fastText_multilingual
1.0.0
หมายเหตุที่ เก็บนี้ไม่ได้รับการดูแลอย่างแข็งขันโดย Babylon Health อีกต่อไป สำหรับความช่วยเหลือเพิ่มเติมให้ติดต่อผู้เขียนกระดาษ
Facebook เมื่อเร็ว ๆ นี้เวกเตอร์ Word ที่เปิดแหล่งที่มาใน 89 ภาษา อย่างไรก็ตามเวกเตอร์เหล่านี้เป็นภาษาเดียว หมายความว่าในขณะที่คำที่คล้ายกันภายในภาษาแบ่งปันเวกเตอร์ที่คล้ายกันคำแปลจากภาษาต่าง ๆ ไม่มีเวกเตอร์ที่คล้ายกัน ในบทความล่าสุดที่ ICLR 2017 เราแสดงให้เห็นว่า SVD สามารถใช้เพื่อเรียนรู้การเปลี่ยนแปลงเชิงเส้น (เมทริกซ์) ซึ่งจัดแนวเวกเตอร์แบบ monolingual จากสองภาษาในพื้นที่เวกเตอร์เดียว ในที่เก็บนี้เรามีเมทริกซ์ 78 เมทริกซ์ซึ่งสามารถใช้เพื่อจัดแนวภาษา fasttext ส่วนใหญ่ในพื้นที่เดียว
readme นี้อธิบายถึงวิธีการใช้เมทริกซ์ นอกจากนี้เรายังนำเสนองานการประเมินอย่างง่าย ๆ ซึ่งเราแสดงให้เห็นว่าเราสามารถทำนายการแปลคำในหลายภาษาได้สำเร็จ ขั้นตอนของเราขึ้นอยู่กับการรวบรวมพจนานุกรมการฝึกอบรมสองภาษาของคู่คำในสองภาษา แต่อย่างน่าทึ่งเราสามารถทำนายการแปลคำระหว่างคู่ภาษาที่เราไม่มีพจนานุกรมฝึกอบรมได้สำเร็จ!
คำที่ฝังตัวกำหนดความคล้ายคลึงกันระหว่างสองคำโดยผลิตภัณฑ์ภายในที่ปรับให้เป็นมาตรฐานของเวกเตอร์ของพวกเขา เมทริกซ์ในพื้นที่เก็บข้อมูลนี้วางภาษาในพื้นที่เดียว โดยไม่ต้องเปลี่ยนความสัมพันธ์ที่คล้ายคลึงกันแบบ monolingual เหล่านี้ เมื่อคุณใช้เวกเตอร์หลายภาษาที่เกิดขึ้นสำหรับงานภาษาเดียวพวกเขาจะทำงานเหมือนกับเวกเตอร์ดั้งเดิม หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับการฝังคำให้ตรวจสอบบล็อกของ Colah หรือการแนะนำของ Sam เกี่ยวกับการเป็นตัวแทนเวกเตอร์
โปรดทราบว่าตั้งแต่เราเปิดตัว Facebook ที่เก็บนี้ได้เปิดตัวอีก 204 ภาษา อย่างไรก็ตามคำว่าเวกเตอร์ของ 90 ภาษาดั้งเดิมไม่เปลี่ยนแปลงและการแปลงที่ให้ไว้ในที่เก็บนี้จะยังคงทำงานอยู่ หากคุณต้องการเรียนรู้เมทริกซ์การจัดตำแหน่งของคุณเองเราให้ตัวอย่างใน Align_your_own.ipynb
