fastText_multilingual
1.0.0
Observe que este repositório não é mais mantido ativamente pela Babylon Health. Para obter mais assistência, entre em contato com os autores do artigo.
Facebook recentemente vetores de palavras de origem aberta em 89 idiomas. No entanto, esses vetores são monolíngues; Significando que, embora palavras semelhantes em um idioma compartilhem vetores semelhantes, as palavras de tradução de diferentes idiomas não têm vetores semelhantes. Em um artigo recente no ICLR 2017, mostramos como o SVD pode ser usado para aprender uma transformação linear (uma matriz), que alinha vetores monolíngues de duas línguas em um único espaço vetorial. Neste repositório, fornecemos 78 matrizes, que podem ser usadas para alinhar a maioria dos idiomas FastText em um único espaço.
Este readme explica como as matrizes devem ser usadas. Também apresentamos uma tarefa de avaliação simples, onde mostramos que somos capazes de prever com sucesso as traduções de palavras em vários idiomas. Nosso procedimento depende da coleta de dicionários de treinamento bilíngue de pares de palavras em dois idiomas, mas notavelmente somos capazes de prever com sucesso as traduções de palavras entre pares de idiomas para os quais não tivemos dicionário de treinamento!
As incorporações de palavras definem a semelhança entre duas palavras pelo produto interno normalizado de seus vetores. As matrizes nesse repositório colocam idiomas em um único espaço, sem alterar nenhuma dessas relações monolíngues de similaridade . Quando você usa os vetores multilíngues resultantes para tarefas monolíngues, eles executam exatamente o mesmo que os vetores originais. Para saber mais sobre incorporações de palavras, confira o blog de Colah ou a introdução de Sam às representações vetoriais.
Observe que desde que lançamos este repositório Facebook lançou 204 idiomas adicionais; No entanto, a palavra vetores dos 90 idiomas originais não mudaram, e as transformações fornecidas neste repositório ainda funcionarão. Se você deseja aprender suas próprias matrizes de alinhamento, fornecemos um exemplo em align_your_own.ipynb.
Se você usar este repositório, cite:
Vetores de palavras bilíngues offline, transformações ortogonais e o softmax invertido
Samuel L. Smith, David HP Turban, Steven Hamblin e Nils Y. Hammerla
ICLR 2017 (pista de conferência)
Clone uma cópia local deste repositório e faça o download dos vetores FastText que você precisa daqui. Vou assumir que você baixou os vetores para francês e russo no formato de texto. Digamos que queremos comparar a semelhança de "Chat" e "ко". Carregamos a palavra vetores:
from fasttext import FastVector
fr_dictionary = FastVector ( vector_file = 'wiki.fr.vec' )
ru_dictionary = FastVector ( vector_file = 'wiki.ru.vec' )Podemos extrair a palavra vetores e calcular sua similaridade de cosseno:
fr_vector = fr_dictionary [ "chat" ]
ru_vector = ru_dictionary [ "кот" ]
print ( FastVector . cosine_similarity ( fr_vector , ru_vector ))
# Result should be 0.02A similaridade de cosseno funciona entre -1 e 1. Parece que "Chat" e "ко" não são semelhantes nem diferentes. Mas agora aplicamos as transformações para alinhar os dois dicionários em um único espaço:
fr_dictionary . apply_transform ( 'alignment_matrices/fr.txt' )
ru_dictionary . apply_transform ( 'alignment_matrices/ru.txt' )E reavaliar a similaridade de cosseno:
print ( FastVector . cosine_similarity ( fr_dictionary [ "chat" ], ru_dictionary [ "кот" ]))
# Result should be 0.43Acontece que "Chat" e "ко" são bem parecidos, afinal. Isso é bom, já que ambos significam "gato".
Dos 89 idiomas fornecidos pelo Facebook, 78 são suportados pela API do Google Translate. Primeiro, obtivemos as 10.000 palavras mais comuns no vocabulário de texto rápido inglês e depois usamos a API para traduzir essas palavras para os 78 idiomas disponíveis. Dividimos esse vocabulário em dois, atribuindo as primeiras 5000 palavras ao dicionário de treinamento e o segundo 5000 ao dicionário de teste.
