fastText_multilingual
1.0.0
Обратите внимание, что этот репозиторий больше не поддерживается Health Babylon. Для получения дополнительной помощи обратитесь к авторам бумаги.
Facebook недавно с открытыми векторами слов на 89 языках. Однако эти векторы одноязычные; Это означает, что, хотя похожие слова в языке имеют схожие векторы, переводные слова из разных языков не имеют похожих векторов. В недавней статье на ICLR 2017 мы показали, как SVD можно использовать для изучения линейного преобразования (матрица), которое выравнивает одноязычные векторы из двух языков в одном векторном пространстве. В этом репозитории мы предоставляем 78 матриц, которые можно использовать для выравнивания большинства языков быстрого текста в одном пространстве.
Этот Readme объясняет, как следует использовать матрицы. Мы также представляем простую задачу оценки, где мы показываем, что можем успешно предсказать переводы слов на нескольких языках. Наша процедура основана на сборе двуязычных учебных словарей пар слов на двух языках, но замечательно мы можем успешно предсказать переводы слов между языковыми парами, для которых у нас не было учебного словаря!
Вставки слова определяют сходство между двумя словами с помощью нормализованного внутреннего продукта их векторов. Матрицы в этом репозитории размещают языки в одном пространстве, не изменяя какое -либо из этих моноязычных отношений сходства . Когда вы используете полученные многоязычные векторы для одноязычных задач, они будут работать точно так же, как и оригинальные векторы. Чтобы узнать больше о вставках Word, ознакомьтесь с блогом Кола или «Введение Сэма в векторные представления».
Обратите внимание, что с тех пор, как мы выпустили этот репозиторий Facebook, выпустили дополнительные 204 языка; Однако слово векторы исходных 90 языков не изменилось, и преобразования, представленные в этом хранилище, все равно будут работать. Если вы хотите изучить свои собственные матрицы выравнивания, мы приведем пример в align_your_own.ipynb.
Если вы используете этот репозиторий, укажите:
Оффлайн двуязычные векторы слов, ортогональные преобразования и перевернутый Softmax
Сэмюэл Л. Смит, Дэвид Х.П. Турбан, Стивен Хэмблин и Нильс Й. Хаммерла
ICLR 2017 (трек конференции)
Клонируйте локальную копию этого хранилища и загрузите векторы Fasttext, которые вам нужны здесь. Я собираюсь предположить, что вы скачали векторы для французского и русского в текстовом формате. Допустим, мы хотим сравнить сходство «чата» и «кот». Мы загружаем слово векторы:
from fasttext import FastVector
fr_dictionary = FastVector ( vector_file = 'wiki.fr.vec' )
ru_dictionary = FastVector ( vector_file = 'wiki.ru.vec' )Мы можем извлечь слова векторов и рассчитать их сходство косинуса:
fr_vector = fr_dictionary [ "chat" ]
ru_vector = ru_dictionary [ "кот" ]
print ( FastVector . cosine_similarity ( fr_vector , ru_vector ))
# Result should be 0.02Сходство косинуса проходит между -1 и 1. Похоже, что «чат» и «кот» не являются ни похожими, ни разными. Но теперь мы применяем преобразования, чтобы выравнивать два словаря в одном пространстве:
fr_dictionary . apply_transform ( 'alignment_matrices/fr.txt' )
ru_dictionary . apply_transform ( 'alignment_matrices/ru.txt' )И переоценить сходство косинуса:
print ( FastVector . cosine_similarity ( fr_dictionary [ "chat" ], ru_dictionary [ "кот" ]))
# Result should be 0.43Оказывается, «чат» и «Кот» в конце концов очень похожи. Это хорошо, так как они оба означают «кошка».
Из 89 языков, предоставленных Facebook, 78 поддерживаются API Google Translate. Сначала мы получили 10 000 наиболее распространенных слов в английском словарном фонарике, а затем использовали API, чтобы перевести эти слова на 78 доступных языков. Мы разделили этот словарный запас на два, присваивая первые 5000 слов в учебный словарь, а второй 5000 - тестовому словаре.
