revery
1.0.0
Revey adalah mesin pencari semantik yang beroperasi pada indeks pencarian monocle saya. Sementara Revey memungkinkan saya mencari melalui database yang sama dengan puluhan ribu catatan, bookmark, entri jurnal, tweet, kontak, dan posting blog sebagai Monocle, fokus Revey tidak pada pencarian berbasis kata kunci yang dilakukan Monocle, tetapi bukan pada pencarian semantik -menemukan hasil yang secara topikal mirip dengan beberapa halaman web atau kueri, bahkan jika mereka tidak membagikan kata-kata yang sama. Ini tersedia sebagai ekstensi browser yang dapat memunculkan hasil yang relevan ke halaman saat ini, serta aplikasi web yang lebih standar menyerupai halaman pencarian Monocle.
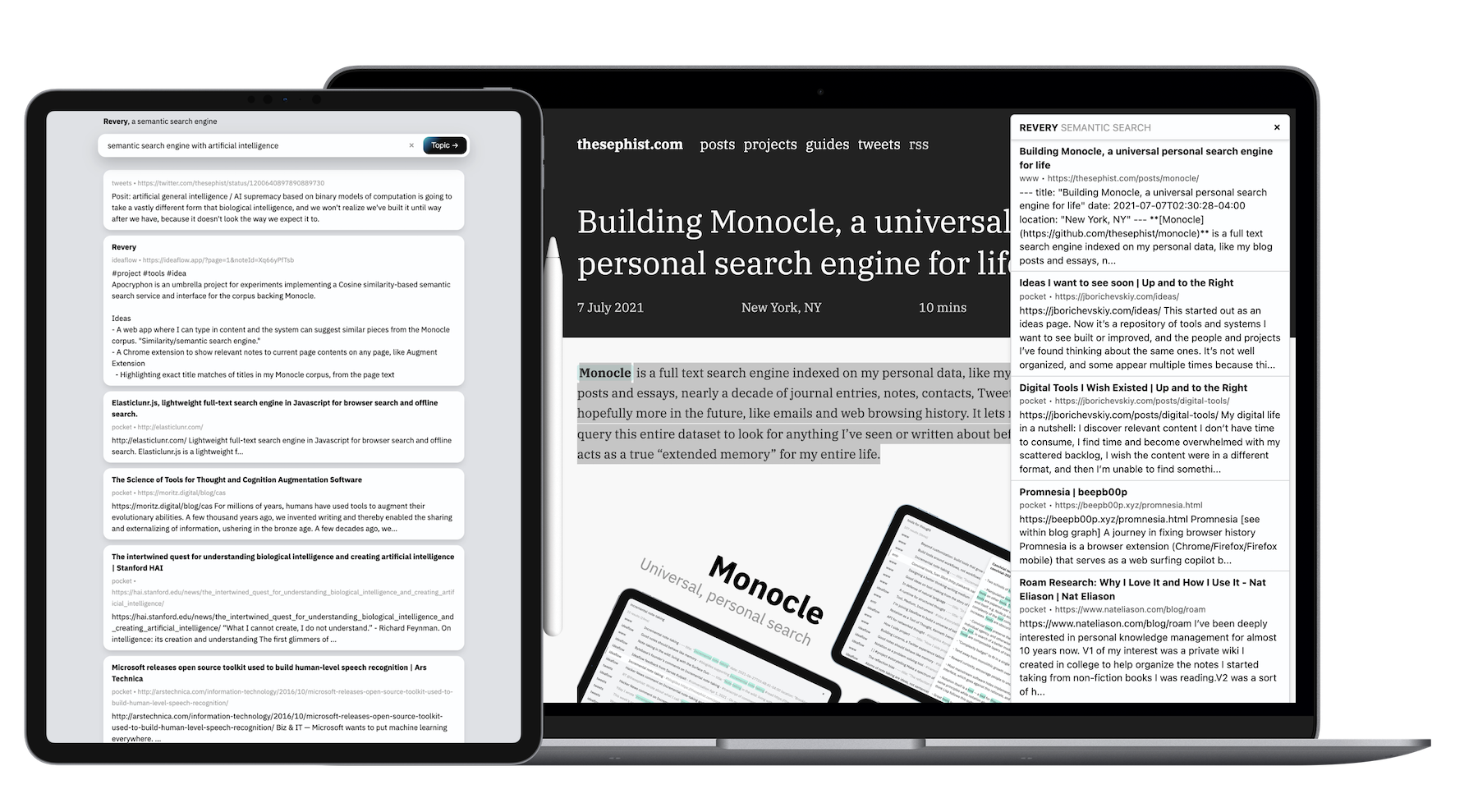
Tidak seperti kebanyakan proyek sampingan saya, karena ukuran data dan jumlah pekerjaan komputasi yang dibutuhkan Revery, backend -nya ditulis dalam perjalanan. Kedua klien - aplikasi web dan ekstensi browser - dibangun dengan torus.