Descrevemos o procedimento de alinhamento neste blog. São necessários dois conjuntos de vetores de palavras e um pequeno dicionário bilíngue de pares de tradução em dois idiomas; e gera uma matriz que alinha a linguagem de origem com o destino. Às vezes, o Google traduz uma palavra em inglês em uma frase não inglesa; nesses casos, calculamos a média das palavras vetores contidos na frase.
Para colocar todos os 78 idiomas em um único espaço, alinhamos todos os idiomas aos vetores em inglês (a matriz inglesa é a identidade).
Para provar que o procedimento funciona, podemos prever as traduções de palavras não vistas no dicionário de treinamento. Por simplicidade, prevemos traduções dos vizinhos mais próximos. Por exemplo, se quiséssemos traduzir "cachorro" em sueco, simplesmente encontraríamos o vetor de palavras sueco cuja semelhança de cosseno com o vetor de palavra "cachorro" é mais alto.
Primeiro, vamos testar o desempenho da tradução do inglês em todos os outros idiomas. Para cada par de idiomas, extraímos um conjunto de 2500 pares de palavras do dicionário de teste. A Precision @N indica a probabilidade de que, das 2500 palavras -alvo neste conjunto, a verdadeira tradução fosse um dos principais vizinhos mais próximos da palavra de origem. Se o alinhamento fosse completamente aleatório, esperaríamos que a precisão @1 estivesse em torno de 0,0004.
| Linguagem alvo | Precision @1 | Precision @5 | Precision @10 |
|---|---|---|---|
| fr | 0,73 | 0,86 | 0,88 |
| pt | 0,73 | 0,86 | 0,89 |
| es | 0,72 | 0,85 | 0,88 |
| isto | 0,70 | 0,86 | 0,89 |
| nl | 0,68 | 0,83 | 0,86 |
| não | 0,68 | 0,85 | 0,89 |
| da | 0,66 | 0,84 | 0,88 |
| ca | 0,66 | 0,81 | 0,86 |
| Sv | 0,65 | 0,82 | 0,86 |
| cs | 0,64 | 0,81 | 0,85 |
| ro | 0,63 | 0,81 | 0,85 |
| de | 0,62 | 0,75 | 0,78 |
| pl | 0,62 | 0,79 | 0,83 |
| Hu | 0,61 | 0,80 | 0,84 |
| fi | 0,61 | 0,80 | 0,84 |
| EO | 0,61 | 0,80 | 0,85 |
| ru | 0,60 | 0,78 | 0,82 |
| gl | 0,60 | 0,77 | 0,82 |
| Mk | 0,58 | 0,79 | 0,84 |
| eu ia | 0,58 | 0,81 | 0,86 |
| bg | 0,57 | 0,77 | 0,82 |
| EM | 0,57 | 0,81 | 0,86 |
| Reino Unido | 0,57 | 0,75 | 0,79 |
| sh | 0,56 | 0,77 | 0,81 |
| hr | 0,56 | 0,75 | 0,80 |
| tr | 0,56 | 0,77 | 0,81 |
| sl | 0,56 | 0,77 | 0,82 |
| el | 0,54 | 0,75 | 0,80 |
| sk | 0,54 | 0,75 | 0,81 |
| et | 0,53 | 0,73 | 0,78 |