หากคุณใช้ที่เก็บนี้โปรดอ้างอิง:
เวกเตอร์คำสองภาษาออฟไลน์การแปลงแบบมุมฉากและ softmax คว่ำกลับ
Samuel L. Smith, David HP Turban, Steven Hamblin และ Nils Y. Hammerla
ICLR 2017 (ติดตามการประชุม)
โคลนสำเนาท้องถิ่นของพื้นที่เก็บข้อมูลนี้และดาวน์โหลดเวกเตอร์ fasttext ที่คุณต้องการจากที่นี่ ฉันจะสมมติว่าคุณดาวน์โหลดเวกเตอร์สำหรับฝรั่งเศสและรัสเซียในรูปแบบข้อความ สมมติว่าเราต้องการเปรียบเทียบความคล้ายคลึงกันของ "แชท" และ "кот" เราโหลดคำว่าเวกเตอร์:
from fasttext import FastVector
fr_dictionary = FastVector ( vector_file = 'wiki.fr.vec' )
ru_dictionary = FastVector ( vector_file = 'wiki.ru.vec' )เราสามารถแยกคำว่าเวกเตอร์และคำนวณความคล้ายคลึงกันของโคไซน์:
fr_vector = fr_dictionary [ "chat" ]
ru_vector = ru_dictionary [ "кот" ]
print ( FastVector . cosine_similarity ( fr_vector , ru_vector ))
# Result should be 0.02ความคล้ายคลึงกันของโคไซน์ทำงานระหว่าง -1 ถึง 1 ดูเหมือนว่า "แชท" และ "кот" ไม่คล้ายกันหรือแตกต่างกัน แต่ตอนนี้เราใช้การเปลี่ยนแปลงเพื่อจัดพจนานุกรมทั้งสองในพื้นที่เดียว:
fr_dictionary . apply_transform ( 'alignment_matrices/fr.txt' )
ru_dictionary . apply_transform ( 'alignment_matrices/ru.txt' )และประเมินความคล้ายคลึงกันของโคไซน์อีกครั้ง:
print ( FastVector . cosine_similarity ( fr_dictionary [ "chat" ], ru_dictionary [ "кот" ]))
# Result should be 0.43ปรากฎว่า "แชท" และ "кот" นั้นค่อนข้างคล้ายกัน นี่เป็นสิ่งที่ดีเนื่องจากพวกเขาทั้งคู่หมายถึง "แมว"
จาก 89 ภาษาที่จัดทำโดย Facebook 78 ได้รับการสนับสนุนโดย Google Translate API ก่อนอื่นเราได้รับ 10,000 คำที่พบบ่อยที่สุดในคำศัพท์ภาษาอังกฤษ fasttext จากนั้นใช้ API เพื่อแปลคำเหล่านี้เป็น 78 ภาษาที่มีอยู่ เราแยกคำศัพท์นี้เป็นสองคำโดยกำหนด 5000 คำแรกให้กับพจนานุกรมการฝึกอบรมและ 5,000 ครั้งที่สองให้กับพจนานุกรมทดสอบ
