fastText_multilingual
1.0.0
Remarque Ce référentiel n'est plus activement entretenu par Babylon Health. Pour plus d'assistance, contactez les auteurs du journal.
Facebook Vecteurs de mots ouverts récemment open dans 89 langues. Cependant, ces vecteurs sont monolingues; Ce qui signifie que si des mots similaires dans une langue partagent des vecteurs similaires, les mots de traduction de différentes langues n'ont pas de vecteurs similaires. Dans un article récent de ICLR 2017, nous avons montré comment le SVD peut être utilisé pour apprendre une transformation linéaire (une matrice), qui aligne des vecteurs monolingues de deux langues dans un seul espace vectoriel. Dans ce référentiel, nous fournissons 78 matrices, qui peuvent être utilisées pour aligner la majorité des langages de texte rapide dans un seul espace.
Cette lecture explique comment les matrices doivent être utilisées. Nous présentons également une tâche d'évaluation simple, où nous montrons que nous sommes en mesure de prédire avec succès les traductions de mots dans plusieurs langues. Notre procédure repose sur la collecte de dictionnaires de formation bilingues de paires de mots dans deux langues, mais remarquablement, nous sommes en mesure de prédire avec succès les traductions des mots entre les paires de langues pour lesquelles nous n'avions pas de dictionnaire de formation!
Les incorporations de mots définissent la similitude entre deux mots par le produit intérieur normalisé de leurs vecteurs. Les matrices de ce référentiel placent les langues dans un seul espace, sans modifier aucune de ces relations de similitude monolingue . Lorsque vous utilisez les vecteurs multilingues résultants pour les tâches monolingues, ils effectueront exactement les mêmes que les vecteurs d'origine. Pour en savoir plus sur les intérêts des mots, consultez le blog de Colah ou l'introduction de Sam aux représentations vectorielles.
Notez que depuis que nous avons publié ce référentiel Facebook a publié 204 langues supplémentaires; Cependant, le mot vecteurs des 90 langues d'origine n'a pas changé, et les transformations fournies dans ce référentiel fonctionneront toujours. Si vous souhaitez apprendre vos propres matrices d'alignement, nous fournissons un exemple dans align_your_own.ipynb.
Si vous utilisez ce référentiel, veuillez citer:
Vectors de mot bilingue hors ligne, transformations orthogonales et le softmax inversé
Samuel L. Smith, David HP Turban, Steven Hamblin et Nils Y. Hammerla
ICLR 2017 (piste de conférence)
Clone une copie locale de ce référentiel et téléchargez les vecteurs FastText dont vous avez besoin à partir d'ici. Je vais supposer que vous avez téléchargé les vecteurs pour le français et le russe au format texte. Disons que nous voulons comparer la similitude de "chat" et "кот". Nous chargeons le mot vecteurs:
from fasttext import FastVector
fr_dictionary = FastVector ( vector_file = 'wiki.fr.vec' )
ru_dictionary = FastVector ( vector_file = 'wiki.ru.vec' )Nous pouvons extraire le mot vecteurs et calculer leur similitude de cosinus:
fr_vector = fr_dictionary [ "chat" ]
ru_vector = ru_dictionary [ "кот" ]
print ( FastVector . cosine_similarity ( fr_vector , ru_vector ))
# Result should be 0.02La similitude du cosinus se déroule entre -1 et 1. Il semble que le "chat" et "кот" ne sont ni similaires ni différents. Mais maintenant, nous appliquons les transformations pour aligner les deux dictionnaires dans un seul espace:
fr_dictionary . apply_transform ( 'alignment_matrices/fr.txt' )
ru_dictionary . apply_transform ( 'alignment_matrices/ru.txt' )Et réévaluer la similitude du cosinus:
print ( FastVector . cosine_similarity ( fr_dictionary [ "chat" ], ru_dictionary [ "кот" ]))
# Result should be 0.43Il s'avère que "Chat" et "кот" sont assez similaires après tout. C'est bien, car ils signifient tous les deux "chat".
Sur les 89 langues fournies par Facebook, 78 sont pris en charge par l'API Google Translate. Nous avons d'abord obtenu les 10 000 mots les plus courants dans le vocabulaire en texte rapide anglais, puis utilisons l'API pour traduire ces mots dans les 78 langues disponibles. Nous avons divisé ce vocabulaire en deux, attribuant les 5000 premiers mots au dictionnaire de formation et le deuxième 5000 au dictionnaire de test.
