fastText_multilingual
1.0.0
이 저장소 는 더 이상 바빌론 건강에 의해 적극적으로 유지되지 않습니다. 추가 지원을 원하시면 신문 저자에게 연락하십시오.
Facebook은 최근 89 개 언어로 개방형 단어 벡터를 개방했습니다. 그러나이 벡터는 단일 링크입니다. 언어 내에서 유사한 단어가 비슷한 벡터를 공유하지만 다른 언어의 번역 단어에는 비슷한 벡터가 없습니다. ICLR 2017의 최근 논문에서, 우리는 SVD가 단일 벡터 공간의 두 언어로부터 단일 언어 벡터를 정렬하는 선형 변환 (매트릭스)을 학습하는 데 어떻게 사용될 수 있는지 보여 주었다. 이 저장소에서는 78 개의 행렬을 제공하며, 이는 단일 공간에서 FastText 언어의 대부분을 정렬하는 데 사용할 수 있습니다.
이 readme는 행렬을 어떻게 사용 해야하는지 설명합니다. 또한 간단한 평가 작업을 제시합니다. 여기서 우리는 여러 언어로 단어의 변환을 성공적으로 예측할 수 있음을 보여줍니다. 우리의 절차는 단어 쌍의 이중 언어 교육 사전을 두 언어로 수집하는 데 의존하지만, 우리는 교육 사전이없는 언어 쌍 사이의 단어의 번역을 성공적으로 예측할 수 있습니다!
단어 임베딩은 벡터의 정규화 된 내부 생성물에 의해 두 단어 사이의 유사성을 정의합니다. 이 저장소의 매트릭스는 이러한 단일 언어 유사성 관계를 변경하지 않고 단일 공간의 언어를 단일 공간의 언어입니다. 단일 언어 작업에 결과 다국어 벡터를 사용하면 원래 벡터와 정확히 동일하게 수행됩니다. Word Embedding에 대한 자세한 내용은 Colah의 블로그 또는 Sam의 벡터 표현 소개를 확인하십시오.
이 저장소 Facebook을 발표 한 이후 204 개 언어를 추가로 출시했습니다. 그러나 원래 90 개 언어의 단어 벡터는 변경되지 않았 으며이 저장소에서 제공된 변환은 여전히 작동합니다. 자신의 정렬 행렬을 배우려면 align_your_own.ipynb에 예제를 제공합니다.
이 저장소를 사용하는 경우 다음을 인용하십시오.
오프라인 이중 언어 단어 벡터, 직교 변환 및 거꾸로 된 SoftMax
Samuel L. Smith, David HP Turban, Steven Hamblin 및 Nils Y. Hammerla
ICLR 2017 (컨퍼런스 트랙)
이 저장소의 로컬 사본을 복제하고 여기에서 필요한 FastText 벡터를 다운로드하십시오. 프랑스어와 러시아어의 벡터를 텍스트 형식으로 다운로드했다고 가정하겠습니다. "Chat"과 "sto"의 유사성을 비교하고 싶다고 가정 해 봅시다. 우리는 벡터라는 단어를로드합니다.
from fasttext import FastVector
fr_dictionary = FastVector ( vector_file = 'wiki.fr.vec' )
ru_dictionary = FastVector ( vector_file = 'wiki.ru.vec' )벡터라는 단어를 추출하고 코사인 유사성을 계산할 수 있습니다.
fr_vector = fr_dictionary [ "chat" ]
ru_vector = ru_dictionary [ "кот" ]
print ( FastVector . cosine_similarity ( fr_vector , ru_vector ))
# Result should be 0.02코사인 유사성은 -1과 1 사이에서 실행됩니다. "채팅"과 "처스"는 비슷하거나 다르지 않습니다. 그러나 이제 우리는 단일 공간에서 두 사전을 정렬하기 위해 변환을 적용합니다.
fr_dictionary . apply_transform ( 'alignment_matrices/fr.txt' )
ru_dictionary . apply_transform ( 'alignment_matrices/ru.txt' )코사인 유사성을 다시 평가하십시오.
print ( FastVector . cosine_similarity ( fr_dictionary [ "chat" ], ru_dictionary [ "кот" ]))
# Result should be 0.43"채팅"과 "처스"는 결국 매우 비슷합니다. 둘 다 "고양이"를 의미하기 때문에 이것은 좋습니다.
Facebook에서 제공하는 89 개 언어 중 78 개는 Google Translate API에서 지원합니다. 우리는 먼저 영어 FastText 어휘에서 10,000 개의 가장 일반적인 단어를 얻은 다음 API를 사용 하여이 단어를 사용 가능한 78 개 언어로 변환합니다. 우리는이 어휘를 두 개로 나누어 처음 5000 단어를 훈련 사전에, 두 번째 5000을 테스트 사전에 할당합니다.