Мы описали процедуру выравнивания в этом блоге. Это требует двух наборов векторов слов и небольшой двуязычный словарь пар перевода на двух языках; и генерирует матрицу, которая выравнивает исходный язык с целью. Иногда Google переводит английское слово в неанглийскую фразу, в этих случаях мы усредняем слово векторы, содержащиеся в фразе.
Чтобы разместить все 78 языков в одном пространстве, мы выравниваем каждый язык с английскими векторами (английская матрица - это идентичность).
Чтобы доказать, что процедура работает, мы можем предсказать переводы слов, не замеченных в учебном словаре. Для простоты мы предсказываем переводы ближайшими соседями. Так, например, если бы мы хотели перевести «собаку» в шведский, мы просто найдем шведский вектор слов, сходство косинуса которого с вектором «собака» является самым высоким.
Перво -наперво, давайте проверим выступление перевода с английского на любой другой язык. Для каждой языковой пары мы извлекаем набор из 2500 пар слов из тестового словаря. Точность @N обозначает вероятность того, что из 2500 целевых слов в этом наборе истинный перевод был одним из самых ближайших соседей исходного слова. Если бы выравнивание было совершенно случайным, мы ожидаем, что точность @1 будет около 0,0004.
| Целевой язык | Точность @1 | Точность @5 | Точность @10 |
|---|---|---|---|
| фр | 0,73 | 0,86 | 0,88 |
| пт | 0,73 | 0,86 | 0,89 |
| эс | 0,72 | 0,85 | 0,88 |
| это | 0,70 | 0,86 | 0,89 |
| норм | 0,68 | 0,83 | 0,86 |
| нет | 0,68 | 0,85 | 0,89 |
| дат | 0,66 | 0,84 | 0,88 |
| калифорнийский | 0,66 | 0,81 | 0,86 |
| св | 0,65 | 0,82 | 0,86 |
| CS | 0,64 | 0,81 | 0,85 |
| рост | 0,63 | 0,81 | 0,85 |
| де | 0,62 | 0,75 | 0,78 |
| пл | 0,62 | 0,79 | 0,83 |
| хю | 0,61 | 0,80 | 0,84 |
| фигура | 0,61 | 0,80 | 0,84 |
| EO | 0,61 | 0,80 | 0,85 |
| Ру | 0,60 | 0,78 | 0,82 |
| глина | 0,60 | 0,77 | 0,82 |
| мк | 0,58 | 0,79 | 0,84 |
| идентификатор | 0,58 | 0,81 | 0,86 |
| б. | 0,57 | 0,77 | 0,82 |
| РС | 0,57 | 0,81 | 0,86 |
| Великобритания | 0,57 | 0,75 | 0,79 |
| шнур | 0,56 | 0,77 | 0,81 |
| кадровый | 0,56 | 0,75 | 0,80 |
| трэнд | 0,56 | 0,77 | 0,81 |
| сорта | 0,56 | 0,77 | 0,82 |
| эль | 0,54 | 0,75 | 0,80 |
| скандал | 0,54 | 0,75 | 0,81 |
| ET | 0,53 | 0,73 | 0,78 |
| старший | 0,53 | 0,72 | 0,77 |
| аффина | 0,52 | 0,75 | 0,80 |