Nous avons décrit la procédure d'alignement de ce blog. Il faut deux ensembles de vecteurs de mots et un petit dictionnaire bilingue des paires de traduction en deux langues; et génère une matrice qui aligne la langue source avec la cible. Parfois, Google traduit un mot anglais par une phrase non anglophone, dans ces cas, nous faisons en moyenne les mots vecteurs contenus dans la phrase.
Pour placer les 78 langues dans un seul espace, nous alignons toutes les langues sur les vecteurs anglais (la matrice anglaise est l'identité).
Pour prouver que la procédure fonctionne, nous pouvons prédire les traductions des mots non vus dans le dictionnaire de formation. Pour plus de simplicité, nous prédisons les traductions par des voisins les plus proches. Ainsi, par exemple, si nous voulions traduire "chien" en suédois, nous trouverions simplement le vecteur de mot suédois dont la similitude du cosinus avec le vecteur de mot "chien" est la plus élevée.
Tout d'abord, testons les performances de traduction de l'anglais dans toutes les autres langues. Pour chaque paire de langues, nous extrayons un ensemble de 2500 paires de mots du dictionnaire de test. La précision @n désigne la probabilité que, sur les 2500 mots cibles de cet ensemble, la vraie traduction était l'un des n voisins les plus proches du mot source. Si l'alignement était complètement aléatoire, nous nous attendrions à ce que la précision @ 1 soit autour de 0,0004.
| Langue cible | Précision @ 1 | Précision @ 5 | Précision @ 10 |
|---|---|---|---|
| frousser | 0,73 | 0,86 | 0,88 |
| pt | 0,73 | 0,86 | 0,89 |
| es | 0,72 | 0,85 | 0,88 |
| il | 0,70 | 0,86 | 0,89 |
| nl | 0,68 | 0,83 | 0,86 |
| Non | 0,68 | 0,85 | 0,89 |
| da | 0,66 | 0,84 | 0,88 |
| Californie | 0,66 | 0,81 | 0,86 |
| SV | 0,65 | 0,82 | 0,86 |
| CS | 0,64 | 0,81 | 0,85 |
| ro | 0,63 | 0,81 | 0,85 |
| de | 0,62 | 0,75 | 0,78 |
| PL | 0,62 | 0,79 | 0,83 |
| hu | 0,61 | 0,80 | 0,84 |
| FI | 0,61 | 0,80 | 0,84 |
| eo | 0,61 | 0,80 | 0,85 |
| ru | 0,60 | 0,78 | 0,82 |
| glousser | 0,60 | 0,77 | 0,82 |
| mk | 0,58 | 0,79 | 0,84 |
| identifiant | 0,58 | 0,81 | 0,86 |
| bg | 0,57 | 0,77 | 0,82 |
| MS | 0,57 | 0,81 | 0,86 |
| Royaume-Uni | 0,57 | 0,75 | 0,79 |
| shot | 0,56 | 0,77 | 0,81 |
| heure | 0,56 | 0,75 | 0,80 |
| tr | 0,56 | 0,77 | 0,81 |
| sl | 0,56 | 0,77 | 0,82 |
| El | 0,54 | 0,75 | 0,80 |
| skin | 0,54 | 0,75 | 0,81 |
| ET | 0,53 | 0,73 | 0,78 |
| SR | 0,53 | 0,72 | 0,77 |