| sr | 0,53 | 0,72 | 0,77 |
| AF | 0,52 | 0,75 | 0,80 |
| lt | 0,50 | 0,72 | 0,79 |
| ar | 0,48 | 0,69 | 0,75 |
| bs | 0,47 | 0,70 | 0,77 |
| lv | 0,47 | 0,68 | 0,75 |
| UE | 0,46 | 0,68 | 0,75 |
| fa | 0,45 | 0,68 | 0,75 |
| hy | 0,43 | 0,66 | 0,73 |
| sq | 0,43 | 0,65 | 0,71 |
| ser | 0,43 | 0,64 | 0,70 |
| Zh | 0,40 | 0,68 | 0,75 |
| Ka | 0,40 | 0,63 | 0,71 |
| cy | 0,39 | 0,63 | 0,71 |
| oi | 0,39 | 0,58 | 0,63 |
| az | 0,38 | 0,60 | 0,67 |
| Ko | 0,37 | 0,58 | 0,66 |
| te | 0,36 | 0,56 | 0,63 |
| KK | 0,35 | 0,60 | 0,68 |
| ele | 0,33 | 0,45 | 0,48 |
| fy | 0,33 | 0,52 | 0,60 |
| vi | 0,31 | 0,53 | 0,62 |
| ta | 0,31 | 0,50 | 0,56 |
| Bn | 0,30 | 0,49 | 0,56 |
| ur | 0,29 | 0,52 | 0,61 |
| é | 0,29 | 0,51 | 0,59 |
| tl | 0,28 | 0,51 | 0,59 |
| KN | 0,28 | 0,43 | 0,46 |
| Gu | 0,25 | 0,44 | 0,51 |
| mn | 0,25 | 0,49 | 0,58 |
| uz | 0,24 | 0,43 | 0,51 |
| si | 0,22 | 0,40 | 0,45 |
| ml | 0,21 | 0,35 | 0,39 |
| KY | 0,20 | 0,40 | 0,49 |
| senhor | 0,20 | 0,37 | 0,44 |
| th | 0,20 | 0,33 | 0,38 |
| la | 0,19 | 0,34 | 0,42 |
| JA | 0,18 | 0,44 | 0,56 |
| ne | 0,16 | 0,33 | 0,38 |
| PA | 0,16 | 0,32 | 0,38 |
| TG | 0,14 | 0,31 | 0,39 |
| km | 0,12 | 0,26 | 0,30 |
| meu | 0,10 | 0,19 | 0,23 |
| Libra | 0,09 | 0,18 | 0,21 |
| mg | 0,07 | 0,18 | 0,25 |
| CEB | 0,06 | 0,13 | 0,18 |
Como você pode ver, o alinhamento é consistentemente muito melhor do que aleatório! Em geral, o procedimento funciona melhor para outros idiomas europeus, como francês, português e espanhol. Usamos 2500 pares de palavras, devido às 5000 palavras no dicionário de teste, nem todas as palavras encontradas pela API do Google Translate estão realmente presentes no vocabulário FastText.
Agora, vamos fazer algo muito mais emocionante, vamos avaliar o desempenho da tradução entre todos os pares de idiomas possíveis. Exibimos esse desempenho de tradução no mapa de calor abaixo, onde a cor de um elemento indica a precisão @1 ao traduzir da linguagem da linha para a linguagem da coluna.
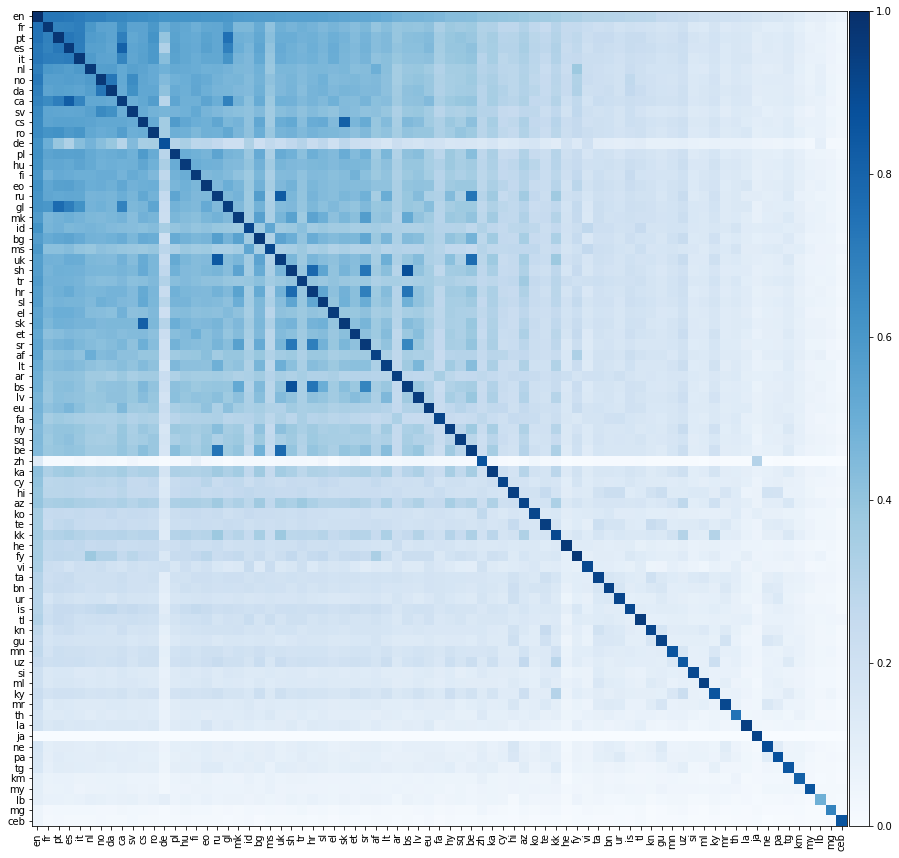
Devemos enfatizar que todos os idiomas estavam alinhados apenas ao inglês . Não fornecemos dicionários de treinamento entre pares de idiomas não ingleses. No entanto, ainda somos capazes de prever com sucesso traduções entre pares de idiomas não ingleses notavelmente com precisão.
