fastText_multilingual
1.0.0
Beachten Sie, dass dieses Repository nicht mehr von Babylon Health aktiv aufrechterhalten wird. Für weitere Hilfe wenden Sie sich an die Papierautoren.
Facebook in 89 Sprachen kürzlich Open-Sourced-Wort-Vektoren. Diese Vektoren sind jedoch einsprachig; Dies bedeutet, dass ähnliche Wörter in einer Sprache ähnliche Vektoren teilen, aber Übersetzungswörter aus verschiedenen Sprachen keine ähnlichen Vektoren haben. In einer kürzlich durchgeführten Arbeit auf der ICLR 2017 haben wir gezeigt, wie die SVD verwendet werden kann, um eine lineare Transformation (eine Matrix) zu lernen, die monolinguelle Vektoren aus zwei Sprachen in einem einzigen Vektorraum ausrichtet. In diesem Repository bieten wir 78 Matrizen an, mit denen die Mehrheit der FastText -Sprachen in einem einzigen Raum ausgerichtet ist.
Diese Readme erklärt, wie die Matrizen verwendet werden sollen. Wir präsentieren auch eine einfache Bewertungsaufgabe, bei der wir zeigen, dass wir die Übersetzungen von Wörtern in mehreren Sprachen erfolgreich vorhersagen können. Unser Verfahren beruht auf der Sammlung von zweisprachigen Trainingswörterbüchern von Wortpaaren in zwei Sprachen, aber bemerkenswerterweise können wir die Übersetzungen von Wörtern zwischen Sprachpaaren erfolgreich vorhersagen, für die wir kein Trainingswörterbuch hatten!
Worteinbettungen definieren die Ähnlichkeit zwischen zwei Wörtern durch das normalisierte innere Produkt ihrer Vektoren. Die Matrizen in diesem Repository legen Sprachen in einen einzelnen Raum, ohne diese einsprachigen Ähnlichkeitsbeziehungen zu ändern . Wenn Sie die resultierenden mehrsprachigen Vektoren für einsprachige Aufgaben verwenden, werden sie genauso wie die ursprünglichen Vektoren ausgeführt. Um mehr über Word -Einbettungen zu erfahren, lesen Sie Colahs Blog oder Sams Einführung in Vektordarstellungen.
Beachten Sie, dass seit wir dieses Repository -Facebook weitere 204 Sprachen veröffentlicht haben. Die Wortvektoren der ursprünglichen 90 Sprachen haben sich jedoch nicht geändert, und die in diesem Repository bereitgestellten Transformationen funktionieren weiterhin. Wenn Sie Ihre eigenen Ausrichtungsmatrizen lernen möchten, geben wir ein Beispiel in Align_your_own.ipynb an.
Wenn Sie dieses Repository verwenden, zitieren Sie bitte:
Zweisprachige Offline -Wortvektoren, orthogonale Transformationen und der umgekehrte Softmax
Samuel L. Smith, David HP Turban, Steven Hamblin und Nils Y. Hammerla
ICLR 2017 (Konferenzstrecke)
Klonen Sie eine lokale Kopie dieses Repositorys und laden Sie die von Ihnen benötigten FastText -Vektoren herunter. Ich gehe davon aus, dass Sie die Vektoren für Französisch und Russisch im Textformat heruntergeladen haben. Nehmen wir an, wir möchten die Ähnlichkeit von "Chat" und "кот" vergleichen. Wir laden das Wort Vektoren:
from fasttext import FastVector
fr_dictionary = FastVector ( vector_file = 'wiki.fr.vec' )
ru_dictionary = FastVector ( vector_file = 'wiki.ru.vec' )Wir können die Wortvektoren extrahieren und ihre Kosinusähnlichkeit berechnen:
fr_vector = fr_dictionary [ "chat" ]
ru_vector = ru_dictionary [ "кот" ]
print ( FastVector . cosine_similarity ( fr_vector , ru_vector ))
# Result should be 0.02Die Kosinus -Ähnlichkeit läuft zwischen -1 und 1. Es scheint, dass "Chat" und "кот" weder ähnlich noch unähnlich sind. Aber jetzt wenden wir die Transformationen an, um die beiden Wörterbücher in einem einzigen Raum auszurichten:
fr_dictionary . apply_transform ( 'alignment_matrices/fr.txt' )
ru_dictionary . apply_transform ( 'alignment_matrices/ru.txt' )Und bewerten Sie die Ähnlichkeit der Cosinus neu:
print ( FastVector . cosine_similarity ( fr_dictionary [ "chat" ], ru_dictionary [ "кот" ]))
# Result should be 0.43Es stellt sich heraus, dass "Chat" und "кот" doch ziemlich ähnlich sind. Das ist gut, da beide "Katze" bedeuten.