| лейтенант | 0,50 | 0,72 | 0,79 |
| АР | 0,48 | 0,69 | 0,75 |
| BS | 0,47 | 0,70 | 0,77 |
| дольдо | 0,47 | 0,68 | 0,75 |
| Евросоюз | 0,46 | 0,68 | 0,75 |
| фанат | 0,45 | 0,68 | 0,75 |
| герметичный | 0,43 | 0,66 | 0,73 |
| кв | 0,43 | 0,65 | 0,71 |
| быть | 0,43 | 0,64 | 0,70 |
| ZH | 0,40 | 0,68 | 0,75 |
| категория | 0,40 | 0,63 | 0,71 |
| сай | 0,39 | 0,63 | 0,71 |
| привет | 0,39 | 0,58 | 0,63 |
| Аризона | 0,38 | 0,60 | 0,67 |
| носитель | 0,37 | 0,58 | 0,66 |
| театр | 0,36 | 0,56 | 0,63 |
| кв | 0,35 | 0,60 | 0,68 |
| он | 0,33 | 0,45 | 0,48 |
| фей | 0,33 | 0,52 | 0,60 |
| VI | 0,31 | 0,53 | 0,62 |
| ТА | 0,31 | 0,50 | 0,56 |
| мгновенный | 0,30 | 0,49 | 0,56 |
| Ур | 0,29 | 0,52 | 0,61 |
| является | 0,29 | 0,51 | 0,59 |
| TL | 0,28 | 0,51 | 0,59 |
| кН | 0,28 | 0,43 | 0,46 |
| гуля | 0,25 | 0,44 | 0,51 |
| мнжен | 0,25 | 0,49 | 0,58 |
| УЗ | 0,24 | 0,43 | 0,51 |
| сияние | 0,22 | 0,40 | 0,45 |
| мл | 0,21 | 0,35 | 0,39 |
| KY | 0,20 | 0,40 | 0,49 |
| Мистер | 0,20 | 0,37 | 0,44 |
| тур | 0,20 | 0,33 | 0,38 |
| ла | 0,19 | 0,34 | 0,42 |
| JA | 0,18 | 0,44 | 0,56 |
| северо -восточный | 0,16 | 0,33 | 0,38 |
| а | 0,16 | 0,32 | 0,38 |
| тг | 0,14 | 0,31 | 0,39 |
| км | 0,12 | 0,26 | 0,30 |
| мой | 0,10 | 0,19 | 0,23 |
| фунт | 0,09 | 0,18 | 0,21 |
| мг | 0,07 | 0,18 | 0,25 |
| Ceb | 0,06 | 0,13 | 0,18 |
Как вы можете видеть, выравнивание неизменно намного лучше, чем случайно! В целом, процедура лучше всего подходит для других европейских языков, таких как французский, португальский и испанский. Мы используем 2500 пар слов, из -за 5000 слов в тестовом словаре, а не все слова, найденные API Google Translate, на самом деле присутствуют в словарном запате.
Теперь давайте сделаем что -то гораздо более захватывающее, давайте оценим производительность перевода между всеми возможными языковыми парами. Мы демонстрируем эту производительность перевода на тепловой карте ниже, где цвет элемента обозначает точность @1 при переводе с языка строки на язык столбца.
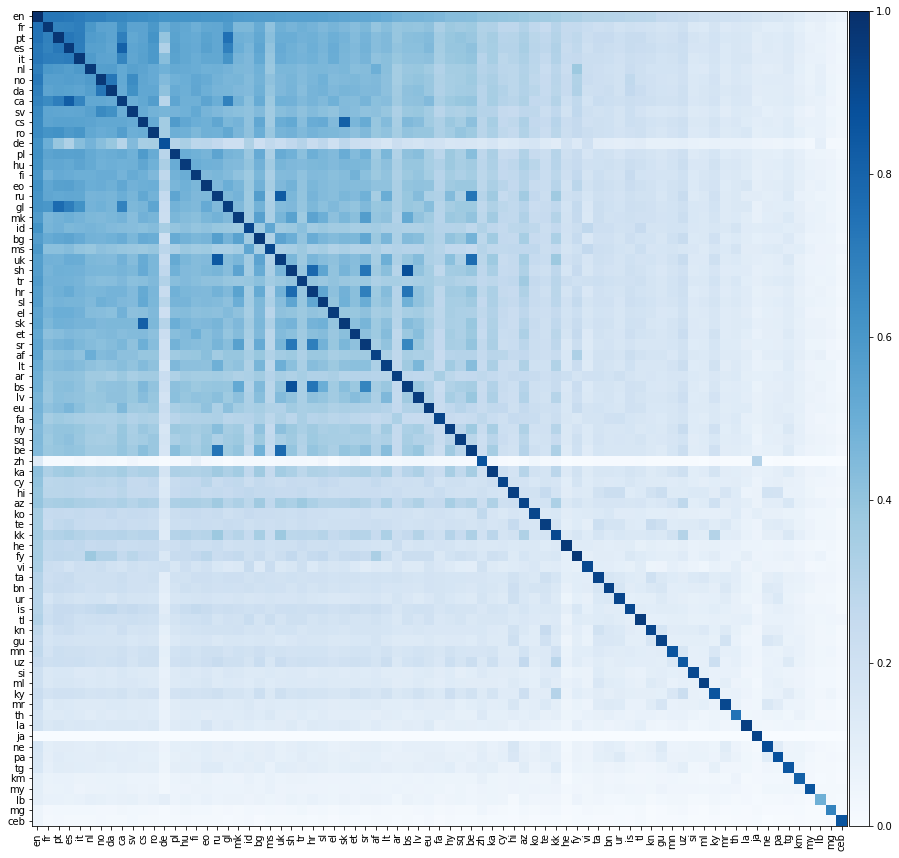
Мы должны подчеркнуть, что все языки были выровнены только с английским языком . Мы не предоставили учебные словаря между неанглийскими парами языка. Тем не менее, мы все еще можем успешно предсказать переводы между парами неанглийских языков, удивительно точно.