우리는이 블로그의 정렬 절차를 설명했습니다. 두 개의 단어 벡터 세트와 작은 이중 언어 사전의 번역 쌍이 두 가지 언어로 필요합니다. 소스 언어를 대상과 정렬하는 행렬을 생성합니다. 때로는 Google은 영어 단어를 영어 단어로 번역합니다.이 경우 우리는 문구에 포함 된 벡터라는 단어를 평균화합니다.
78 개 언어를 모두 단일 공간에 배치하기 위해 모든 언어를 영어 벡터에 맞 춥니 다 (영어 행렬은 정체성이다).
절차가 작동한다는 것을 증명하기 위해 훈련 사전에서 보이지 않는 단어의 번역을 예측할 수 있습니다. 단순화를 위해 우리는 가장 가까운 이웃의 번역을 예측합니다. 예를 들어, "개"를 스웨덴어로 번역하고 싶다면 "개"단어 벡터와 코사인 유사성이 가장 높은 스웨덴어 벡터를 찾을 수 있습니다.
먼저, 영어에서 다른 모든 언어로 번역 성능을 테스트합시다. 각 언어 쌍에 대해 테스트 사전에서 2500 단어 쌍 세트를 추출합니다. 정밀 @N 은이 세트의 2500 개의 대상 단어 중 실제 번역이 소스 단어의 가장 가까운 이웃 중 하나 일 확률을 나타냅니다. 정렬이 완전히 무작위 인 경우 정밀 @1이 약 0.0004가 될 것으로 예상됩니다.
| 대상 언어 | 정밀 @1 | 정밀 @5 | 정밀 @10 |
|---|---|---|---|
| 정말로 | 0.73 | 0.86 | 0.88 |
| Pt | 0.73 | 0.86 | 0.89 |
| es | 0.72 | 0.85 | 0.88 |
| 그것 | 0.70 | 0.86 | 0.89 |
| NL | 0.68 | 0.83 | 0.86 |
| 아니요 | 0.68 | 0.85 | 0.89 |
| 다 | 0.66 | 0.84 | 0.88 |
| CA | 0.66 | 0.81 | 0.86 |
| SV | 0.65 | 0.82 | 0.86 |
| CS | 0.64 | 0.81 | 0.85 |
| 로 | 0.63 | 0.81 | 0.85 |
| 드 | 0.62 | 0.75 | 0.78 |
| Pl | 0.62 | 0.79 | 0.83 |
| hu | 0.61 | 0.80 | 0.84 |
| fi | 0.61 | 0.80 | 0.84 |
| EO | 0.61 | 0.80 | 0.85 |
| ru | 0.60 | 0.78 | 0.82 |
| GL | 0.60 | 0.77 | 0.82 |
| MK | 0.58 | 0.79 | 0.84 |
| ID | 0.58 | 0.81 | 0.86 |
| BG | 0.57 | 0.77 | 0.82 |
| MS | 0.57 | 0.81 | 0.86 |
| 영국 | 0.57 | 0.75 | 0.79 |
| 쉿 | 0.56 | 0.77 | 0.81 |
| HR | 0.56 | 0.75 | 0.80 |
| Tr | 0.56 | 0.77 | 0.81 |
| SL | 0.56 | 0.77 | 0.82 |
| 엘자 | 0.54 | 0.75 | 0.80 |
| SK | 0.54 | 0.75 | 0.81 |
| et | 0.53 | 0.73 | 0.78 |
| SR | 0.53 | 0.72 | 0.77 |
| AF | 0.52 | 0.75 | 0.80 |
| LT | 0.50 | 0.72 | 0.79 |
| AR | 0.48 | 0.69 | 0.75 |