Esperamos que os elementos diagonais da matriz acima estejam 1, pois um idioma deve traduzir perfeitamente para si mesmo. No entanto, na prática, isso nem sempre ocorre, porque construímos os dicionários de treinamento e teste, traduzindo palavras comuns em inglês para os outros idiomas. Às vezes, várias palavras em inglês se traduzem na mesma palavra não inglesa e, portanto, a mesma palavra não inglesa pode aparecer várias vezes no conjunto de testes. Não contabilizamos adequadamente isso, o que reduz o desempenho da tradução.
Intriqüentemente, embora tenhamos alinhado diretamente diretamente os idiomas ao inglês, às vezes um idioma se traduz melhor em outro idioma não inglês do que para o inglês! Podemos calcular a precisão entre pares de dois idiomas; A precisão média do idioma 1 ao idioma 2 e vice -versa. Também podemos calcular a precisão do par em inglês; A média da precisão do inglês para o idioma 1 e do inglês para o idioma 2. Abaixo, listamos todos os pares de idiomas para os quais a precisão entre os pares excede a precisão do par em inglês:
| Idioma 1 | Idioma 2 | Precisão entre pares @1 | Precisão em pares de inglês @1 |
|---|---|---|---|
| bs | sh | 0,88 | 0,52 |
| ru | Reino Unido | 0,84 | 0,58 |
| ca | es | 0,82 | 0,69 |
| cs | sk | 0,82 | 0,59 |
| hr | sh | 0,78 | 0,56 |
| ser | Reino Unido | 0,77 | 0,50 |
| gl | pt | 0,76 | 0,66 |
| bs | hr | 0,74 | 0,52 |
| ser | ru | 0,73 | 0,51 |
| da | não | 0,73 | 0,67 |
| sr | sh | 0,73 | 0,54 |
| pt | es | 0,72 | 0,72 |
| ca | pt | 0,70 | 0,69 |
| gl | es | 0,70 | 0,66 |
| hr | sr | 0,69 | 0,54 |
| ca | gl | 0,68 | 0,63 |
| bs | sr | 0,67 | 0,50 |
| Mk | sr | 0,56 | 0,55 |
| KK | KY | 0,30 | 0,28 |
Todos esses pares de idiomas compartilham raízes linguísticas muito próximas. Por exemplo, o primeiro par acima é bósnio e serbo-croata; Bósnia é uma variante de serbo-croata. O segundo par é russo e ucraniano; Ambas as línguas do leste-eslavic. Parece que quanto mais dois idiomas são, mais semelhante a geometria de seus vetores de texto rápido; levando a um melhor desempenho da tradução.
As matrizes fornecidas neste repositório são ortogonais. Intuitivamente, cada matriz pode ser dividida em uma série de rotações e reflexões. Rotações e reflexões não mudam a distância entre dois pontos em um espaço vetorial; E, consequentemente, nenhum dos produtos internos entre vetores de palavras em um idioma é alterado, apenas os produtos internos entre os vetores de palavras de diferentes idiomas são afetados.
Existem vários ótimos trabalhos sobre este tópico. Listamos alguns deles abaixo:
Vários leitores manifestaram interesse nos dicionários de treinamento e teste que usamos neste repositório. Teríamos gostado de enviá -los, no entanto, embora não tenhamos tomado aconselhamento jurídico, estamos preocupados que isso possa ser interpretado como quebrando os termos da API do Google Translate.
As matrizes de transformação são distribuídas sob a Licença Creative Commons Commons Share-Share-Like 3.0 .