Von den 89 von Facebook bereitgestellten Sprachen werden 78 von der Google Translate API unterstützt. Wir haben zuerst die 10.000 häufigsten Wörter im englischen FastText -Vokabular erhalten und dann die API verwendet, um diese Wörter in die verfügbaren 78 verfügbaren Sprachen zu übersetzen. Wir haben diesen Wortschatz in zwei Teile geteilt und dem Trainingswörterbuch die ersten 5000 Wörter und den zweiten 5000 dem Test -Wörterbuch zugewiesen.
Wir haben das Ausrichtungsverfahren in diesem Blog beschrieben. Es dauert zwei Sätze von Wortvektoren und ein kleines zweisprachiges Wörterbuch von Übersetzungspaaren in zwei Sprachen. und erzeugt eine Matrix, die die Quellsprache mit dem Ziel übereinstimmt. Manchmal übersetzt Google ein englisches Wort in einen nicht englischen Satz, in diesen Fällen haben wir die in der Phrase enthaltenen Wortvektoren durchschnittlich.
Um alle 78 Sprachen in einen einzigen Raum zu platzieren, richten wir jede Sprache mit den englischen Vektoren aus (die englische Matrix ist die Identität).
Um zu beweisen, dass das Verfahren funktioniert, können wir die Übersetzungen von Wörtern vorhersagen, die im Trainingswörterbuch nicht zu sehen sind. Der Einfachheit halber prognostizieren wir Übersetzungen der nächsten Nachbarn. Wenn wir beispielsweise "Hund" in Schwedisch übersetzen wollten, würden wir einfach den schwedischen Wortvektor finden, dessen Cosinus -Ähnlichkeit mit dem Wortvektor "Hund" am höchsten ist.
Lassen Sie uns zuerst die Übersetzungsleistung von Englisch in jede andere Sprache testen. Für jedes Sprachpaar extrahieren wir einen Satz von 2500 Wortpaaren aus dem Test -Wörterbuch. Die Präzision @N bezeichnet die Wahrscheinlichkeit, dass die wahre Übersetzung von den 2500 Zielwörtern in diesem Satz einer der Top -N -Nachbarn des Quellworts war. Wenn die Ausrichtung völlig zufällig wäre, würden wir erwarten, dass die Präzision @1 etwa 0,0004 liegt.
