fastText_multilingual
1.0.0
Perhatikan repositori ini tidak lagi secara aktif dipelihara oleh Babel Kesehatan. Untuk bantuan lebih lanjut, hubungi penulis kertas.
Facebook baru-baru ini vektor kata terbuka dalam 89 bahasa. Namun vektor -vektor ini monolingual; Berarti bahwa sementara kata -kata serupa dalam bahasa berbagi vektor yang sama, kata -kata terjemahan dari berbagai bahasa tidak memiliki vektor yang serupa. Dalam makalah baru -baru ini di ICLR 2017, kami menunjukkan bagaimana SVD dapat digunakan untuk mempelajari transformasi linier (matriks), yang menyelaraskan vektor monolingual dari dua bahasa dalam satu ruang vektor tunggal. Dalam repositori ini kami menyediakan 78 matriks, yang dapat digunakan untuk menyelaraskan sebagian besar bahasa FastText dalam satu ruang.
Readme ini menjelaskan bagaimana matriks harus digunakan. Kami juga menyajikan tugas evaluasi sederhana, di mana kami menunjukkan bahwa kami dapat berhasil memprediksi terjemahan kata -kata dalam berbagai bahasa. Prosedur kami bergantung pada pengumpulan kamus pelatihan dwibahasa pasangan kata dalam dua bahasa, tetapi luar biasa kami dapat berhasil memprediksi terjemahan kata -kata antara pasangan bahasa yang kami tidak punya kamus pelatihan!
Word Embeddings mendefinisikan kesamaan antara dua kata dengan produk dalam yang dinormalisasi dari vektor mereka. Matriks dalam bahasa repositori ini bahasa dalam satu ruang, tanpa mengubah hubungan kesamaan monolingual ini . Ketika Anda menggunakan vektor multibahasa yang dihasilkan untuk tugas -tugas monolingual, mereka akan melakukan persis sama dengan vektor asli. Untuk mempelajari lebih lanjut tentang embeddings Word, lihat blog Colah atau pengantar Sam untuk representasi vektor.
Perhatikan bahwa sejak kami merilis Repositori ini Facebook telah merilis 204 bahasa tambahan; Namun kata vektor dari 90 bahasa asli tidak berubah, dan transformasi yang disediakan dalam repositori ini masih akan berfungsi. Jika Anda ingin mempelajari matriks penyelarasan Anda sendiri, kami memberikan contoh di Align_your_own.ipynb.
Jika Anda menggunakan repositori ini, silakan kutip:
Vektor kata bilingual offline, transformasi ortogonal dan softmax terbalik
Samuel L. Smith, David HP Turban, Steven Hamblin dan Nils Y. Hammerla
ICLR 2017 (jalur konferensi)
Klon salinan lokal repositori ini, dan unduh vektor fasttext yang Anda butuhkan dari sini. Saya akan menganggap Anda telah mengunduh vektor untuk Prancis dan Rusia dalam format teks. Katakanlah kami ingin membandingkan kesamaan "obrolan" dan "кот". Kami memuat kata vektor:
from fasttext import FastVector
fr_dictionary = FastVector ( vector_file = 'wiki.fr.vec' )
ru_dictionary = FastVector ( vector_file = 'wiki.ru.vec' )Kita dapat mengekstrak kata vektor dan menghitung kesamaan cosinus mereka:
fr_vector = fr_dictionary [ "chat" ]
ru_vector = ru_dictionary [ "кот" ]
print ( FastVector . cosine_similarity ( fr_vector , ru_vector ))
# Result should be 0.02Kesamaan kosinus berjalan antara -1 dan 1. Tampaknya "obrolan" dan "кот" tidak serupa atau berbeda. Tapi sekarang kita menerapkan transformasi untuk menyelaraskan dua kamus dalam satu ruang:
fr_dictionary . apply_transform ( 'alignment_matrices/fr.txt' )
ru_dictionary . apply_transform ( 'alignment_matrices/ru.txt' )Dan mengevaluasi kembali kesamaan kosinus:
print ( FastVector . cosine_similarity ( fr_dictionary [ "chat" ], ru_dictionary [ "кот" ]))
# Result should be 0.43Ternyata "obrolan" dan "кот" sangat mirip. Ini bagus, karena mereka berdua berarti "kucing".
Dari 89 bahasa yang disediakan oleh Facebook, 78 didukung oleh Google Translate API. Kami pertama kali memperoleh 10.000 kata paling umum dalam kosakata FastText Inggris, dan kemudian menggunakan API untuk menerjemahkan kata -kata ini ke dalam 78 bahasa yang tersedia. Kami membagi kosa kata ini menjadi dua, menugaskan 5000 kata pertama ke kamus pelatihan, dan 5000 kedua untuk kamus uji.