| BS | 0.47 | 0.70 | 0.77 |
| LV | 0.47 | 0.68 | 0.75 |
| EU | 0.46 | 0.68 | 0.75 |
| 파 | 0.45 | 0.68 | 0.75 |
| hy | 0.43 | 0.66 | 0.73 |
| 평방 | 0.43 | 0.65 | 0.71 |
| BE | 0.43 | 0.64 | 0.70 |
| ZH | 0.40 | 0.68 | 0.75 |
| 카 | 0.40 | 0.63 | 0.71 |
| CY | 0.39 | 0.63 | 0.71 |
| 안녕 | 0.39 | 0.58 | 0.63 |
| AZ | 0.38 | 0.60 | 0.67 |
| 코 | 0.37 | 0.58 | 0.66 |
| 테 | 0.36 | 0.56 | 0.63 |
| KK | 0.35 | 0.60 | 0.68 |
| 그 | 0.33 | 0.45 | 0.48 |
| FY | 0.33 | 0.52 | 0.60 |
| VI | 0.31 | 0.53 | 0.62 |
| 고마워 | 0.31 | 0.50 | 0.56 |
| Bn | 0.30 | 0.49 | 0.56 |
| ur | 0.29 | 0.52 | 0.61 |
| ~이다 | 0.29 | 0.51 | 0.59 |
| TL | 0.28 | 0.51 | 0.59 |
| kn | 0.28 | 0.43 | 0.46 |
| 구 | 0.25 | 0.44 | 0.51 |
| MN | 0.25 | 0.49 | 0.58 |
| UZ | 0.24 | 0.43 | 0.51 |
| 시 | 0.22 | 0.40 | 0.45 |
| ML | 0.21 | 0.35 | 0.39 |
| ky | 0.20 | 0.40 | 0.49 |
| ~ 씨 | 0.20 | 0.37 | 0.44 |
| th | 0.20 | 0.33 | 0.38 |
| 라 | 0.19 | 0.34 | 0.42 |
| 자 | 0.18 | 0.44 | 0.56 |
| NE | 0.16 | 0.33 | 0.38 |
| 아빠 | 0.16 | 0.32 | 0.38 |
| tg | 0.14 | 0.31 | 0.39 |
| km | 0.12 | 0.26 | 0.30 |
| 나의 | 0.10 | 0.19 | 0.23 |
| LB | 0.09 | 0.18 | 0.21 |
| Mg | 0.07 | 0.18 | 0.25 |
| CEB | 0.06 | 0.13 | 0.18 |
보시다시피, 정렬은 무작위보다 일관되게 훨씬 낫습니다! 일반적 으로이 절차는 프랑스어, 포르투갈어 및 스페인어와 같은 다른 유럽 언어에 가장 적합합니다. Google Translate API가 발견 한 모든 단어가 실제로 FastText 어휘에 존재하는 것은 아닙니다.
이제 훨씬 더 흥미로운 일을하겠습니다. 가능한 모든 언어 쌍 사이의 번역 성능을 평가해 봅시다. 우리는 아래의 열도 에서이 번역 성능을 보여줍니다. 여기서 요소의 색상은 행 언어에서 열의 언어로 변환 할 때 정밀 @1을 나타냅니다.
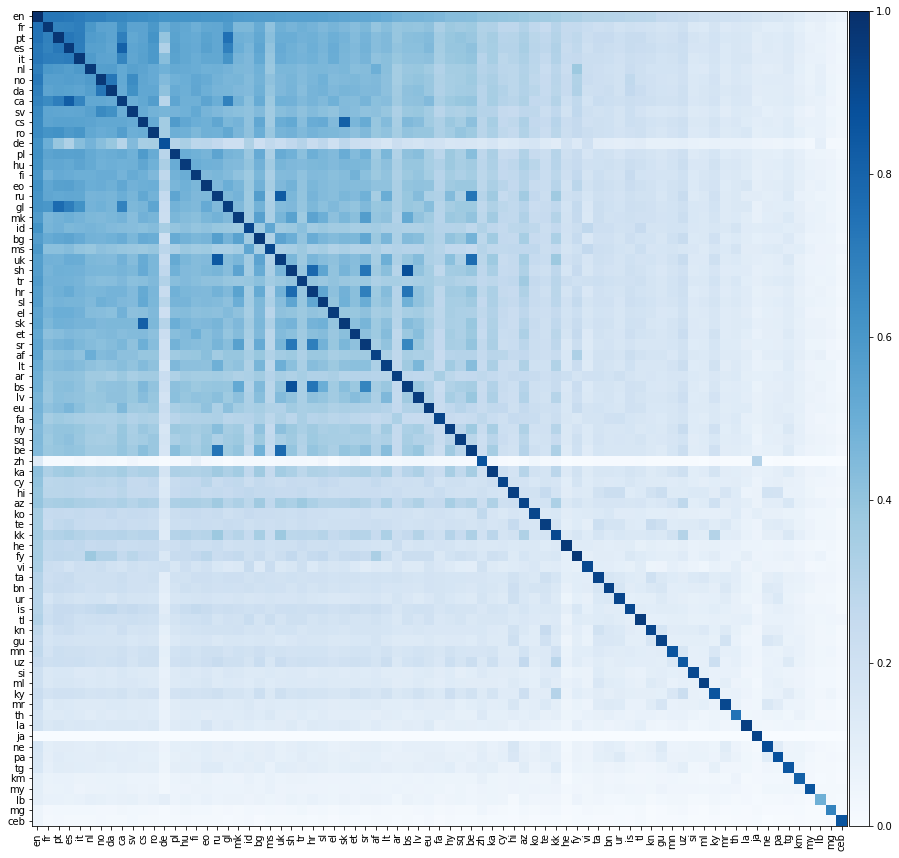
우리는 모든 언어가 영어로만 정렬되었음을 강조해야합니다. 우리는 영어가 아닌 언어 쌍 사이에 교육 사전을 제공하지 않았습니다. 그러나 우리는 여전히 영어 이외의 언어 쌍 사이의 번역을 매우 정확하게 예측할 수 있습니다.
