revery
1.0.0
Revery เป็น เครื่องมือค้นหาความหมาย ที่ทำงานบนดัชนีการค้นหา monocle ของฉัน ในขณะที่ Revery ให้ฉันค้นหาฐานข้อมูลเดียวกันของโน้ตนับหมื่น, บุ๊กมาร์ก, รายการวารสาร, ทวีต, ผู้ติดต่อและโพสต์บล็อกเป็น monocle, การโฟกัสของ Revery ไม่ได้อยู่ในการค้นหา ตามคำ หลัก มันมีให้เป็นส่วนขยายของเบราว์เซอร์ที่สามารถแสดงผลลัพธ์ที่เกี่ยวข้องกับหน้าปัจจุบันรวมถึงแอพมาตรฐานเว็บที่คล้ายคลึงกับหน้าการค้นหาของ Monocle
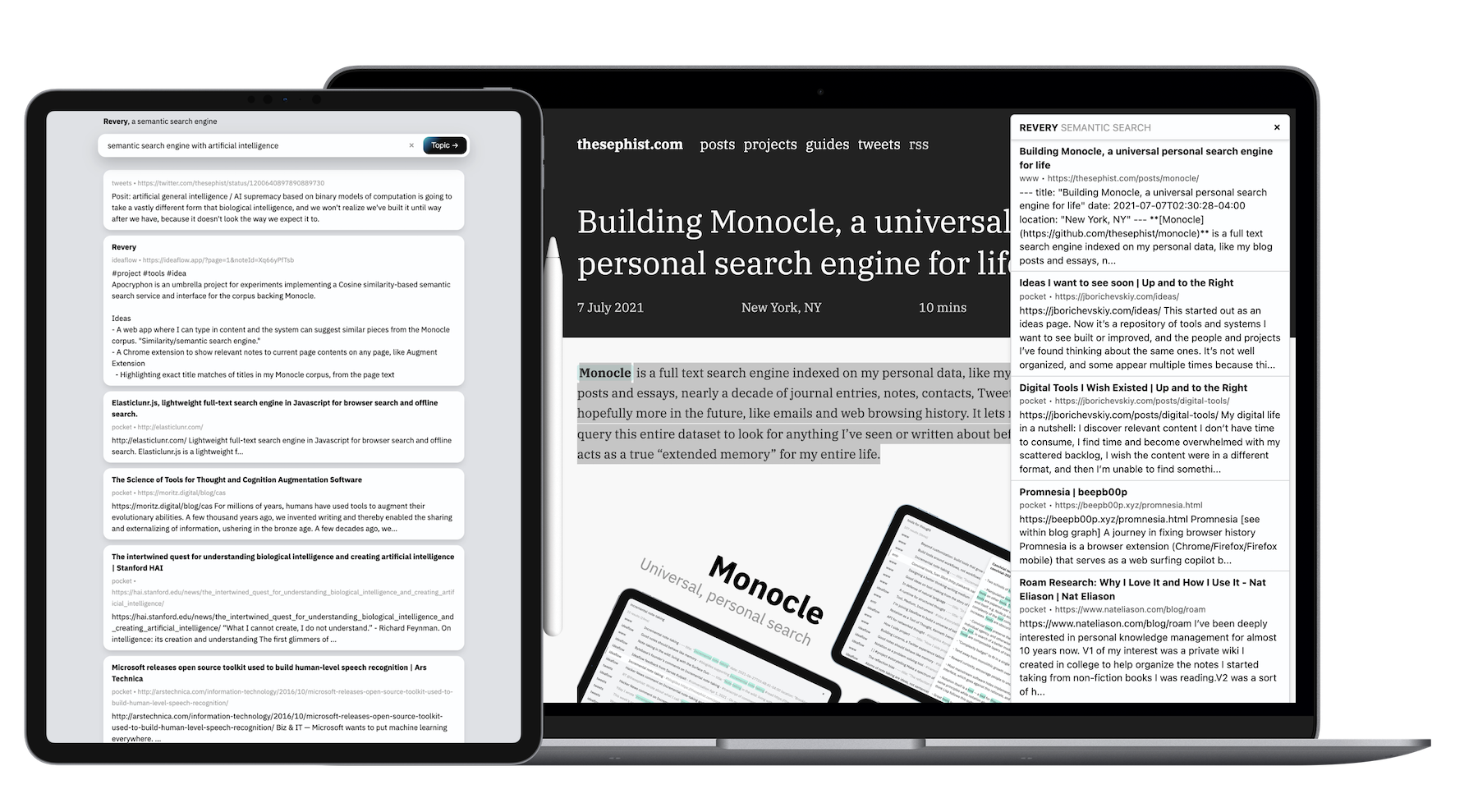
ซึ่งแตกต่างจากโครงการด้านข้างของฉันส่วนใหญ่เนื่องจากขนาดของข้อมูลและจำนวนของงานคำนวณที่ต้องใช้ Revery ต้องมีการเขียนแบ็กเอนด์ใน GO ทั้งไคลเอนต์ - เว็บแอปและส่วนขยายของเบราว์เซอร์ - ถูกสร้างขึ้นด้วย Torus
แม้ว่ามันจะใช้งานได้ดีพอสำหรับฉันที่จะใช้มันทุกวัน แต่ Revery เป็นต้นแบบที่พิสูจน์ได้มากกว่าผลิตภัณฑ์สำเร็จรูป ฉันต้องการแสดงให้เห็นว่าเครื่องมือเช่นนี้สามารถสร้างขึ้นเพื่อการใช้งานส่วนตัวบนเครื่องมือการเพิ่มประสิทธิภาพส่วนบุคคลเช่นโน้ตและบุ๊กมาร์กและสัมผัสกับสิ่งที่รู้สึกเหมือนได้เรียกดูเว็บและเขียนด้วยเครื่องมือดังกล่าว
Revery ที่แกนกลางเป็นเพียง API เดียว API ใช้ในข้อความบางส่วนและรวบรวมข้อมูลผ่านคอลเลกชันของเอกสารส่วนตัวและบันทึกย่อของฉันเพื่อค้นหาข้อความยอดนิยมที่ดูเหมือนจะเกี่ยวข้องกับข้อความที่กำหนดที่สุด เพื่อให้การใช้งานนี้น่าสนใจฉันได้ห่อมันไว้ในสองอินเทอร์เฟซที่แตกต่างกัน: ส่วนขยายเบราว์เซอร์และอินเทอร์เฟซการค้นหาบนเว็บมาตรฐานมากขึ้น
ส่วนขยายเบราว์เซอร์ Revery อาศัยอยู่ภายใน ./extension extension ในที่เก็บนี้และทำสิ่งหนึ่งอย่างแน่นอน: เมื่อฉันกด Ctrl-Shift-L บนหน้าเว็บใด ๆ ที่ฉันกำลังดูมันจะขูดเนื้อหาหลักของข้อความจากหน้า (หรือบางส่วนที่เลือก