Мы ожидаем, что диагональные элементы матрицы выше будут 1, так как язык должен идеально перевести к себе. Однако на практике это не всегда происходит, потому что мы построили учебные и тестовые словаря, переводя общие английские слова на другие языки. Иногда несколько английских слов переводят одно и то же неанглийское слово, и поэтому одно и то же неанглийское слово может появляться несколько раз в тестовом наборе. Мы не учитывали это, что снижает производительность перевода.
Индивидуально, что, хотя мы только непосредственно выровняли языки по английскому языку, иногда язык переводится лучше на другой неанглийский язык, чем на английский! Мы можем рассчитать точность между парками двух языков; Средняя точность от языка 1 до языка 2 и наоборот. Мы также можем рассчитать точность английского языка; Среднее значение точностью от английского до языка 1 и от английского языка.
| Язык 1 | Язык 2 | Interpair Precision @1 | Английская парка точности @1 |
|---|---|---|---|
| BS | шнур | 0,88 | 0,52 |
| Ру | Великобритания | 0,84 | 0,58 |
| калифорнийский | эс | 0,82 | 0,69 |
| CS | скандал | 0,82 | 0,59 |
| кадровый | шнур | 0,78 | 0,56 |
| быть | Великобритания | 0,77 | 0,50 |
| глина | пт | 0,76 | 0,66 |
| BS | кадровый | 0,74 | 0,52 |
| быть | Ру | 0,73 | 0,51 |
| дат | нет | 0,73 | 0,67 |
| старший | шнур | 0,73 | 0,54 |
| пт | эс | 0,72 | 0,72 |
| калифорнийский | пт | 0,70 | 0,69 |
| глина | эс | 0,70 | 0,66 |
| кадровый | старший | 0,69 | 0,54 |
| калифорнийский | глина | 0,68 | 0,63 |
| BS | старший | 0,67 | 0,50 |
| мк | старший | 0,56 | 0,55 |
| кв | KY | 0,30 | 0,28 |
Все эти языковые пары имеют очень близкие лингвистические корни. Например, первая пара выше-боснийские и сербо-хорватские; Босний-вариант сербо-хорватского. Вторая пара - русский и украшенный; Оба восточно-славянские языки. Кажется, что чем более похожие два языка, тем более похожими геометрия их векторов быстрого текста; приводя к улучшению производительности перевода.
Матрицы, представленные в этом репозитории, являются ортогональными. Интуитивно, каждая матрица может быть разбита на серию вращений и отражений. Вращения и отражения не изменяют расстояние между любыми двумя точками в векторном пространстве; и, следовательно, ни один из внутренних продуктов между векторами слов в пределах языка не изменяется, затрагиваются только внутренние продукты между словами разных языков.
На этой теме есть ряд замечательных бумаг. Мы перечислили несколько из них ниже:
Ряд читателей выразили интерес к обучению и тестовым словарям, которые мы использовали в этом репозитории. Однако нам бы хотелось загрузить их, хотя мы не принимали юридическую консультацию, мы обеспокоены тем, что это можно интерпретировать как нарушение условий API Google Translate.
Матрицы преобразования распространяются по лицензии Creative Commons Attribution-Share-Alike 3.0 .


