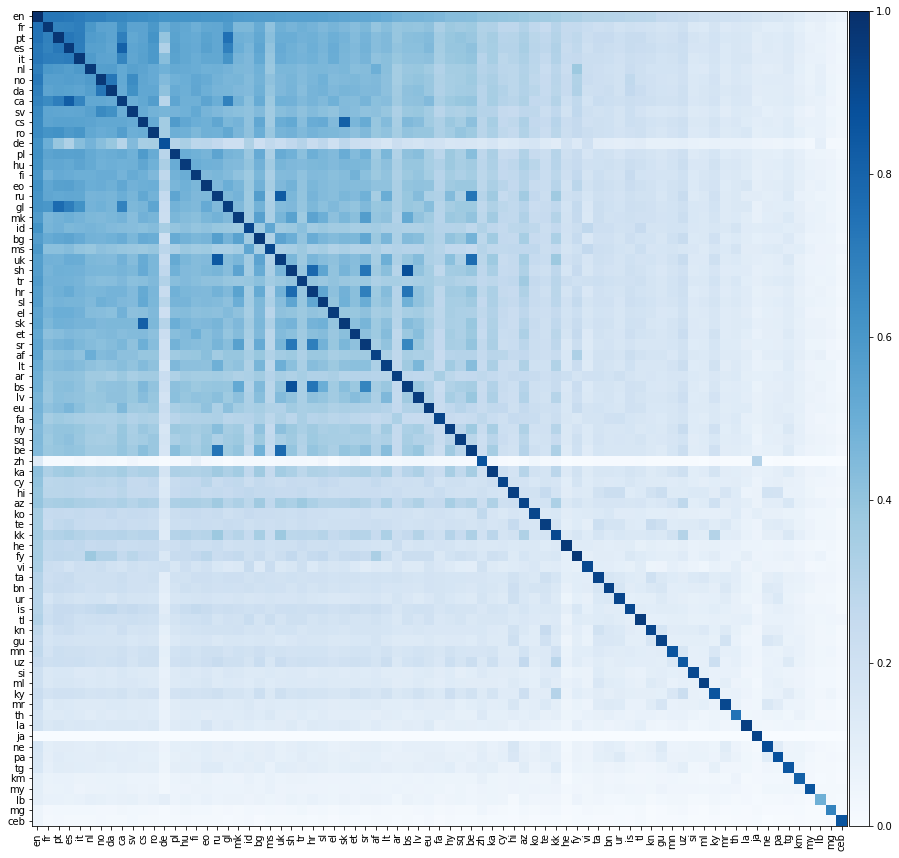
すべての言語は英語のみに整合していることを強調する必要があります。英語以外の言語のペア間でトレーニング辞書を提供しませんでした。しかし、私たちはまだ英語以外の言語のペア間の翻訳を著しく正確に予測することができます。
言語はそれ自体に完全に翻訳する必要があるため、上記のマトリックスの対角線要素は1になると予想しています。ただし、実際には、一般的な英語の単語を他の言語に変換することにより、トレーニングとテストの辞書を作成したため、これは常に発生するとは限りません。時々、複数の英語の単語が同じ非英語の単語に翻訳されるため、テストセットに同じ非英語の単語が複数回表示される場合があります。これを適切に考慮していないため、翻訳性能が低下します。
興味深いことに、言語を英語に直接並べただけでも、言語は英語よりも英語以外の言語に翻訳される場合があります。 2つの言語のペア間精度を計算できます。言語1から言語2への平均精度とその逆。また、英語のペアの精度を計算することもできます。英語から言語1、英語から言語への精度の平均2。
| 言語1 | 言語2 | ペア間精度 @1 | 英語ペアの精度 @1 |
|---|---|---|---|
| BS | sh | 0.88 | 0.52 |
| ru | 英国 | 0.84 | 0.58 |
| ca | es | 0.82 | 0.69 |
| CS | SK | 0.82 | 0.59 |
| HR | sh | 0.78 | 0.56 |
| なれ | 英国 | 0.77 | 0.50 |
| GL | pt | 0.76 | 0.66 |
| BS | HR | 0.74 | 0.52 |
| なれ | ru | 0.73 | 0.51 |
| da | いいえ | 0.73 | 0.67 |
| sr | sh | 0.73 | 0.54 |
| pt | es | 0.72 | 0.72 |
| ca | pt | 0.70 | 0.69 |
| GL | es | 0.70 | 0.66 |
| HR | sr | 0.69 | 0.54 |
| ca | GL | 0.68 | 0.63 |
| BS | sr | 0.67 | 0.50 |
| MK | sr | 0.56 | 0.55 |
| KK | ky | 0.30 | 0.28 |
これらの言語のペアはすべて、非常に近い言語の根を共有しています。たとえば、上記の最初のペアはボスニアとセルボクロアチア語です。ボスニア人はセルボクロアチア語のバリアントです。 2番目のペアはロシア語とウクライナ人です。両方の東スラヴ語。 2つの言語がより似ているほど、高速テキストベクトルのジオメトリが類似しているようです。翻訳性能の向上につながります。
このリポジトリで提供されるマトリックスは直交です。直感的に、各マトリックスは一連の回転と反射に分解できます。回転と反射は、ベクトル空間内の2つのポイント間の距離を変えません。その結果、言語内の単語ベクトル間の内部製品のいずれも変更されず、異なる言語の単語ベクトル間の内部製品のみが影響を受けます。
このトピックに関する素晴らしい論文がたくさんあります。それらのいくつかを以下にリストしました:
多くの読者が、このリポジトリで使用したトレーニングおよびテスト辞書に関心を示しています。ただし、これらをアップロードしたいと思っていましたが、法的アドバイスを受けていませんが、Google Translate APIの条件を破ると解釈できると心配しています。
変換マトリックスは、Creative Commons Attribution-Share-Alike License 3.0の下に配布されます。