เราอธิบายขั้นตอนการจัดตำแหน่งในบล็อกนี้ ต้องใช้เวกเตอร์คำสองชุดและพจนานุกรมสองภาษาของคู่การแปลในสองภาษา และสร้างเมทริกซ์ที่จัดเรียงภาษาต้นทางกับเป้าหมาย บางครั้ง Google แปลคำภาษาอังกฤษเป็นวลีที่ไม่ใช่ภาษาอังกฤษในกรณีเหล่านี้เราเฉลี่ยคำว่าเวกเตอร์ที่มีอยู่ในวลี
ในการวางทั้ง 78 ภาษาในพื้นที่เดียว เราจัดเรียงทุกภาษาให้เป็นเวกเตอร์ภาษาอังกฤษ (เมทริกซ์ภาษาอังกฤษเป็นตัวตน)
เพื่อพิสูจน์ว่ากระบวนการทำงานเราสามารถทำนายการแปลของคำที่ไม่เห็นในพจนานุกรมการฝึกอบรม เพื่อความเรียบง่ายเราทำนายการแปลโดยเพื่อนบ้านที่ใกล้ที่สุด ตัวอย่างเช่นถ้าเราต้องการแปล "สุนัข" เป็นภาษาสวีเดนเราก็จะพบเวกเตอร์คำภาษาสวีเดนที่มีความคล้ายคลึงกันกับ "สุนัข" คำว่า "สุนัข" สูงสุด
ก่อนอื่นมาทดสอบประสิทธิภาพการแปลจากภาษาอังกฤษเป็นภาษาอื่น ๆ สำหรับคู่ภาษาแต่ละคู่เราจะแยกชุดคู่ 2,500 คำจากพจนานุกรมทดสอบ ความแม่นยำ @N หมายถึงความน่าจะเป็นที่ของคำเป้าหมาย 2,500 คำในชุดนี้การแปลที่แท้จริงเป็นหนึ่งในเพื่อนบ้านที่ใกล้ที่สุดและเพื่อนบ้านที่ใกล้ที่สุดของคำแหล่งที่มา หากการจัดตำแหน่งนั้นสุ่มอย่างสมบูรณ์เราคาดว่าความแม่นยำ @1 จะอยู่ที่ประมาณ 0.0004
| ภาษาเป้าหมาย | ความแม่นยำ @1 | ความแม่นยำ @5 | ความแม่นยำ @10 |
|---|---|---|---|
| FR | 0.73 | 0.86 | 0.88 |
| PT | 0.73 | 0.86 | 0.89 |
| ES | 0.72 | 0.85 | 0.88 |
| มัน | 0.70 | 0.86 | 0.89 |
| NL | 0.68 | 0.83 | 0.86 |
| เลขที่ | 0.68 | 0.85 | 0.89 |
| ดา | 0.66 | 0.84 | 0.88 |
| แคลิฟอร์เนีย | 0.66 | 0.81 | 0.86 |
| SV | 0.65 | 0.82 | 0.86 |
| CS | 0.64 | 0.81 | 0.85 |
| RO | 0.63 | 0.81 | 0.85 |
| เดอ | 0.62 | 0.75 | 0.78 |
| PL | 0.62 | 0.79 | 0.83 |
| หู | 0.61 | 0.80 | 0.84 |
| FI | 0.61 | 0.80 | 0.84 |
| EO | 0.61 | 0.80 | 0.85 |
| ร. | 0.60 | 0.78 | 0.82 |
| GL | 0.60 | 0.77 | 0.82 |
| MK | 0.58 | 0.79 | 0.84 |
| รหัสประจำตัว | 0.58 | 0.81 | 0.86 |
