revery
1.0.0
Revery是一種語義搜索引擎,可在我的Monocle搜索索引上運行。雖然Revery讓我可以通過相同的數據庫進行搜索,包括成千上萬的筆記,書籤,日記條目,推文,聯繫人和博客文章,但Revery的重點不是單鏡可以執行的基於關鍵字的搜索,而是在語義搜索上進行的,而是在類似於給定的網頁或Query或不共享同一單詞的基於語義搜索上。它可作為瀏覽器擴展程序可用,可以將相關的結果呈現到當前頁面,以及類似於Monocle的搜索頁面的更標準的Web應用程序。
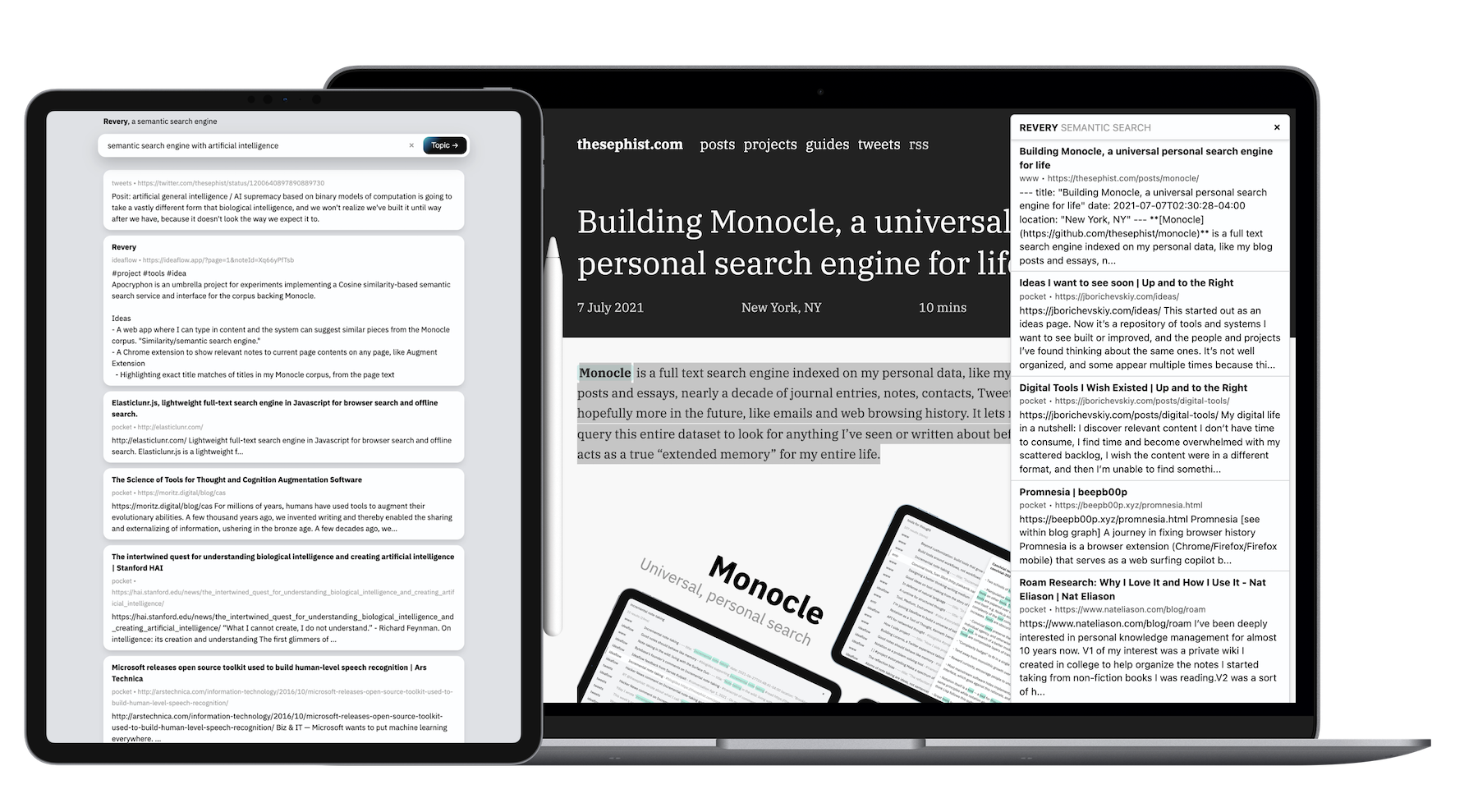
與我的大多數附帶項目不同,由於數據的大小和計算工作的數量,它的後端是在GO中寫成的。兩個客戶端(Web應用程序和瀏覽器擴展程序)都是由Torus構建的。
儘管它每天都可以使用它,但它每天都可以使用它,但Revery更像是概念驗證的原型,而不是成品。我想證明可以在個人生產力工具(例如筆記和書籤)上構建這樣的工具,並體驗瀏覽網絡並使用這種工具寫入的感覺。
Revery的核心只是一個API。 API收集了一些文本,並通過我的個人文檔和註釋收集的內容爬網,以找到與給定文本最局部相關的頂部文檔。為了使此有趣的使用,我將其包裝在兩個不同的接口:瀏覽器擴展程序和一個基於Web的標準搜索界面。
Revery瀏覽器擴展存在於此存儲庫中的內部./extension當我查看的任何網頁上擊中Ctrl-Shift-L時,都會做一件事,它將從頁面上刮擦文本的主體(或某些部分的部分,如果我強調了某些內容),並與Revery API與Revery API交談以與我正在閱讀的內容有關。

Monocle具有基於關鍵字的搜索算法,非常適合回憶,我發現Revery擴展非常適合探索特定主題。例如,如果我正在閱讀有關自然語言處理的有關自然語言處理的信息,那麼我可以擊中一些擊鍵,以提出我讀過的其他文章,或者我過去記錄的筆記,我可以在閱讀並了解NLP中的新想法時進行精神參考。