Meskipun bekerja cukup baik bagi saya untuk menggunakannya setiap hari, Revey lebih merupakan prototipe bukti konsep daripada produk jadi. Saya ingin menunjukkan bahwa alat seperti ini dapat dibangun untuk penggunaan pribadi di atas alat produktivitas pribadi seperti catatan dan bookmark, dan mengalami bagaimana rasanya menelusuri web dan menulis dengan alat seperti itu.
Rever, pada intinya, hanyalah API tunggal. API mengambil beberapa teks, dan merangkak melalui koleksi dokumen dan catatan pribadi saya untuk menemukan yang teratas yang tampaknya paling terkait dengan teks yang diberikan. Untuk membuat ini menarik untuk digunakan, saya telah membungkusnya dengan dua antarmuka yang berbeda: ekstensi browser, dan antarmuka pencarian berbasis web yang lebih standar.
Ekstensi Browser Revey hidup di dalam ./extension di repositori ini, dan melakukan satu hal yang tepat: ketika saya menekan Ctrl-Shift-L pada halaman web apa pun yang saya lihat, itu akan mengikis tubuh utama teks dari halaman (atau bagian yang dipilih dari itu, jika saya menyoroti sesuatu) dan berbicara dengan API Revery untuk menemukan dokumen yang paling terkait dengan apa yang saya baca.

Di mana Monocle, dengan algoritma pencarian berbasis kata kunci, baik untuk ingatan, saya telah menemukan ekstensi hormat yang bagus untuk eksplorasi pada topik tertentu . Jika saya membaca tentang pemrosesan bahasa alami, misalnya, saya dapat menekan beberapa penekanan tombol untuk memunculkan artikel lain yang saya baca, atau catatan yang telah saya ambil di masa lalu, yang dapat saya referensi secara mental ketika saya membaca dan belajar tentang ide -ide baru di NLP.
Kami mempelajari ide -ide baru dengan baik ketika kami dapat menemukan titik referensi yang ada dalam memori kami di mana kami dapat melampirkan informasi baru. Ekstensi Revey sebagian mengotomatiskan dan mempercepat tugas itu. Sebagai contoh, saat membaca sebuah artikel tentang posisi budaya dan ekonomi Korea Selatan yang unik di dunia, Revey memunculkan beberapa buletin dan artikel terkait dari penulis dan sumber yang sama sekali berbeda tentang budaya pop Korea dan penurunan populasinya, yang membantu saya membingkai apa yang saya baca dalam konteks yang jauh lebih luas, terinformasi dengan baik.
Antarmuka pencarian web, bagi saya, sedikit sekunder untuk ekstensi. Ini ada terutama sebagai demonstrasi teknologi yang mendasari Revey, dan juga kebetulan sebagai cara bagi saya untuk menggunakan Revey ketika ekstensi tidak tersedia (seperti pada browser seluler).