| BG | 0.57 | 0.77 | 0.82 |
| MS | 0.57 | 0.81 | 0.86 |
| สหราชอาณาจักร | 0.57 | 0.75 | 0.79 |
| SH | 0.56 | 0.77 | 0.81 |
| ชั่วโมง | 0.56 | 0.75 | 0.80 |
| TR | 0.56 | 0.77 | 0.81 |
| SL | 0.56 | 0.77 | 0.82 |
| เอล | 0.54 | 0.75 | 0.80 |
| SK | 0.54 | 0.75 | 0.81 |
| ET | 0.53 | 0.73 | 0.78 |
| SR | 0.53 | 0.72 | 0.77 |
| แอม | 0.52 | 0.75 | 0.80 |
| lt | 0.50 | 0.72 | 0.79 |
| อาร์ | 0.48 | 0.69 | 0.75 |
| BS | 0.47 | 0.70 | 0.77 |
| LV | 0.47 | 0.68 | 0.75 |
| สหภาพยุโรป | 0.46 | 0.68 | 0.75 |
| เอฟเอ | 0.45 | 0.68 | 0.75 |
| HY | 0.43 | 0.66 | 0.73 |
| ต. | 0.43 | 0.65 | 0.71 |
| เป็น | 0.43 | 0.64 | 0.70 |
| zh | 0.40 | 0.68 | 0.75 |
| Ka | 0.40 | 0.63 | 0.71 |
| ปัสสาวะ | 0.39 | 0.63 | 0.71 |
| สวัสดี | 0.39 | 0.58 | 0.63 |
| AZ | 0.38 | 0.60 | 0.67 |
| โค | 0.37 | 0.58 | 0.66 |
| เต่าทอง | 0.36 | 0.56 | 0.63 |
| KK | 0.35 | 0.60 | 0.68 |
| เขา | 0.33 | 0.45 | 0.48 |
| ปีงบประมาณ | 0.33 | 0.52 | 0.60 |
| VI | 0.31 | 0.53 | 0.62 |
| TA | 0.31 | 0.50 | 0.56 |
| พันล้าน | 0.30 | 0.49 | 0.56 |
| เอ่อ | 0.29 | 0.52 | 0.61 |
| เป็น | 0.29 | 0.51 | 0.59 |
| TL | 0.28 | 0.51 | 0.59 |
| KN | 0.28 | 0.43 | 0.46 |
| กู | 0.25 | 0.44 | 0.51 |
| MN | 0.25 | 0.49 | 0.58 |
| อุซ | 0.24 | 0.43 | 0.51 |
| ศรี | 0.22 | 0.40 | 0.45 |
| มล. | 0.21 | 0.35 | 0.39 |
| KY | 0.20 | 0.40 | 0.49 |
| นาย | 0.20 | 0.37 | 0.44 |
| ไทย | 0.20 | 0.33 | 0.38 |
| ลา | 0.19 | 0.34 | 0.42 |
| จา | 0.18 | 0.44 | 0.56 |
| NE | 0.16 | 0.33 | 0.38 |
| PA | 0.16 | 0.32 | 0.38 |
| TG | 0.14 | 0.31 | 0.39 |
| กม. | 0.12 | 0.26 | 0.30 |
| ของฉัน | 0.10 | 0.19 | 0.23 |
| ปอนด์ | 0.09 | 0.18 | 0.21 |
| มก. | 0.07 | 0.18 | 0.25 |
| Ceb | 0.06 | 0.13 | 0.18 |