當我們可以在內存中找到現有的參考點時,我們可以最好地學習新的想法,並在其中附加新信息。 REVER的擴展部分自動化並加快了該任務。例如,在閱讀有關韓國在世界上獨特的文化和經濟地位的文章時,《狂歡》中的一些相關的新聞通訊和文章來自完全不同的作者和有關韓國流行文化及其人口下降的資源,這幫助我在更廣泛,信息良好的環境中構築了我正在閱讀的內容。
對我而言,Web搜索界面是擴展名的次要。它主要是作為對Revery的基本技術的演示,也是順便說一句,作為我在不可用時使用Reverre的一種方式(例如在移動瀏覽器上)。
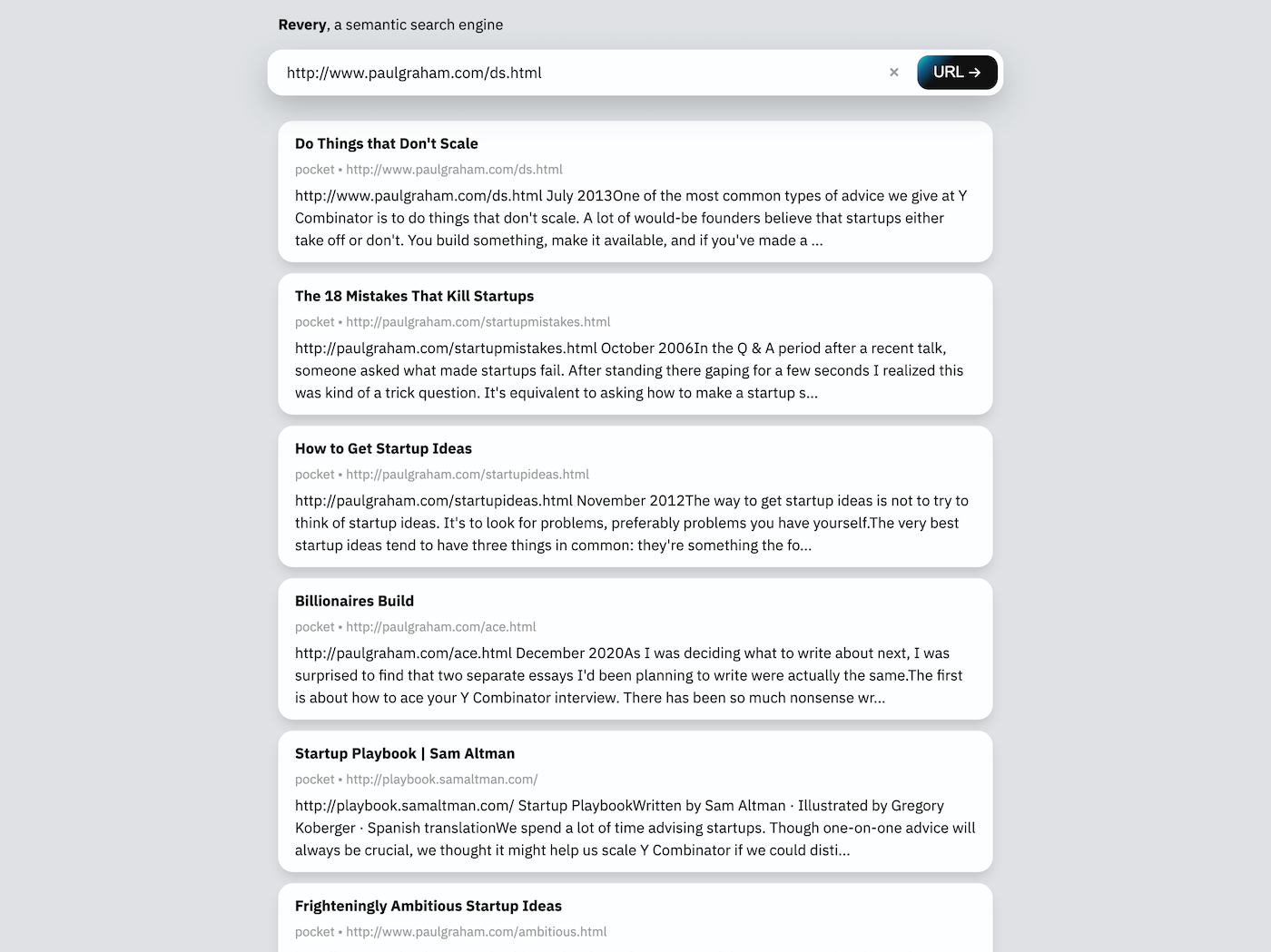
Web接口中的搜索欄可以使用URL或某些鍵短語。給定URL(如上面的屏幕截圖),Revery將下載並閱讀網頁本身以在搜索索引中查找相關文檔。給定一個關鍵短語,Revery將嘗試提出包含類似單詞的文檔,並就類似主題講話。
這種搜索界面(與擴展相反)對我開始思考新事物很有用,我可以在搜索框中輸入相關單詞列表,並立即獲得我熟悉的我熟悉的想法和文檔列表,而無需塑造特定且精心設計的搜索查詢,這些查詢像Monocle這樣的關鍵字搜索引擎(例如Monocle(例如Monocle)所需的需求。
如上所述,Revery的核心是一個單個API端點,該端點吸收了一些文檔,並從我的搜索索引中返回了大多數相關文檔的列表。使Revery與眾不同的是,此API執行語義搜索,而不僅僅是掃描匹配關鍵字的掃描。這意味著最高結果甚至可能不包含與查詢相同的單詞,只要其內容與局部相關。
這種語義搜索是通過搜索算法啟用的,該算法使用餘弦的相似性與索引文檔的群集文檔嵌入。如果這聽起來像是您對您的一堆隨機單詞(就像我啟動此項目時對我所做的那樣),請讓我分解:
首先,我們需要了解單詞嵌入。嵌入單詞是將自然語言單詞詞彙映射到空間中某些點(通常是高維數學空間)的一種方式,因此在此空間中,含義相似的單詞相連。例如,嵌入單詞中的“科學”一詞將非常接近“科學家”一詞,它與“研究”相當接近,並且可能與“馬戲團”很遠。當我們在單詞嵌入的上下文中談論“距離”時,我們通常使用餘弦相似性而不是歐幾里得距離,出於經驗和理論原因,我在這裡都不會介紹。
儘管單詞嵌入的概念不是很新,但仍有積極的研究產生新的方法,以從相同的數據語料庫中生成更準確和有用的單詞嵌入。我對revery的個人部署使用Facebook的FastText工俱生成的創意常見單詞嵌入數據集,尤其是一個50,000字的數據集,其中具有300個維度,該數據集對公共爬網語料庫進行了訓練。
單詞嵌入讓我們提出有關哪些單詞相關的推斷,但是對於Revery,我們想對文檔進行相同的推論,這些推論是單詞列表。值得慶幸的是,有足夠的文獻建議文檔中每個單詞的加權平均值可以使我們獲得代表整個文檔的“文檔向量”的良好近似。儘管我們可以使用更多的高級方法,例如段落或模型將單詞順序考慮在內,但平均文字向量可以很好地用於Revery的用例,並且易於實現和測試,因此請使用這種方法。
一旦我們可以使用嵌入單詞從文檔中生成文檔向量,則其餘算法就會出現。在啟動時,REVERY的API服務器索引並生成文檔向量,用於在我的數據集中找到的所有文檔(在寫作時不太大 - 約25,000個),並且在每個請求下,算法都為請求的文檔計算一個文檔向量,並通過搜索索引中的每個文檔來返回QUERY ncepine docection cool QUERY DOMECTE,以返回Query n Top n最高n的結果。
在Revery中,該算法的每個部分都在GO中手寫。這是出於一些原因:
Revery的兩個客戶 - 擴展名和Web應用程序 - 與這個單個API端點進行了交談。客戶本身很普通,因此我不會詳細描述他們在這裡的工作方式。
在這裡,我與Monocle共享的同一免責聲明也適用:
Revery取決於Monocle索引器所產生的搜索索引,因此我通常會確保Revery在運行之前提供了Monocle搜索索引的最新副本。
Revery在同一存儲庫中有兩個獨立的代碼庫。第一個是Chrome Extension,它完全居住在./extension文件夾中。這是我設置的方式:
該擴展名需要API身份驗證令牌與Revery API進行對話。我通常只選擇一個任意長的隨機字符串。然後,我將一個文件token.js ./extension
const REVERY_TOKEN = '<some API key here>' ;我轉到chrome://extensions ,然後單擊“加載打開包裝”,將./extension文件夾作為“未包裝擴展”加載到我的瀏覽器中,這將使每個選項卡中的擴展名可用。
就是這樣的擴展設置。接下來,我設置了服務器:
tokens.txt中,將其放入項目文件夾的根部。 Revery Server將獲取此文件的Whitespace Trimmed內容,並將其用作API密鑰。make將在項目文件夾中構建revery二進制執行。docs.json文檔Document Document DataSet to ./corpus/docs.json 。revery可執行文件應正確預處理模型和搜索索引,然後啟動Web應用程序服務器。 儘管Revery對我每天都有足夠的用處,但是在一般的自然語言搜索空間中有很多積極的研究,而Revery本身也有很大的改進空間。
在數據方面:
在代碼方面:
這個領域也有很多偉大的藝術。儘管我不能在這裡列出所有這些,但有些人脫穎而出是Revery的靈感。