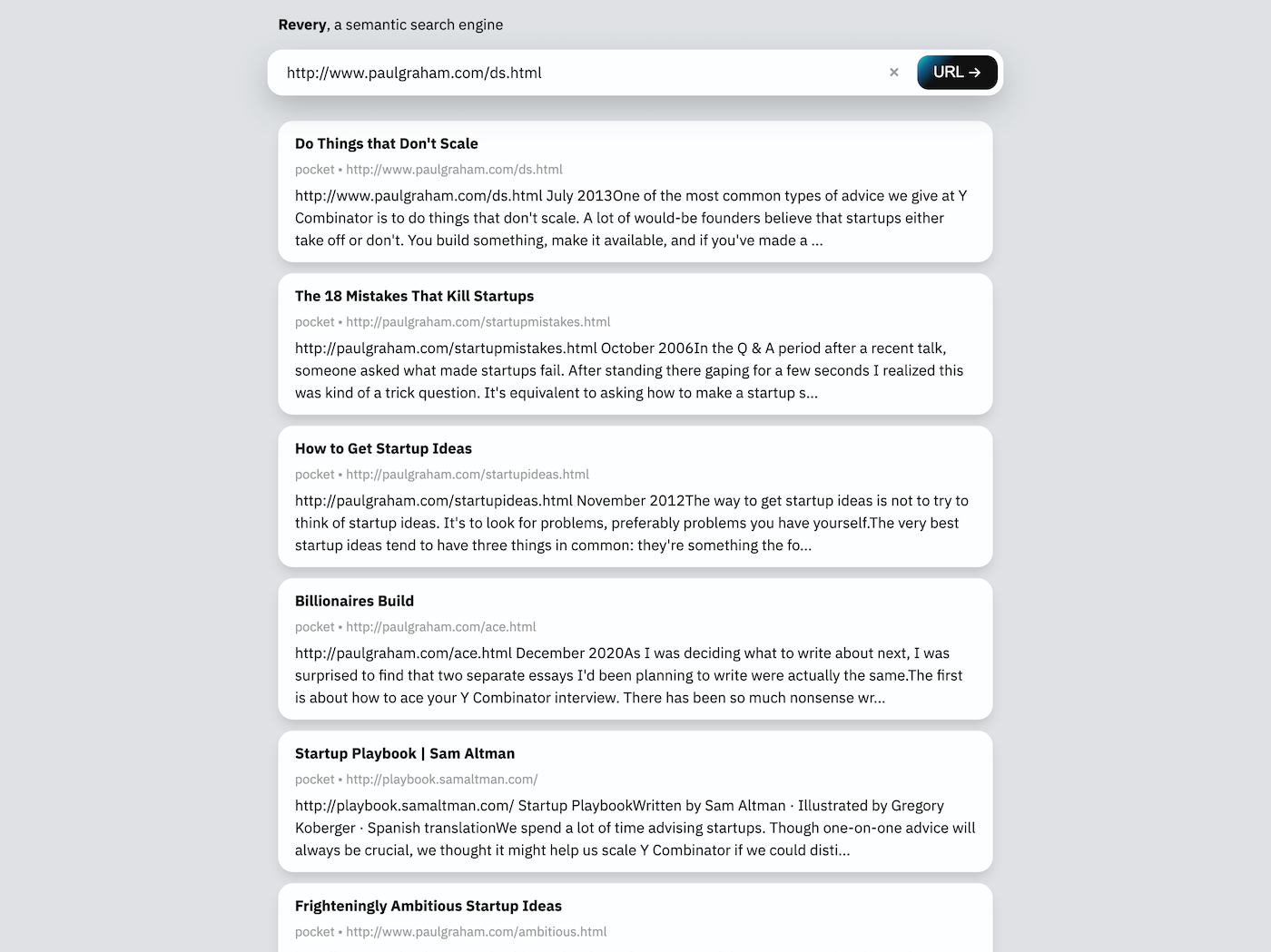
Bilah pencarian di antarmuka web dapat mengambil URL atau frasa kunci. Diberikan URL (seperti pada tangkapan layar di atas), Revey akan mengunduh dan membaca halaman web itu sendiri untuk menemukan dokumen terkait dalam indeks pencarian. Diberi frasa kunci, Revey akan mencoba menyarankan dokumen yang berisi kata -kata serupa dan berbicara tentang topik yang sama.
Jenis antarmuka pencarian ini (sebagai lawan dari ekstensi) berguna bagi saya untuk memulai memikirkan sesuatu yang baru, di mana saya dapat mengetikkan daftar kata-kata terkait ke dalam kotak pencarian dan segera mendapatkan daftar ide dan dokumen yang saya kenal dengan yang terkait, tanpa harus membuat pertanyaan pencarian spesifik dan dibuat dengan baik yang diperlukan oleh mesin pencarian berbasis kata kunci seperti yang diperlukan oleh Monocle.
Seperti disebutkan di atas, inti Revey adalah titik akhir API tunggal yang mengambil beberapa dokumen dan mengembalikan daftar sebagian besar dokumen terkait dari indeks pencarian saya. Apa yang membuat Revey istimewa adalah bahwa API ini melakukan pencarian semantik , bukan hanya pemindaian untuk kata kunci yang cocok. Ini berarti bahwa hasil teratas bahkan mungkin tidak berisi kata -kata yang sama dengan kueri, selama isinya relevan secara topikal.
Jenis pencarian semantik ini diaktifkan oleh algoritma pencarian yang menggunakan kemiripan cosinus dengan dokumen cluster embeddings dari dokumen yang diindeks. Jika itu terdengar seperti banyak kata acak bagi Anda (seperti halnya saya ketika saya memulai proyek ini), izinkan saya memecahnya:
Pertama, kita perlu memahami kata embeddings . Sebuah kata yang menanamkan adalah cara memetakan kosakata kata-kata bahasa alami ke beberapa titik di ruang angkasa (biasanya ruang matematika dimensi tinggi), sehingga kata-kata yang serupa dalam makna berdekatan dalam ruang ini. Sebagai contoh, kata "sains" dalam kata penyembatan akan sangat dekat dengan kata "ilmuwan", cukup dekat dengan "penelitian", dan kemungkinan sangat jauh dari "sirkus". Ketika kita berbicara tentang "jarak" dalam konteks embeddings kata, kita biasanya menggunakan kesamaan cosinus daripada jarak Euclidean, untuk alasan empiris dan teoretis yang tidak akan saya liput di sini.
