revery
1.0.0
Revery é um mecanismo de pesquisa semântico que opera no meu índice de pesquisa de monóculo. Enquanto Revery permite que eu pesquise no mesmo banco de dados de dezenas de milhares de notas, favoritos, entradas de diário, tweets, contatos e postagens de blog como monocle, o foco de Revery não está na pesquisa de palavras-chave que o monocle executa, mas, em vez de pesquisas semânticas -descobrindo os resultados que são topicamente semelhantes a algumas dadas da web ou consulta, mesmo que não compartilhem as mesmas palavras. Ele está disponível como uma extensão do navegador que pode surgir nos resultados relevantes para a página atual, bem como um aplicativo da Web mais padrão que se assemelha à página de pesquisa do Monocle.
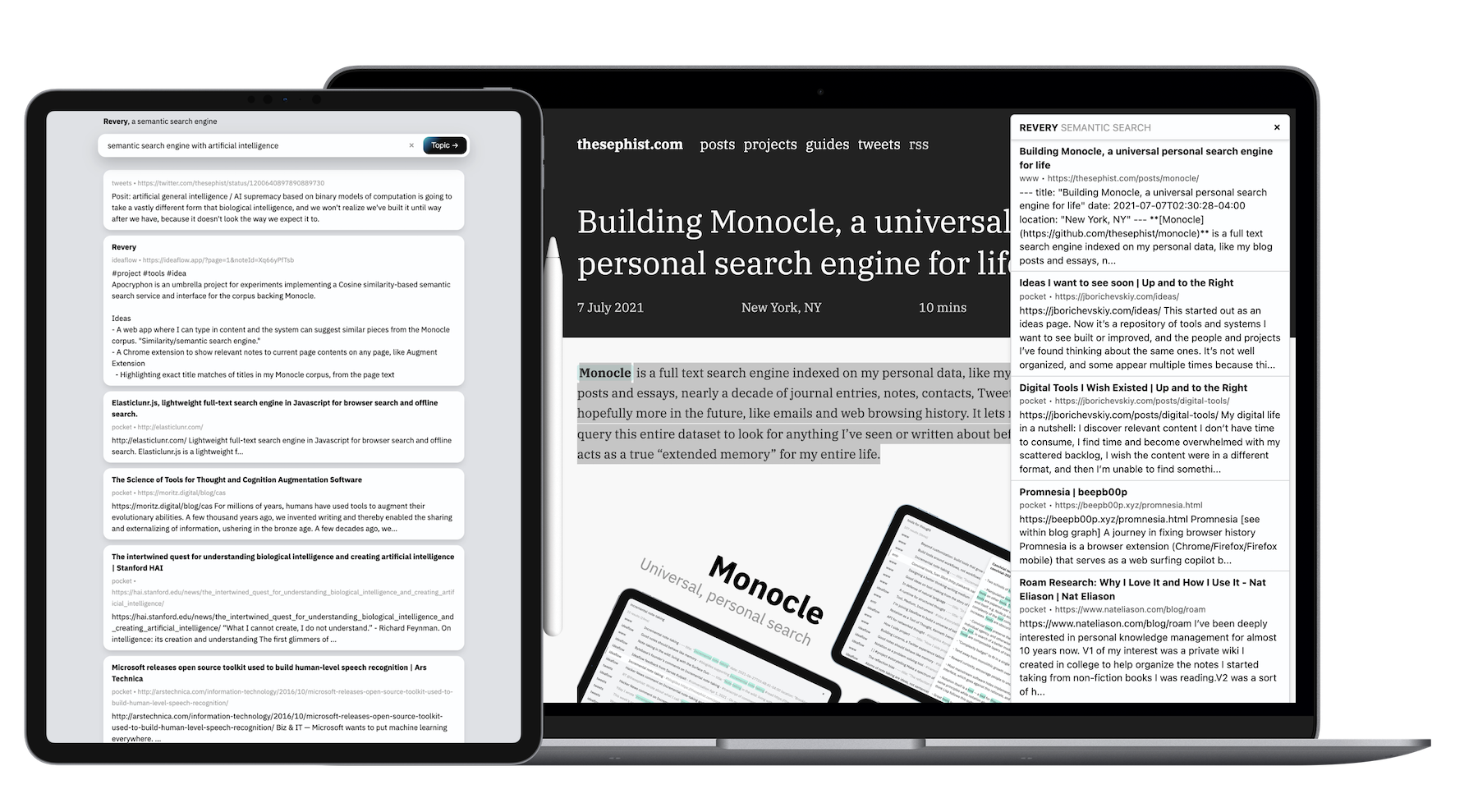
Diferentemente da maioria dos meus projetos paralelos, devido ao tamanho dos dados e à quantidade de trabalho computacional que o requer, seu back -end é escrito em Go. Ambos os clientes - o aplicativo da web e a extensão do navegador - são construídos com o toro.