Kami menggambarkan prosedur penyelarasan di blog ini. Dibutuhkan dua set vektor kata dan kamus dua bahasa kecil dari pasangan terjemahan dalam dua bahasa; dan menghasilkan matriks yang menyelaraskan bahasa sumber dengan target. Terkadang Google menerjemahkan kata bahasa Inggris ke frasa non-Inggris, dalam kasus ini kami rata-rata kata vektor yang terkandung dalam frasa.
Untuk menempatkan semua 78 bahasa dalam satu ruang, kami menyelaraskan setiap bahasa dengan vektor bahasa Inggris (matriks bahasa Inggris adalah identitas).
Untuk membuktikan bahwa prosedur ini berhasil, kita dapat memprediksi terjemahan kata -kata yang tidak terlihat dalam kamus pelatihan. Untuk kesederhanaan kami memprediksi terjemahan oleh tetangga terdekat. Jadi misalnya, jika kita ingin menerjemahkan "anjing" ke dalam bahasa Swedia, kita hanya akan menemukan kata vektor Swedia yang kemiripan cosinus dengan vektor kata "anjing" adalah yang tertinggi.
Hal pertama yang pertama, mari kita uji kinerja terjemahan dari bahasa Inggris ke dalam setiap bahasa lainnya. Untuk setiap pasangan bahasa, kami mengekstrak satu set 2500 pasangan kata dari kamus uji. Precision @N menunjukkan probabilitas bahwa, dari 2500 kata target dalam set ini, terjemahan yang sebenarnya adalah salah satu dari tetangga terdekat dari kata sumber. Jika penyelarasannya benar -benar acak, kami berharap presisi @1 sekitar 0,0004.
| Bahasa target | Presisi @1 | Presisi @5 | Presisi @10 |
|---|---|---|---|
| fr | 0.73 | 0.86 | 0.88 |
| pt | 0.73 | 0.86 | 0.89 |
| es | 0.72 | 0.85 | 0.88 |
| dia | 0,70 | 0.86 | 0.89 |
| nl | 0.68 | 0.83 | 0.86 |
| TIDAK | 0.68 | 0.85 | 0.89 |
| da | 0.66 | 0.84 | 0.88 |
| ca | 0.66 | 0.81 | 0.86 |
| sv | 0.65 | 0.82 | 0.86 |
| CS | 0.64 | 0.81 | 0.85 |
| ro | 0.63 | 0.81 | 0.85 |
| de | 0.62 | 0,75 | 0.78 |
| pl | 0.62 | 0.79 | 0.83 |
| hu | 0.61 | 0.80 | 0.84 |
| fi | 0.61 | 0.80 | 0.84 |
| eo | 0.61 | 0.80 | 0.85 |
| ru | 0.60 | 0.78 | 0.82 |
| gl | 0.60 | 0.77 | 0.82 |
| mk | 0,58 | 0.79 | 0.84 |
| pengenal | 0,58 | 0.81 | 0.86 |
| bg | 0,57 | 0.77 | 0.82 |
| MS | 0,57 | 0.81 | 0.86 |
| Inggris | 0,57 | 0,75 | 0.79 |
| sh | 0,56 | 0.77 | 0.81 |
| jam | 0,56 | 0,75 | 0.80 |
| tr | 0,56 | 0.77 | 0.81 |
| sl | 0,56 | 0.77 | 0.82 |
| EL | 0,54 | 0,75 | 0.80 |
| SK | 0,54 | 0,75 | 0.81 |
| et | 0,53 | 0.73 | 0.78 |