ในกรณีที่ Monocle ซึ่งมีอัลกอริทึมการค้นหาตามคำหลักนั้นดีสำหรับความทรงจำฉันได้พบส่วนขยายย้อนกลับที่ยอดเยี่ยมสำหรับ การสำรวจในหัวข้อเฉพาะ หากฉันอ่านเกี่ยวกับการประมวลผลภาษาธรรมชาติฉันสามารถกดปุ่มกดเพียงไม่กี่เพื่อนำบทความอื่น ๆ ที่ฉันอ่านหรือบันทึกที่ฉันเคยทำในอดีตที่ฉันสามารถอ้างอิงทางจิตใจเมื่อฉันอ่านและเรียนรู้เกี่ยวกับแนวคิดใหม่ใน NLP
เราเรียนรู้แนวคิดใหม่ที่ดีที่สุดเมื่อเราสามารถค้นหาจุดอ้างอิงที่มีอยู่ในหน่วยความจำของเราซึ่งเราสามารถแนบข้อมูลใหม่ได้ ส่วนขยายของ Revery เป็นส่วนหนึ่งโดยอัตโนมัติและเร่งงานนั้น ตัวอย่างเช่นในขณะที่อ่านบทความเกี่ยวกับตำแหน่งทางวัฒนธรรมและเศรษฐกิจที่เป็นเอกลักษณ์ของเกาหลีใต้ในโลก Revery โผล่ออกมาจากจดหมายข่าวและบทความที่เกี่ยวข้องจากนักเขียนและแหล่งข้อมูลที่แตกต่างกันอย่างสิ้นเชิงเกี่ยวกับวัฒนธรรมป๊อปเกาหลีและการลดลงของประชากร
อินเทอร์เฟซการค้นหาเว็บสำหรับฉันเป็นรองเล็กน้อยของส่วนขยาย มันมีอยู่เป็นหลักในการสาธิตเทคโนโลยีพื้นฐานของ Revery และยังบังเอิญเป็นวิธีที่ฉันจะใช้ Revery เมื่อส่วนขยายไม่พร้อมใช้งาน (เช่นบนเบราว์เซอร์มือถือ)
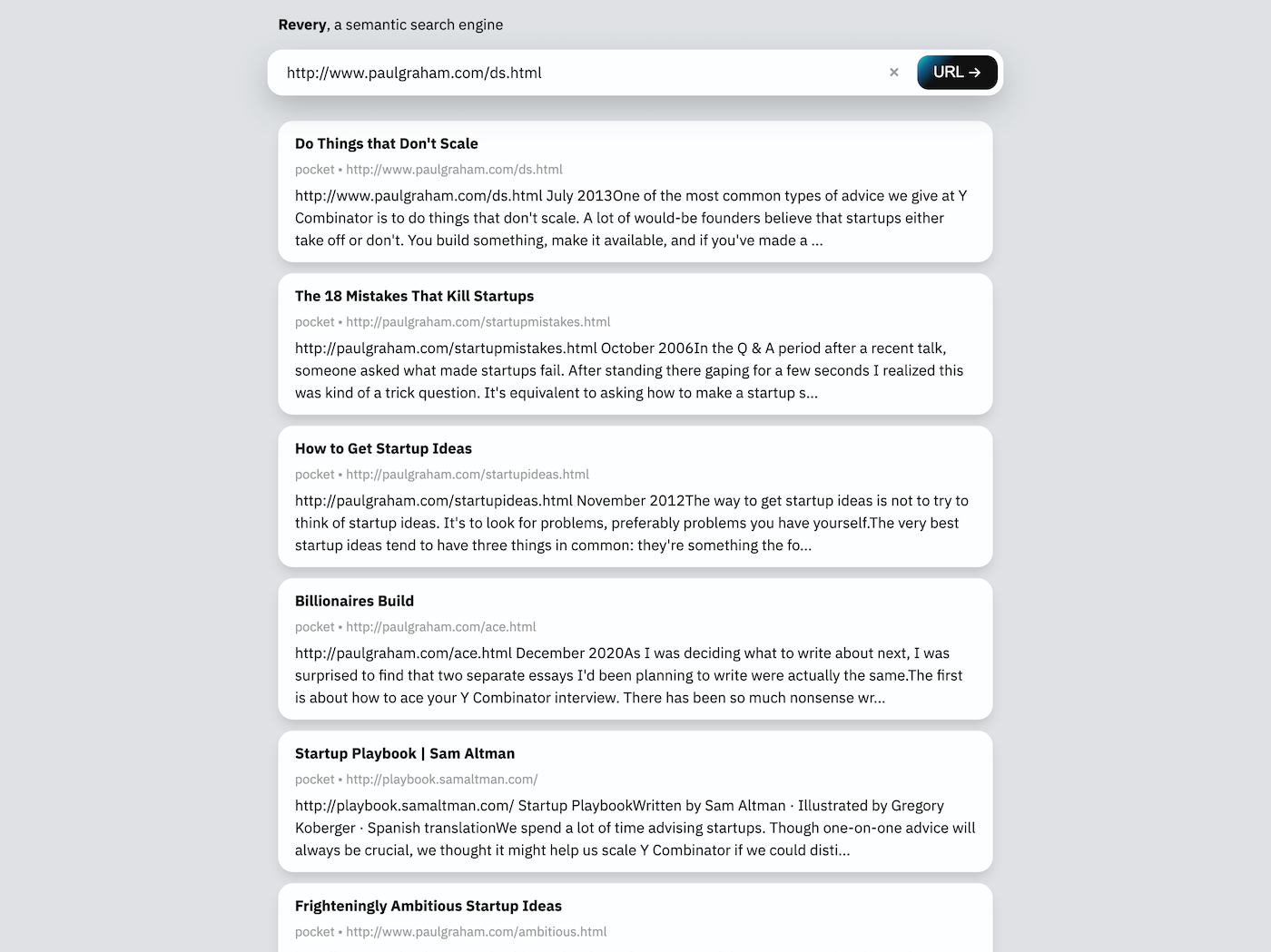
แถบค้นหาในเว็บอินเตอร์เฟสสามารถใช้ URL หรือวลีสำคัญบางอย่าง ให้ URL (เช่นในภาพหน้าจอด้านบน) Revery จะดาวน์โหลดและอ่านหน้าเว็บเองเพื่อค้นหาเอกสารที่เกี่ยวข้องในดัชนีการค้นหา เมื่อได้รับวลีสำคัญ Revery จะพยายามแนะนำเอกสารที่มีคำที่คล้ายกันและพูดในหัวข้อที่คล้ายกัน