Embora funcione bem o suficiente para eu usá-lo todos os dias, o Relevery é mais um protótipo de prova de conceito do que um produto acabado. Eu queria demonstrar que uma ferramenta como essa poderia ser construída para uso pessoal sobre ferramentas de produtividade pessoal, como notas e favoritos, e experimentar como seria navegar na web e escrever com essa ferramenta.
O Revevery, em sua essência, é apenas uma API única. A API recebe algum texto e rasteja pela minha coleção de documentos e anotações pessoais para encontrar os principais que parecem mais topicamente relacionados ao texto especificado. Para tornar isso interessante de usar, eu o encerrei em duas interfaces diferentes: uma extensão do navegador e uma interface de pesquisa mais padrão baseada na Web.
A extensão do navegador de ./extension vive dentro./Extensão neste repositório, e faz exatamente uma coisa: quando eu atropei Ctrl-Shift-L em qualquer página da web que estou visualizando, ele raspará o principal corpo de texto da página (ou parte da parte selecionada, se eu destacei algo) e converse com o API de revery para encontrar os documentos que mais relacionados.

Onde o Monocle, com seu algoritmo de pesquisa baseado em palavras-chave, é bom para lembrar, achei a extensão de revery excelente para explorações em um tópico específico . Se estou lendo sobre processamento de linguagem natural, por exemplo, posso acertar algumas teclas para criar outros artigos que li ou anotações que fiz no passado, que posso referência mentalmente enquanto leio e aprendo sobre novas idéias na PNL.
Aprendemos novas idéias melhor quando podemos encontrar pontos de referência existentes em nossa memória na qual podemos anexar novas informações. A extensão de Revery automatiza e acelera parte dessa tarefa. Por exemplo, ao ler um artigo sobre a posição cultural e econômica exclusiva