อย่างที่คุณเห็นการจัดตำแหน่งนั้นดีกว่าการสุ่มอย่างสม่ำเสมอ! โดยทั่วไปขั้นตอนนี้ทำงานได้ดีที่สุดสำหรับภาษายุโรปอื่น ๆ เช่นฝรั่งเศสโปรตุเกสและสเปน เราใช้คู่ 2,500 คำเนื่องจาก 5000 คำในพจนานุกรมทดสอบไม่ใช่คำทั้งหมดที่พบโดย Google Translate API นั้นมีอยู่จริงในคำศัพท์ FastText
ตอนนี้เรามาทำอะไรที่น่าตื่นเต้นมากขึ้นลองประเมินประสิทธิภาพการแปลระหว่างคู่ภาษาที่เป็นไปได้ทั้งหมด เราแสดงประสิทธิภาพการแปลนี้บนแผนที่ความร้อนด้านล่างซึ่งสีขององค์ประกอบแสดงถึงความแม่นยำ @1 เมื่อแปลจากภาษาของแถวเป็นภาษาของคอลัมน์
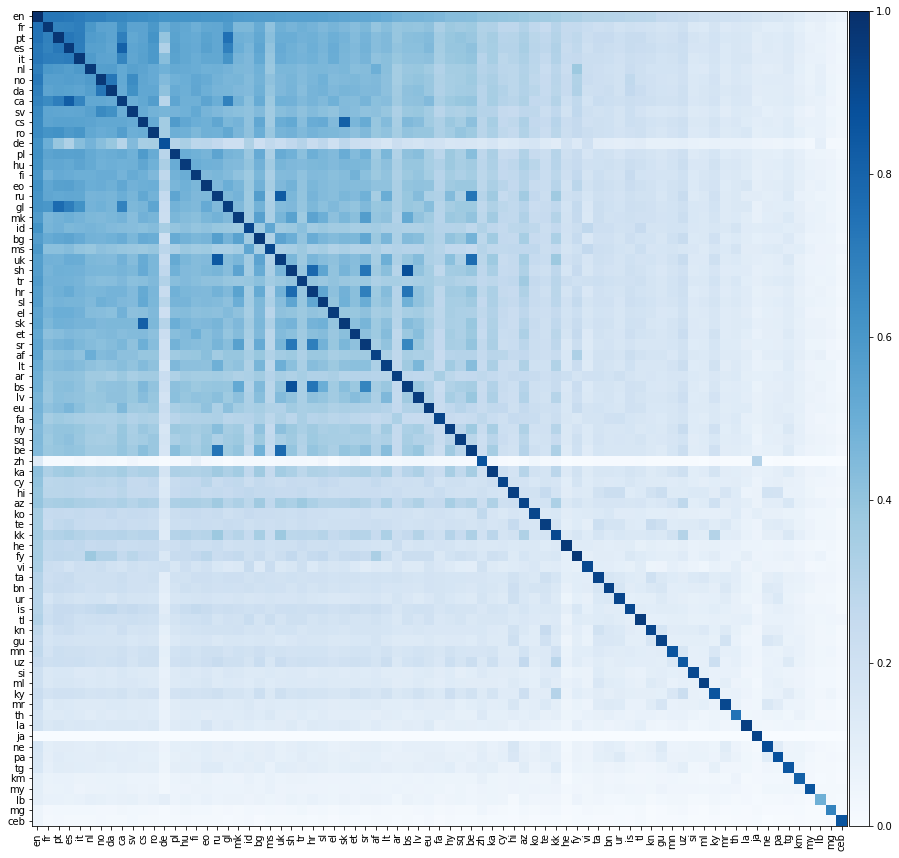
เราควรเน้นว่า ทุกภาษานั้นสอดคล้องกับภาษาอังกฤษเท่านั้น เราไม่ได้ให้พจนานุกรมการฝึกอบรมระหว่างคู่ภาษาที่ไม่ใช่ภาษาอังกฤษ แต่เรายังสามารถทำนายการแปลระหว่างคู่ของภาษาที่ไม่ใช่ภาษาอังกฤษได้อย่างแม่นยำอย่างน่าทึ่ง
เราคาดหวังว่าองค์ประกอบในแนวทแยงของเมทริกซ์ด้านบนจะเป็น 1 เนื่องจากภาษาควรแปลได้อย่างสมบูรณ์แบบ อย่างไรก็ตามในทางปฏิบัติสิ่งนี้ไม่ได้เกิดขึ้นเสมอไปเพราะเราสร้างพจนานุกรมการฝึกอบรมและทดสอบโดยการแปลคำภาษาอังกฤษทั่วไปเป็นภาษาอื่น ๆ บางครั้งคำภาษาอังกฤษหลายคำแปลเป็นคำที่ไม่ใช่ภาษาอังกฤษเดียวกันดังนั้นคำที่ไม่ใช่ภาษาอังกฤษแบบเดียวกันอาจปรากฏขึ้นหลายครั้งในชุดทดสอบ เราไม่ได้คิดอย่างถูกต้องซึ่งจะช่วยลดประสิทธิภาพการแปล
แม้ว่าเราจะจัดเรียงภาษาเป็นภาษาอังกฤษโดยตรง แต่บางครั้งภาษาก็แปลได้ดีกว่าภาษาที่ไม่ใช่ภาษาอังกฤษอื่นมากกว่าภาษาอังกฤษ! เราสามารถคำนวณความแม่นยำระหว่างคู่ของสองภาษา ความแม่นยำเฉลี่ยจากภาษา 1 ถึงภาษา 2 และในทางกลับกัน นอกจากนี้เรายังสามารถคำนวณความแม่นยำของคู่ภาษาอังกฤษได้ ค่าเฉลี่ยของความแม่นยำจากภาษาอังกฤษเป็นภาษา 1 และจากภาษาอังกฤษเป็นภาษา 2. ด้านล่างเราแสดงรายการคู่ภาษาทั้งหมดที่ความแม่นยำระหว่างคู่เกินความแม่นยำของคู่ภาษาอังกฤษ:
| ภาษา 1 | ภาษา 2 | ความแม่นยำระหว่างคู่ @1 | ความแม่นยำคู่ภาษาอังกฤษ @1 |
|---|---|---|---|