อินเทอร์เฟซการค้นหาประเภทนี้ (ตรงข้ามกับส่วนขยาย) มีประโยชน์สำหรับฉันสำหรับการเริ่มคิดเกี่ยวกับสิ่งใหม่ ๆ ที่ฉันสามารถพิมพ์ในรายการคำที่เกี่ยวข้องลงในช่องค้นหาและรับรายการความคิดและเอกสารที่ฉันคุ้นเคยทันทีโดยไม่ต้องแฟชั่นการค้นหาที่เฉพาะเจาะจง
ดังที่ได้กล่าวไว้ข้างต้นแกนกลางของ Revery เป็นจุดสิ้นสุด API เดียวที่ใช้ในเอกสารบางฉบับและส่งคืนรายการเอกสารที่เกี่ยวข้องมากที่สุดจากดัชนีการค้นหาของฉัน สิ่งที่ทำให้ Revery Special คือ API นี้ทำการค้นหา ความหมาย ไม่ใช่แค่การสแกนสำหรับการจับคู่คำหลัก ซึ่งหมายความว่าผลลัพธ์ด้านบนอาจไม่ได้มีคำเดียวกับแบบสอบถามตราบใดที่เนื้อหามีความเกี่ยวข้องอย่างมาก
การค้นหาความหมายแบบนี้เปิดใช้งานโดยอัลกอริทึมการค้นหาที่ใช้ ความคล้ายคลึงกันของโคไซน์ กับ การฝังเอกสาร คลัสเตอร์ของเอกสารที่จัดทำดัชนี หากฟังดูเหมือนคำสุ่มให้คุณ (เหมือนที่ฉันทำเมื่อฉันเริ่มโครงการนี้) ให้ฉันทำลายมันลง:
ก่อนอื่นเราจะต้องเข้าใจ การฝังคำ การฝังคำเป็นวิธีการทำแผนที่คำศัพท์ของคำภาษาธรรมชาติกับบางจุดในอวกาศ (โดยปกติจะเป็นพื้นที่คณิตศาสตร์มิติสูง) เช่นคำที่มีความหมายคล้ายกันอยู่ใกล้กันในพื้นที่นี้ ตัวอย่างเช่นคำว่า "วิทยาศาสตร์" ในคำที่ฝังอยู่ใกล้กับคำว่า "นักวิทยาศาสตร์" ใกล้เคียงกับ "การวิจัย" อย่างสมเหตุสมผลและน่าจะอยู่ไกลจาก "คณะละครสัตว์" เมื่อเราพูดถึง "ระยะทาง" ในบริบทของการฝังคำเรามักจะใช้ความคล้ายคลึงกันของโคไซน์มากกว่าระยะทางยุคลิดด้วยเหตุผลเชิงประจักษ์และเชิงทฤษฎีที่ฉันจะไม่ครอบคลุมที่นี่