Meskipun konsep embeddings kata tidak terlalu baru, masih ada penelitian aktif yang menghasilkan metode baru untuk menghasilkan lebih banyak dan lebih akurat dan berguna embeddings dari kumpulan data yang sama. Penyebaran pribadi saya menggunakan Dataset Embedding Kata Lisensi Creative Commons yang diproduksi oleh alat FastText Facebook, khususnya dataset 50.000 kata dengan 300 dimensi yang dilatih pada corpus crawl umum.
Word Embeddings mari kita menarik kesimpulan tentang kata -kata mana yang terkait, tetapi untuk hormat, kita ingin menggambar jenis kesimpulan yang sama tentang dokumen , yang merupakan daftar kata -kata. Untungnya, ada banyak literatur untuk menyarankan bahwa hanya mengambil rata -rata tertimbang dari vektor kata untuk setiap kata dalam dokumen dapat memberi kita perkiraan yang baik dari "vektor dokumen" yang mewakili dokumen secara keseluruhan. Meskipun ada metode yang lebih canggih yang dapat kita gunakan, seperti vektor paragraf atau model yang memperhitungkan urutan kata seperti Bert, rata -rata vektor kata bekerja cukup baik untuk kasus penggunaan Revey, dan mudah diimplementasikan dan diuji, jadi tongkat yang hormat dengan pendekatan ini.
Setelah kami dapat menghasilkan vektor dokumen dari dokumen menggunakan kata embedding kami, algoritma lainnya jatuh ke tempatnya. Pada saat startup, indeks server API Revey dan menghasilkan vektor dokumen untuk semua dokumen yang dapat ditemukan dalam dataset saya (yang tidak terlalu besar - sekitar 25.000 pada saat penulisan), dan pada setiap permintaan, algoritma menghitung vektor dokumen untuk dokumen yang diminta, dan mengurutkan setiap dokumen dalam indeks pencarian dengan jarak cosine ke dokumen Query, untuk mengembalikan NO top.
Di dalam Revey, setiap bagian dari algoritma ini ditulis tangan. Ini karena beberapa alasan:
Kedua klien Revey - ekstensi dan aplikasi web - berbicara dengan titik akhir API tunggal ini. Klien itu sendiri cukup biasa, jadi saya tidak akan membahas secara detail bagaimana mereka bekerja di sini.
Di sini, penafian yang sama yang saya bagikan dengan Monocle juga berlaku:
Revey tergantung pada indeks pencarian yang diproduksi oleh pengindeks Monocle, jadi saya biasanya memastikan Revey memiliki salinan indeks pencarian Monocle baru -baru ini yang tersedia sebelum berjalan.
Revey memiliki dua basis kode independen di repositori yang sama. Yang pertama adalah ekstensi chrome, yang hidup sepenuhnya di dalam folder ./extension . Begini cara saya mengaturnya:
Ekstensi membutuhkan token otentikasi API untuk berbicara dengan API Revey. Saya biasanya hanya memilih string acak panjang sewenang -wenang. Kemudian, saya menempatkan file di ./extension yang disebut token.js dengan konten:
const REVERY_TOKEN = '<some API key here>' ; Saya pergi ke chrome://extensions dan klik "muat unpacked" untuk memuat folder ./extension sebagai "ekstensi yang tidak dibuang" ke browser saya, yang akan membuat ekstensi tersedia di setiap tab.
Itu untuk pengaturan ekstensi. Selanjutnya, saya mengatur server:
tokens.txt di akar folder proyek. Server Revey akan mengambil konten yang dipangkas whitespace dari file ini dan menggunakannya sebagai kunci API.make akan membangun Binary revery yang dapat dieksekusi ke dalam folder proyek.docs.json Monocle yang dihasilkan oleh pengindeks ke ./corpus/docs.json .revery Executable sekarang harus dengan benar untuk memprosir model dan indeks pencarian, dan memulai server aplikasi web. Meskipun Revey cukup berguna bagi saya untuk menggunakan sehari -hari, ada banyak penelitian aktif di ruang pencarian bahasa alami umum, dan Revey sendiri memiliki banyak ruang untuk perbaikan.
Di sisi data:
Di sisi kode:
Ada juga banyak karya seni sebelumnya yang hebat di ruang ini. Meskipun saya tidak dapat mencantumkan semuanya di sini, ada beberapa yang menonjol sebagai inspirasi untuk Repey.