| AF | 0,52 | 0,75 | 0,80 |
| LT | 0,50 | 0,72 | 0,79 |
| ardente | 0,48 | 0,69 | 0,75 |
| bs | 0,47 | 0,70 | 0,77 |
| LV | 0,47 | 0,68 | 0,75 |
| UE | 0,46 | 0,68 | 0,75 |
| fa | 0,45 | 0,68 | 0,75 |
| hy | 0,43 | 0,66 | 0,73 |
| sq | 0,43 | 0,65 | 0,71 |
| être | 0,43 | 0,64 | 0,70 |
| zh | 0,40 | 0,68 | 0,75 |
| ka | 0,40 | 0,63 | 0,71 |
| cycle | 0,39 | 0,63 | 0,71 |
| Salut | 0,39 | 0,58 | 0,63 |
| az | 0,38 | 0,60 | 0,67 |
| ko | 0,37 | 0,58 | 0,66 |
| te | 0,36 | 0,56 | 0,63 |
| kk | 0,35 | 0,60 | 0,68 |
| il | 0,33 | 0,45 | 0,48 |
| fy | 0,33 | 0,52 | 0,60 |
| vi | 0,31 | 0,53 | 0,62 |
| faire | 0,31 | 0,50 | 0,56 |
| BN | 0,30 | 0,49 | 0,56 |
| ur | 0,29 | 0,52 | 0,61 |
| est | 0,29 | 0,51 | 0,59 |
| tl | 0,28 | 0,51 | 0,59 |
| KN | 0,28 | 0,43 | 0,46 |
| GU | 0,25 | 0,44 | 0,51 |
| MN | 0,25 | 0,49 | 0,58 |
| uz | 0,24 | 0,43 | 0,51 |
| si | 0,22 | 0,40 | 0,45 |
| ml | 0,21 | 0,35 | 0,39 |
| ky | 0.20 | 0,40 | 0,49 |
| M. | 0.20 | 0,37 | 0,44 |
| ème | 0.20 | 0,33 | 0,38 |
| la | 0,19 | 0,34 | 0,42 |
| ja | 0,18 | 0,44 | 0,56 |
| ne | 0,16 | 0,33 | 0,38 |
| Pennsylvanie | 0,16 | 0,32 | 0,38 |
| tg | 0,14 | 0,31 | 0,39 |
| km | 0,12 | 0,26 | 0,30 |
| mon | 0.10 | 0,19 | 0,23 |
| kg | 0,09 | 0,18 | 0,21 |
| mg | 0,07 | 0,18 | 0,25 |
| CEB | 0,06 | 0,13 | 0,18 |
Comme vous pouvez le voir, l'alignement est toujours bien meilleur que le hasard! En général, la procédure fonctionne mieux pour d'autres langues européennes comme le français, le portugais et l'espagnol. Nous utilisons 2500 paires de mots, en raison des 5000 mots du dictionnaire de test, tous les mots trouvés par l'API Google Translate ne sont pas réellement présents dans le vocabulaire en texte rapide.
Maintenant, faisons quelque chose de beaucoup plus excitant, évaluons les performances de traduction entre toutes les paires de langues possibles. Nous montrons cette performance de traduction sur la carte thermique ci-dessous, où la couleur d'un élément désigne la précision @ 1 lors de la traduction de la langue de la ligne dans la langue de la colonne.
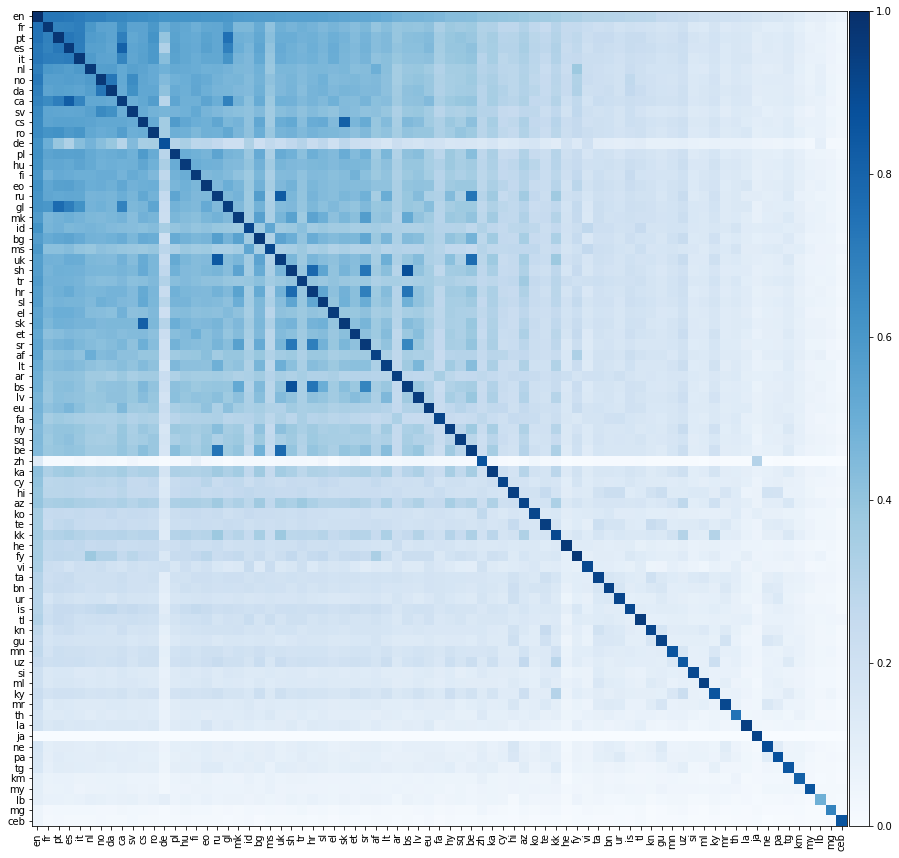
Nous devons souligner que toutes les langues étaient alignées uniquement sur l'anglais . Nous n'avons pas fourni de dictionnaires de formation entre les paires de langues non anglophones. Pourtant, nous sommes toujours en mesure de prédire avec succès les traductions entre des paires de langues non anglophones remarquablement avec précision.