แม้ว่าแนวคิดของการฝังคำไม่ได้ใหม่ แต่ก็ยังมีการวิจัยที่ใช้งานอยู่สร้างวิธีการใหม่สำหรับการสร้างคำที่ถูกต้องมากขึ้นและมีประโยชน์มากขึ้นจากคลังข้อมูลเดียวกัน การปรับใช้ส่วนบุคคลของฉันของ Revery ใช้ชุดข้อมูลการฝังคำศัพท์ที่ได้รับอนุญาตจาก Creative Commons ที่ผลิตโดยเครื่องมือ FastText ของ Facebook โดยเฉพาะชุดข้อมูล 50,000 คำที่มี 300 มิติที่ผ่านการฝึกอบรมเกี่ยวกับคลังข้อมูลทั่วไป
การฝังคำให้เราวาดการอนุมานเกี่ยวกับ คำ ที่เกี่ยวข้องกัน แต่สำหรับการกลับคืนเราต้องการวาดการอนุมานแบบเดียวกันเกี่ยวกับ เอกสาร ซึ่งเป็นรายการของคำ โชคดีที่มีวรรณกรรมที่เพียงพอที่จะแนะนำว่าเพียงแค่การใช้เวกเตอร์คำโดยเฉลี่ยถ่วงน้ำหนักสำหรับทุกคำในเอกสารจะทำให้เราได้รับการประมาณที่ดีของ "เอกสารเวกเตอร์" ที่แสดงถึงเอกสารโดยรวม แม้ว่าจะมีวิธีการขั้นสูงมากขึ้นที่เราสามารถใช้ได้เช่นเวกเตอร์ย่อหน้าหรือโมเดลที่คำนึงถึงคำสั่งซื้อเช่นเบิร์ตคำพูดเฉลี่ยเวกเตอร์ทำงานได้ดีพอสำหรับกรณีการใช้งานของ Revery และง่ายต่อการใช้งานและทดสอบ
เมื่อเราสามารถสร้างเวกเตอร์เอกสารออกจากเอกสารโดยใช้การฝังคำของเราส่วนที่เหลือของอัลกอริทึมจะเข้าที่ เมื่อเริ่มต้นดัชนีเซิร์ฟเวอร์ API ของ Revery และสร้างเวกเตอร์เอกสารสำหรับเอกสารทั้งหมดที่สามารถค้นหาได้ในชุดข้อมูลของฉัน (ซึ่งไม่ใหญ่เกินไป - ประมาณ 25,000 ในเวลาที่เขียน) และในทุกคำขออัลกอริทึมจะคำนวณเอกสาร สำหรับ เอกสารที่ร้องขอ
ภายใน Revery ทุกส่วนของอัลกอริทึมนี้จะถูกเขียนด้วยมือใน GO นี่คือเหตุผลบางประการ:
ลูกค้าทั้งสองของ Revery - ส่วนขยายและเว็บแอป - พูดคุยกับจุดสิ้นสุด API เดียวนี้ ลูกค้าเองค่อนข้างธรรมดาดังนั้นฉันจะไม่เข้าไปดูรายละเอียดที่อธิบายว่าพวกเขาทำงานที่นี่อย่างไร
ที่นี่ข้อจำกัดความรับผิดชอบแบบเดียวกับที่ฉันแบ่งปันกับ Monocle ก็ใช้:
Revery ขึ้นอยู่กับดัชนีการค้นหาที่ผลิตโดยดัชนีของ Monocle ดังนั้นฉันมักจะตรวจสอบให้แน่ใจว่า Revery มีสำเนาดัชนีการค้นหาของ Monocle ล่าสุดก่อนที่จะทำงาน
Revery มีสองรหัสอิสระในที่เก็บเดียวกัน อย่างแรกคือส่วนขยายของโครเมี่ยมซึ่งอาศัยอยู่ในโฟลเดอร์ ./extension extension ทั้งหมด นี่คือวิธีที่ฉันตั้งค่า:
ส่วนขยายต้องการโทเค็นการตรวจสอบ API เพื่อพูดคุยกับ API Revery ฉันมักจะเลือกสตริงสุ่มยาวโดยพลการ จากนั้นฉันวางไฟล์ไว้ใน ./extension extension เรียกว่า token.js กับเนื้อหา:
const REVERY_TOKEN = '<some API key here>' ; ฉันไปที่ chrome://extensions แล้วคลิก "โหลด unpacked" เพื่อโหลดโฟลเดอร์ ./extension extension เป็น "ส่วนขยายที่แกะ" ลงในเบราว์เซอร์ของฉันซึ่งจะทำให้ส่วนขยายมีอยู่ในทุกแท็บ
นั่นคือการตั้งค่าส่วนขยาย ต่อไปฉันตั้งค่าเซิร์ฟเวอร์:
tokens.txt ในรูทของโฟลเดอร์โครงการ เซิร์ฟเวอร์ Revery จะคว้าเนื้อหาที่ตัดแต่งช่องว่างของไฟล์นี้และใช้เป็นคีย์ APImake จะสร้าง revery BINARY CONECUTABLE ลงในโฟลเดอร์โครงการdocs.json ของ Monocle ที่สร้างโดยตัวทำดัชนีเป็น ./corpus/docs.jsonrevery Executable ตอนนี้ควรประมวลผลโมเดลและดัชนีการค้นหาอย่างถูกต้องและเริ่มต้นเว็บแอปพลิเคชันเซิร์ฟเวอร์ แม้ว่า Revery จะมีประโยชน์เพียงพอสำหรับฉันที่จะใช้วันต่อวัน แต่ก็มีการวิจัยที่ใช้งานอยู่มากมายในพื้นที่การค้นหาภาษาธรรมชาติทั่วไปและ Revery เองก็มีพื้นที่สำหรับการปรับปรุงมากมาย
ด้านข้อมูล:
ด้านรหัส:
นอกจากนี้ยังมีศิลปะก่อนหน้านี้มากมายในพื้นที่นี้ แม้ว่าฉันจะไม่สามารถแสดงรายการทั้งหมดที่นี่ได้ แต่ก็มีบางอย่างที่โดดเด่นเป็นแรงบันดาลใจในการกลับคืน