| Zielsprache | Präzision @1 | Präzision @5 | Präzision @10 |
|---|---|---|---|
| fr | 0,73 | 0,86 | 0,88 |
| pt | 0,73 | 0,86 | 0,89 |
| es | 0,72 | 0,85 | 0,88 |
| Es | 0,70 | 0,86 | 0,89 |
| nl | 0,68 | 0,83 | 0,86 |
| NEIN | 0,68 | 0,85 | 0,89 |
| da | 0,66 | 0,84 | 0,88 |
| ca. | 0,66 | 0,81 | 0,86 |
| SV | 0,65 | 0,82 | 0,86 |
| CS | 0,64 | 0,81 | 0,85 |
| ro | 0,63 | 0,81 | 0,85 |
| de | 0,62 | 0,75 | 0,78 |
| Pl | 0,62 | 0,79 | 0,83 |
| Hu | 0,61 | 0,80 | 0,84 |
| fi | 0,61 | 0,80 | 0,84 |
| eo | 0,61 | 0,80 | 0,85 |
| Ru | 0,60 | 0,78 | 0,82 |
| GL | 0,60 | 0,77 | 0,82 |
| mk | 0,58 | 0,79 | 0,84 |
| Ausweis | 0,58 | 0,81 | 0,86 |
| BG | 0,57 | 0,77 | 0,82 |
| MS | 0,57 | 0,81 | 0,86 |
| Vereinigtes Königreich | 0,57 | 0,75 | 0,79 |
| Sh | 0,56 | 0,77 | 0,81 |
| HR | 0,56 | 0,75 | 0,80 |
| tr | 0,56 | 0,77 | 0,81 |
| sl | 0,56 | 0,77 | 0,82 |
| El | 0,54 | 0,75 | 0,80 |
| SK | 0,54 | 0,75 | 0,81 |
| ET | 0,53 | 0,73 | 0,78 |
| sr | 0,53 | 0,72 | 0,77 |
| af | 0,52 | 0,75 | 0,80 |
| lt | 0,50 | 0,72 | 0,79 |
| ar | 0,48 | 0,69 | 0,75 |
| BS | 0,47 | 0,70 | 0,77 |
| lv | 0,47 | 0,68 | 0,75 |
| EU | 0,46 | 0,68 | 0,75 |
| Fa | 0,45 | 0,68 | 0,75 |
| hy | 0,43 | 0,66 | 0,73 |
| sq | 0,43 | 0,65 | 0,71 |
| Sei | 0,43 | 0,64 | 0,70 |
| Zh | 0,40 | 0,68 | 0,75 |
| Ka | 0,40 | 0,63 | 0,71 |
| cy | 0,39 | 0,63 | 0,71 |
| Hi | 0,39 | 0,58 | 0,63 |
| AZ | 0,38 | 0,60 | 0,67 |
| ko | 0,37 | 0,58 | 0,66 |
| te | 0,36 | 0,56 | 0,63 |
| KK | 0,35 | 0,60 | 0,68 |
| Er | 0,33 | 0,45 | 0,48 |
| FY | 0,33 | 0,52 | 0,60 |
| vi | 0,31 | 0,53 | 0,62 |
| ta | 0,31 | 0,50 | 0,56 |
| bn | 0,30 | 0,49 | 0,56 |
| ur | 0,29 | 0,52 | 0,61 |
| Ist | 0,29 | 0,51 | 0,59 |
| tl | 0,28 | 0,51 | 0,59 |
| KN | 0,28 | 0,43 | 0,46 |
| Gu | 0,25 | 0,44 | 0,51 |
| mn | 0,25 | 0,49 | 0,58 |
| Uz | 0,24 | 0,43 | 0,51 |
| Si | 0,22 | 0,40 | 0,45 |
| ml | 0,21 | 0,35 | 0,39 |
| Ky | 0,20 | 0,40 | 0,49 |
| Herr | 0,20 | 0,37 | 0,44 |
| th | 0,20 | 0,33 | 0,38 |
| la | 0,19 | 0,34 | 0,42 |
| Ja | 0,18 | 0,44 | 0,56 |
| ne | 0,16 | 0,33 | 0,38 |
| pa | 0,16 | 0,32 | 0,38 |
| tg | 0,14 | 0,31 | 0,39 |
| km | 0,12 | 0,26 | 0,30 |
| Mein | 0,10 | 0,19 | 0,23 |
| lb | 0,09 | 0,18 | 0,21 |
| mg | 0,07 | 0,18 | 0,25 |
| CEB | 0,06 | 0,13 | 0,18 |
Wie Sie sehen können, ist die Ausrichtung durchweg viel besser als zufällig! Im Allgemeinen eignet sich das Verfahren am besten für andere europäische Sprachen wie Französisch, Portugiesisch und Spanisch. Wir verwenden 2500 Word -Paare, da im Test -Wörterbuch 5000 Wörter nicht alle von der Google Translate -API gefundenen Wörter im FastText -Vokabular vorhanden sind.