Nous nous attendons à ce que les éléments diagonaux de la matrice ci-dessus soient 1, car une langue devrait se traduire parfaitement vers elle-même. Cependant, dans la pratique, cela ne se produit pas toujours, car nous avons construit la formation et tester les dictionnaires en traduisant des mots anglais communs dans les autres langues. Parfois, plusieurs mots anglais se traduisent par le même mot non anglais, et donc le même mot non anglais peut apparaître plusieurs fois dans l'ensemble de tests. Nous n'avons pas correctement pris en compte cela, ce qui réduit les performances de traduction.
Intincement, même si nous n'avons aligné directement les langues de l'anglais, une langue se traduit parfois mieux dans une autre langue non anglaise qu'en anglais! Nous pouvons calculer la précision inter-paires de deux langues; La précision moyenne de la langue 1 à la langue 2 et vice versa. Nous pouvons également calculer la précision de la paire anglaise; La moyenne de la précision de l'anglais à la langue 1 et de l'anglais à la langue 2. Ci-dessous, nous énumérons toutes les paires de langues pour lesquelles la précision inter-paires dépasse la précision de la paire anglaise:
| Langue 1 | Langue 2 | Précision entre pair @ 1 | Précision de paire anglaise @ 1 |
|---|---|---|---|
| bs | shot | 0,88 | 0,52 |
| ru | Royaume-Uni | 0,84 | 0,58 |
| Californie | es | 0,82 | 0,69 |
| CS | skin | 0,82 | 0,59 |
| heure | shot | 0,78 | 0,56 |
| être | Royaume-Uni | 0,77 | 0,50 |
| glousser | pt | 0,76 | 0,66 |
| bs | heure | 0,74 | 0,52 |
| être | ru | 0,73 | 0,51 |
| da | Non | 0,73 | 0,67 |
| SR | shot | 0,73 | 0,54 |
| pt | es | 0,72 | 0,72 |
| Californie | pt | 0,70 | 0,69 |
| glousser | es | 0,70 | 0,66 |
| heure | SR | 0,69 | 0,54 |
| Californie | glousser | 0,68 | 0,63 |
| bs | SR | 0,67 | 0,50 |
| mk | SR | 0,56 | 0,55 |
| kk | ky | 0,30 | 0,28 |
Toutes ces paires de langues partagent des racines linguistiques très proches. Par exemple, la première paire ci-dessus est bosniaque et serbo-croatien; Bosnian est une variante de serbo-croatien. La deuxième paire est russe et ukranienne; les deux langues orientales. Il semble que plus les deux langues sont similaires, plus la géométrie de leurs vecteurs de texte rapide est similaire; conduisant à une amélioration des performances de traduction.
Les matrices fournies dans ce référentiel sont orthogonales. Intuitivement, chaque matrice peut être décomposée en une série de rotations et de réflexions. Les rotations et les réflexions ne modifient pas la distance entre deux points dans un espace vectoriel; Et par conséquent, aucun des produits intérieurs entre les vecteurs de mots dans une langue n'est modifié, seuls les produits intérieurs entre les vecteurs de mots de différentes langues sont affectés.
Il y a un certain nombre de grands articles sur ce sujet. Nous en avons répertorié quelques-uns ci-dessous:
Un certain nombre de lecteurs ont exprimé un intérêt pour les dictionnaires de formation et de test que nous avons utilisés dans ce référentiel. Nous aurions aimé les télécharger, cependant, bien que nous n'ayons pas pris de conseils juridiques, nous craignons que cela puisse être interprété comme brisant les termes de l'API Google Translate.
Les matrices de transformation sont réparties sous la licence Creative Commons Attribution-Share-Alike 3.0 .