| sr | 0,53 | 0.72 | 0.77 |
| af | 0,52 | 0,75 | 0.80 |
| LT | 0,50 | 0.72 | 0.79 |
| ar | 0.48 | 0.69 | 0,75 |
| BS | 0.47 | 0,70 | 0.77 |
| lv | 0.47 | 0.68 | 0,75 |
| UE | 0.46 | 0.68 | 0,75 |
| fa | 0.45 | 0.68 | 0,75 |
| hy | 0.43 | 0.66 | 0.73 |
| sq | 0.43 | 0.65 | 0.71 |
| menjadi | 0.43 | 0.64 | 0,70 |
| ZH | 0.40 | 0.68 | 0,75 |
| ka | 0.40 | 0.63 | 0.71 |
| cy | 0.39 | 0.63 | 0.71 |
| Hai | 0.39 | 0,58 | 0.63 |
| AZ | 0.38 | 0.60 | 0.67 |
| ko | 0.37 | 0,58 | 0.66 |
| te | 0.36 | 0,56 | 0.63 |
| kk | 0.35 | 0.60 | 0.68 |
| Dia | 0.33 | 0.45 | 0.48 |
| TA | 0.33 | 0,52 | 0.60 |
| vi | 0.31 | 0,53 | 0.62 |
| ta | 0.31 | 0,50 | 0,56 |
| bn | 0,30 | 0.49 | 0,56 |
| ur | 0.29 | 0,52 | 0.61 |
| adalah | 0.29 | 0,51 | 0,59 |
| tl | 0.28 | 0,51 | 0,59 |
| kn | 0.28 | 0.43 | 0.46 |
| gu | 0.25 | 0.44 | 0,51 |
| M N | 0.25 | 0.49 | 0,58 |
| Uz | 0.24 | 0.43 | 0,51 |
| si | 0.22 | 0.40 | 0.45 |
| ml | 0.21 | 0.35 | 0.39 |
| KY | 0,20 | 0.40 | 0.49 |
| Tn. | 0,20 | 0.37 | 0.44 |
| th | 0,20 | 0.33 | 0.38 |
| la | 0.19 | 0.34 | 0.42 |
| ja | 0.18 | 0.44 | 0,56 |
| ne | 0.16 | 0.33 | 0.38 |
| pa | 0.16 | 0.32 | 0.38 |
| tg | 0.14 | 0.31 | 0.39 |
| km | 0.12 | 0.26 | 0,30 |
| -ku | 0.10 | 0.19 | 0.23 |
| lb | 0,09 | 0.18 | 0.21 |
| mg | 0,07 | 0.18 | 0.25 |
| Ceb | 0,06 | 0.13 | 0.18 |
Seperti yang Anda lihat, penyelarasan secara konsisten jauh lebih baik daripada acak! Secara umum, prosedur ini bekerja paling baik untuk bahasa Eropa lainnya seperti Prancis, Portugis dan Spanyol. Kami menggunakan 2500 pasangan kata, karena 5000 kata dalam kamus uji, tidak semua kata yang ditemukan oleh Google Translate API sebenarnya ada dalam kosakata FastText.
Sekarang mari kita lakukan sesuatu yang jauh lebih menarik, mari kita evaluasi kinerja terjemahan antara semua pasangan bahasa yang mungkin. Kami menunjukkan kinerja terjemahan ini pada heatmap di bawah ini, di mana warna elemen menunjukkan presisi @1 saat menerjemahkan dari bahasa baris ke dalam bahasa kolom.
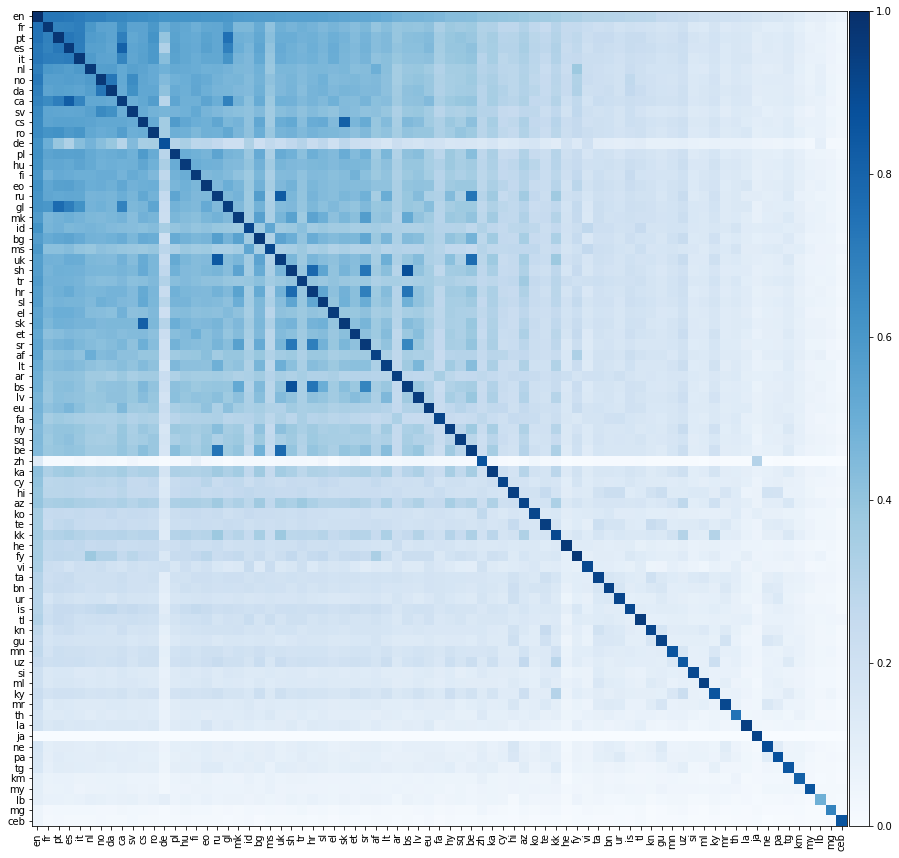
Kita harus menekankan bahwa semua bahasa hanya selaras dengan bahasa Inggris . Kami tidak memberikan kamus pelatihan antara pasangan bahasa non-Inggris. Namun kami masih dapat dengan berhasil memprediksi terjemahan antara pasangan bahasa non-Inggris dengan sangat akurat.