Lassen Sie uns nun etwas viel aufregenderes tun und die Übersetzungsleistung zwischen allen möglichen Sprachpaaren bewerten. Wir zeigen diese Übersetzungsleistung auf der folgenden Heatmap, wobei die Farbe eines Elements die Präzision @1 bezeichnet, wenn sie aus der Sprache der Zeile in die Sprache der Spalte übersetzt.
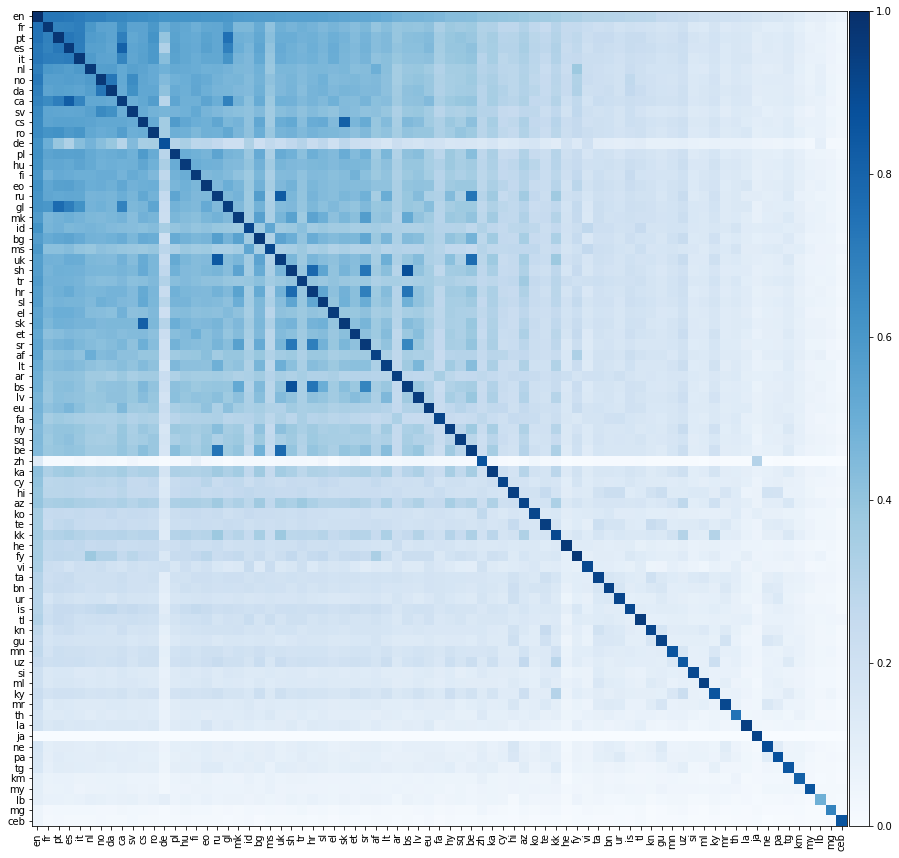
Wir sollten betonen, dass alle Sprachen nur auf Englisch ausgerichtet waren . Wir haben keine Trainingswörterbücher zwischen nicht englischsprachigen Paaren angelegt. Dennoch können wir immer noch erfolgreich Übersetzungen zwischen Paaren von nicht englischen Sprachen vorhersagen.