da Coréia do Sul no mundo, Revery surgiu alguns boletins e artigos relacionados de autores e fontes completamente diferentes sobre a cultura pop coreana e seu declínio da população, o que me ajudou a enquadrar o que eu estava lendo em um contexto muito mais amplo e bem informado.
A interface de pesquisa da web, para mim, é um pouco secundária para a extensão. Ele existe principalmente como uma demonstração da tecnologia subjacente de Re -Tvery, e também incidentalmente como uma maneira de eu usar o revery quando a extensão não estiver disponível (como em um navegador móvel).
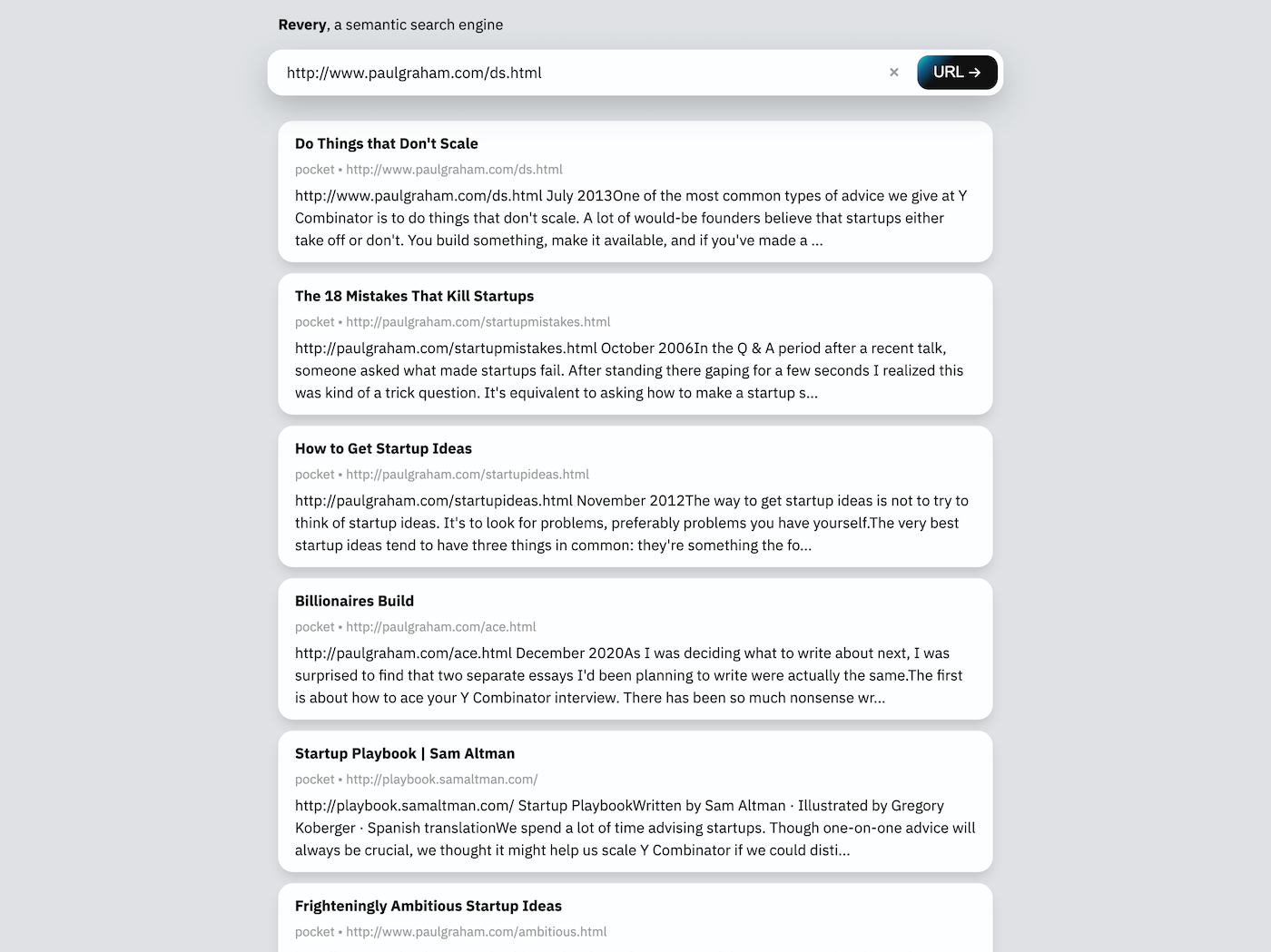
A barra de pesquisa na interface da web pode tomar um URL ou alguma frase -chave. Dado um URL (como na captura de tela acima), o revery baixará e lerá a própria página da web para encontrar documentos relacionados no índice de pesquisa. Dada uma frase -chave, o revery tentará sugerir documentos que contêm palavras semelhantes e falam em tópicos semelhantes.
Esse tipo de interface de pesquisa (em oposição à extensão) é útil para começar a pensar em algo novo, onde posso digitar uma lista de palavras relacionadas na caixa de pesquisa e obter imediatamente uma lista de idéias e documentos que estou familiarizada, sem ter que criar as consultas específicas e bem elaboradas que os mecanismos de pesquisa baseados em palavras-chave, como os monocle, exigem.
Como mencionado acima, o Core de Revery é um único ponto de extremidade da API que recebe algum documento e retorna uma lista dos documentos mais relacionados do meu índice de pesquisa. O que torna o Revery Special é que esta API realiza uma pesquisa semântica , não apenas uma varredura para palavras -chave correspondentes. Isso significa que os resultados superiores podem nem conter as mesmas palavras que a consulta, desde que seu conteúdo seja relevante topicamente.