Kami mengharapkan elemen diagonal dari matriks di atas menjadi 1, karena suatu bahasa harus diterjemahkan dengan sempurna untuk dirinya sendiri. Namun dalam praktiknya ini tidak selalu terjadi, karena kami membangun kamus pelatihan dan uji dengan menerjemahkan kata -kata bahasa Inggris yang umum ke dalam bahasa lain. Terkadang banyak kata bahasa Inggris diterjemahkan ke kata non-Inggris yang sama, dan kata-kata non-Inggris yang sama dapat muncul beberapa kali dalam set tes. Kami belum memperhitungkan hal ini dengan benar, yang mengurangi kinerja terjemahan.
Tegas, meskipun kami hanya secara langsung menyelaraskan bahasa dengan bahasa Inggris, kadang-kadang bahasa diterjemahkan lebih baik ke bahasa non-Inggris lain daripada bahasa Inggris! Kita dapat menghitung ketepatan antar-pasangan dari dua bahasa; Presisi rata -rata dari bahasa 1 ke bahasa 2 dan sebaliknya. Kami juga dapat menghitung presisi pasangan bahasa Inggris; Rata-rata ketepatan dari bahasa Inggris ke bahasa 1 dan dari bahasa Inggris ke bahasa 2. Di bawah ini kami mencantumkan semua pasangan bahasa yang ketepatan antar-pasangan melebihi presisi pasangan bahasa Inggris:
| Bahasa 1 | Bahasa 2 | Presisi antar-pasangan @1 | Presisi bahasa Inggris @1 |
|---|---|---|---|
| BS | sh | 0.88 | 0,52 |
| ru | Inggris | 0.84 | 0,58 |
| ca | es | 0.82 | 0.69 |
| CS | SK | 0.82 | 0,59 |
| jam | sh | 0.78 | 0,56 |
| menjadi | Inggris | 0.77 | 0,50 |
| gl | pt | 0.76 | 0.66 |
| BS | jam | 0.74 | 0,52 |
| menjadi | ru | 0.73 | 0,51 |
| da | TIDAK | 0.73 | 0.67 |
| sr | sh | 0.73 | 0,54 |
| pt | es | 0.72 | 0.72 |
| ca | pt | 0,70 | 0.69 |
| gl | es | 0,70 | 0.66 |
| jam | sr | 0.69 | 0,54 |
| ca | gl | 0.68 | 0.63 |
| BS | sr | 0.67 | 0,50 |
| mk | sr | 0,56 | 0,55 |
| kk | KY | 0,30 | 0.28 |
Semua pasangan bahasa ini berbagi akar linguistik yang sangat dekat. Misalnya pasangan pertama di atas adalah Bosnia dan Serbo-Kroasia; Bosnian adalah varian dari Serbo-Kroasia. Pasangan kedua adalah Rusia dan Ukranian; Kedua bahasa East-Slavic. Tampaknya semakin mirip dua bahasa, semakin mirip geometri vektor fasttext mereka; mengarah ke peningkatan kinerja terjemahan.
Matriks yang disediakan dalam repositori ini adalah ortogonal. Secara intuitif, setiap matriks dapat dipecah menjadi serangkaian rotasi dan refleksi. Rotasi dan refleksi tidak mengubah jarak antara dua titik dalam ruang vektor; dan akibatnya tidak ada produk dalam antara vektor kata dalam suatu bahasa yang diubah, hanya produk dalam antara kata -kata vektor dari berbagai bahasa yang terpengaruh.
Ada sejumlah makalah hebat tentang topik ini. Kami telah mendaftarkan beberapa dari mereka di bawah ini:
Sejumlah pembaca telah menyatakan minatnya pada kamus pelatihan dan uji yang kami gunakan dalam repositori ini. Namun, kami ingin mengunggah ini, sementara kami belum menerima nasihat hukum, kami khawatir ini dapat ditafsirkan sebagai melanggar ketentuan API Terjemahan Google.
Matriks transformasi didistribusikan di bawah lisensi Creative Commons Atribution-Share 3.0 .