Wir erwarten, dass die diagonalen Elemente der obigen Matrix 1 sind, da eine Sprache perfekt in sich selbst übersetzen sollte. In der Praxis tritt dies jedoch nicht immer auf, da wir die Trainings- und Testwörterbücher konstruiert haben, indem wir gemeinsame englische Wörter in die anderen Sprachen übersetzt haben. Manchmal übersetzt mehrere englische Wörter das gleiche nicht englische Wort, so dass das gleiche nicht englische Wort im Testsatz mehrmals erscheinen kann. Wir haben dies nicht ordnungsgemäß berücksichtigt, was die Übersetzungsleistung verringert.
Intrikum, obwohl wir die Sprachen nur direkt auf Englisch ausgerichtet haben, übersetzt eine Sprache manchmal besser in eine andere nicht englische Sprache als für Englisch! Wir können die Interpair-Präzision zweier Sprachen berechnen; Die durchschnittliche Präzision von Sprache 1 bis Sprache 2 und umgekehrt. Wir können auch die Präzision des englischen Pairs berechnen; Der Durchschnitt der Präzision von Englisch zu Sprache 1 und von Englisch zu Sprache 2. Im Folgenden werden alle Sprachpaare aufgeführt, für die die Präzision der Interpair die Präzision des englischen Pairs überschreitet:
| Sprache 1 | Sprache 2 | Interpair-Präzision @1 | Englisch-Pair-Präzision @1 |
|---|---|---|---|
| BS | Sh | 0,88 | 0,52 |
| Ru | Vereinigtes Königreich | 0,84 | 0,58 |
| ca. | es | 0,82 | 0,69 |
| CS | SK | 0,82 | 0,59 |
| HR | Sh | 0,78 | 0,56 |
| Sei | Vereinigtes Königreich | 0,77 | 0,50 |
| GL | pt | 0,76 | 0,66 |
| BS | HR | 0,74 | 0,52 |
| Sei | Ru | 0,73 | 0,51 |
| da | NEIN | 0,73 | 0,67 |
| sr | Sh | 0,73 | 0,54 |
| pt | es | 0,72 | 0,72 |
| ca. | pt | 0,70 | 0,69 |
| GL | es | 0,70 | 0,66 |
| HR | sr | 0,69 | 0,54 |
| ca. | GL | 0,68 | 0,63 |
| BS | sr | 0,67 | 0,50 |
| mk | sr | 0,56 | 0,55 |
| KK | Ky | 0,30 | 0,28 |
Alle diese Sprachpaare haben sehr enge sprachliche Wurzeln. Zum Beispiel sind das erste Paar oben bosnisch und serbokroatisch; Bosnian ist eine Variante des Serbo-Kroatischen. Das zweite Paar ist russisch und ukrainisch; Beide Ost-Slavic-Sprachen. Es scheint, dass je mehr zwei Sprachen sind, desto ähnlicher die Geometrie ihrer FastText -Vektoren; was zu einer verbesserten Übersetzungsleistung führt.
Die in diesem Repository bereitgestellten Matrizen sind orthogonal. Intuitiv kann jede Matrix in eine Reihe von Rotationen und Reflexionen unterteilt werden. Rotationen und Reflexionen verändern den Abstand zwischen zwei Punkten in einem Vektorraum nicht. Und folglich wird keiner der inneren Produkte zwischen Wortvektoren innerhalb einer Sprache geändert, nur die inneren Produkte zwischen den Wortvektoren verschiedener Sprachen sind betroffen.
Es gibt eine Reihe großartiger Papiere zu diesem Thema. Wir haben unten einige von ihnen aufgeführt:
Eine Reihe von Lesern hat Interesse an den in diesem Repository verwendeten Schulungs- und Testwörterbüchern zum Ausdruck gebracht. Wir hätten diese gerne hochgeladen, obwohl wir keine Rechtsberatung erhalten hätten, sind wir besorgt, dass dies so interpretiert werden könnte, dass sie die Bedingungen der API von Google Translate übertragen.
Die Transformationsmatrizen werden unter der Creative Commons Attribution-Share-Alike-Lizenz 3.0 verteilt.