| BS | SH | 0.88 | 0.52 |
| ร. | สหราชอาณาจักร | 0.84 | 0.58 |
| แคลิฟอร์เนีย | ES | 0.82 | 0.69 |
| CS | SK | 0.82 | 0.59 |
| ชั่วโมง | SH | 0.78 | 0.56 |
| เป็น | สหราชอาณาจักร | 0.77 | 0.50 |
| GL | PT | 0.76 | 0.66 |
| BS | ชั่วโมง | 0.74 | 0.52 |
| เป็น | ร. | 0.73 | 0.51 |
| ดา | เลขที่ | 0.73 | 0.67 |
| SR | SH | 0.73 | 0.54 |
| PT | ES | 0.72 | 0.72 |
| แคลิฟอร์เนีย | PT | 0.70 | 0.69 |
| GL | ES | 0.70 | 0.66 |
| ชั่วโมง | SR | 0.69 | 0.54 |
| แคลิฟอร์เนีย | GL | 0.68 | 0.63 |
| BS | SR | 0.67 | 0.50 |
| MK | SR | 0.56 | 0.55 |
| KK | KY | 0.30 | 0.28 |
คู่ภาษาทั้งหมดเหล่านี้แบ่งปันรากภาษาที่ใกล้ชิดมาก ตัวอย่างเช่นคู่แรกด้านบนคือบอสเนียและเซอร์โบ-โครเอเชีย; บอสเนียเป็นตัวแปรของเซอร์โบ-โครเอเชีย คู่ที่สองคือรัสเซียและยูเครน ทั้งภาษาตะวันออก-สลาฟ ดูเหมือนว่ายิ่งมีสองภาษาที่คล้ายกันมากเท่าไหร่เรขาคณิตก็ยิ่งคล้ายกันมากขึ้นเรขาคณิตของเวกเตอร์ fasttext; นำไปสู่ประสิทธิภาพการแปลที่ดีขึ้น
เมทริกซ์ที่ให้ไว้ในที่เก็บนี้เป็นมุมฉาก โดยสังหรณ์ใจแต่ละเมทริกซ์สามารถแบ่งออกเป็นชุดของการหมุนและการสะท้อนกลับ การหมุนและการสะท้อนกลับไม่เปลี่ยนระยะห่างระหว่างสองจุดใด ๆ ในพื้นที่เวกเตอร์ และดังนั้นจึงไม่มีผลิตภัณฑ์ภายในระหว่างเวคเตอร์คำภายในภาษาที่มีการเปลี่ยนแปลงเฉพาะผลิตภัณฑ์ภายในระหว่างคำว่าเวกเตอร์ของภาษาที่แตกต่างกันเท่านั้นที่ได้รับผลกระทบ
มีเอกสารที่ยอดเยี่ยมมากมายในหัวข้อนี้ เราได้ระบุไว้สองสามรายการด้านล่าง:
ผู้อ่านจำนวนหนึ่งแสดงความสนใจในพจนานุกรมการฝึกอบรมและทดสอบที่เราใช้ในที่เก็บนี้ อย่างไรก็ตามเราชอบที่จะอัปโหลดสิ่งเหล่านี้อย่างไรก็ตามในขณะที่เราไม่ได้รับคำแนะนำทางกฎหมายเรามีความกังวลว่าสิ่งนี้สามารถตีความได้ว่าเป็นการทำลายเงื่อนไขของ Google Translate API
เมทริกซ์การแปลงจะถูกแจกจ่ายภายใต้ Creative Commons Attribution-Share-Share-arike License 3.0