언어는 그 자체로 완벽하게 번역되어야하기 때문에 위의 매트릭스의 대각선 요소는 1이 될 것으로 기대합니다. 그러나 실제로는 일반적인 영어 단어를 다른 언어로 번역하여 훈련 및 테스트 사전을 구성했기 때문에 이것이 항상 발생하는 것은 아닙니다. 때로는 여러 개의 영어 단어가 동일한 영어 단어로 번역되므로 시험 세트에서 동일한 비 영어 단어가 여러 번 나타날 수 있습니다. 우리는 이것을 제대로 설명하지 않았으므로 번역 성능이 줄어 듭니다.
깔끔하게, 우리는 언어를 영어로 직접 정렬했지만 때로는 언어가 영어보다 다른 비 영어 언어로 더 잘 해석됩니다! 우리는 두 언어의 쌍 쌍 정밀도를 계산할 수 있습니다. 언어 1에서 언어 2, 그 반대의 평균 정밀도. 우리는 또한 영어 쌍 정밀도를 계산할 수 있습니다. 영어에서 언어 1 및 영어로의 정밀도의 평균 2. 아래에서는 쌍 쌍 정밀도가 영어 쌍의 정밀도를 초과하는 모든 언어 쌍을 나열합니다.
| 언어 1 | 언어 2 | 상호 쌍 정밀 @1 | 영어 쌍 정밀 @1 |
|---|---|---|---|
| BS | 쉿 | 0.88 | 0.52 |
| ru | 영국 | 0.84 | 0.58 |
| CA | es | 0.82 | 0.69 |
| CS | SK | 0.82 | 0.59 |
| HR | 쉿 | 0.78 | 0.56 |
| BE | 영국 | 0.77 | 0.50 |
| GL | Pt | 0.76 | 0.66 |
| BS | HR | 0.74 | 0.52 |
| BE | ru | 0.73 | 0.51 |
| 다 | 아니요 | 0.73 | 0.67 |
| SR | 쉿 | 0.73 | 0.54 |
| Pt | es | 0.72 | 0.72 |
| CA | Pt | 0.70 | 0.69 |
| GL | es | 0.70 | 0.66 |
| HR | SR | 0.69 | 0.54 |
| CA | GL | 0.68 | 0.63 |
| BS | SR | 0.67 | 0.50 |
| MK | SR | 0.56 | 0.55 |
| KK | ky | 0.30 | 0.28 |
이 모든 언어 쌍은 매우 가까운 언어 뿌리를 공유합니다. 예를 들어 위의 첫 번째 쌍은 보스니아와 세르보-크로아티아입니다. Bosnian은 Serbo-Croatian의 변형입니다. 두 번째 쌍은 러시아와 우크라이나 인입니다. 두 동력 언어. 두 언어가 비슷할수록 FastText 벡터의 형상이 비슷합니다. 번역 성능을 향상시킵니다.
이 저장소에 제공된 매트릭스는 직교입니다. 직관적으로, 각 매트릭스는 일련의 회전과 반사로 분해 될 수 있습니다. 회전과 반사는 벡터 공간의 두 지점 사이의 거리를 변경하지 않습니다. 결과적으로 언어 내에서 단어 벡터 사이의 내부 제품 중 어느 것도 변경되지 않았으며, 다른 언어의 벡터라는 단어 사이의 내부 제품 만 영향을받습니다.
이 주제에 대한 많은 훌륭한 논문이 있습니다. 아래에 몇 가지를 나열했습니다.
많은 독자 들이이 저장소에서 사용한 교육 및 테스트 사전에 관심을 표명했습니다. 그러나 우리는 이것들을 업로드하고 싶었지만 법적 조언을받지는 않았지만 이것이 Google Translate API의 조건을 깨뜨리는 것으로 해석 될 수 있다고 우려합니다.
변환 매트릭스는 Creative Commons Attribution-Share-Alike License 3.0 에 배포됩니다.