Esse tipo de pesquisa semântica é ativada por um algoritmo de pesquisa que usa similaridade de cosseno para cluster incorporações dos documentos indexados. Se isso soa como um monte de palavras aleatórias para você (como me fez quando eu iniciei este projeto), deixe -me dividi -lo:
Primeiro, precisamos entender as incorporações de palavras . Uma palavra incorporação é uma maneira de mapear um vocabulário de palavras de linguagem natural para alguns pontos no espaço (geralmente um espaço matemático de alta dimensão), de modo que as palavras que são semelhantes em significado são próximas neste espaço. Por exemplo, a palavra "ciência" em uma palavra incorporação seria muito próxima da palavra "cientista", razoavelmente próxima de "pesquisa" e provavelmente muito longe de "circo". Quando falamos sobre "distância" no contexto das incorporações de palavras, geralmente usamos a similaridade de cosseno em vez da distância euclidiana, por razões empíricas e teóricas que não vou cobrir aqui.
Embora o conceito de incorporação de palavras não seja muito novo, ainda há pesquisas ativas produzindo novos métodos para gerar incorporações de palavras cada vez mais precisas e úteis do mesmo corpus de dados. Minha implantação pessoal de revery usa o conjunto de dados Creative Commons Licensed Word Incoredding DataSet produzido pela ferramenta FastText do Facebook, especificamente um conjunto de dados de 50.000 palavras com 300 dimensões treinadas no corpus de rastreamento comum.
Incorporações de palavras Vamos desenhar inferências sobre quais palavras estão relacionadas, mas, para revery, queremos desenhar o mesmo tipo de inferência sobre documentos , que são uma lista de palavras. Felizmente, há ampla literatura para sugerir que simplesmente tomar uma média ponderada de vetores de palavras para cada palavra em um documento pode nos dar uma boa aproximação de um "vetor de documento" que representa o documento como um todo. Embora existam métodos mais avançados que possamos usar, como vetores de parágrafos ou modelos que levam em consideração a ordem das palavras como Bert, a média dos vetores de palavras funciona bem o suficiente para os casos de uso de Revery e é simples de implementar e testar, portanto, a renda de remendos com essa abordagem.
Depois que podemos gerar vetores de documentos a partir de documentos usando nossa palavra incorporação, o restante do algoritmo se encaixa. Na startup, o servidor de API da Revery indexa e gera vetores de documentos para todos os documentos que ele pode encontrar no meu conjunto de dados (que não é muito grande - cerca de 25.000 no momento da redação) e, a cada solicitação, o algoritmo calcula um documento para o documento para o documento solicitado e classifica todos os documentos.
Dentro de tudo, todas as partes desse algoritmo são escradas à mão. Isso é por alguns motivos:
Ambos os clientes da Revery - a extensão e o aplicativo da web - conversam com esse terminal de API único. Os próprios clientes são bastante comuns, então não vou entrar em detalhes descrevendo como eles funcionam aqui.
Aqui, o mesmo aviso que compartilhei com o Monocle também se aplica:
O revery depende do índice de pesquisa produzido pelo Indexer da Monocle, por isso geralmente garanto que o revery tem uma cópia recente do índice de pesquisa de Monocle disponível antes de ser executado.
Revery tem duas bases de código independentes no mesmo repositório. O primeiro é a extensão do Chrome, que vive inteiramente dentro da pasta ./extension . Aqui está como eu configurei:
A extensão precisa de um token de autenticação da API para conversar com a API de revery. Eu geralmente escolho uma corda aleatória arbitrariamente longa. Em seguida, coloco um arquivo em ./extension chamado token.js com o conteúdo:
const REVERY_TOKEN = '<some API key here>' ; Eu vou ao chrome://extensions e clico em "Carregar desconhecido" para carregar a pasta ./extension como uma "extensão descompactada" no meu navegador, que disponibilizará a extensão em cada guia.
É isso para a configuração de extensão. Em seguida, configurei o servidor:
tokens.txt na raiz da pasta do projeto. O servidor revery pegará o conteúdo de Whitespace com esse arquivo e o usará como a tecla API.make criará o executável binário revery na pasta do projeto.docs.json do monocle gerado pelo indexador para ./corpus/docs.json .revery agora deve pré-processar corretamente o modelo e o índice de pesquisa e iniciar o servidor de aplicativos da Web. Embora o revery seja útil o suficiente para eu usar o dia a dia, há muitas pesquisas ativas no espaço geral de busca de idiomas naturais, e o próprio Revery tem muito espaço para melhorias.
No lado dos dados:
No lado do código:
Também há muita arte anterior neste espaço. Embora eu não possa listá -los todos aqui, existem alguns que se destacam como inspirações para revery.


