revery
1.0.0
Revery是一种语义搜索引擎,可在我的Monocle搜索索引上运行。虽然Revery让我可以通过相同的数据库进行搜索,包括成千上万的笔记,书签,日记条目,推文,联系人和博客文章,但Revery的重点不是单镜可以执行的基于关键字的搜索,而是在语义搜索上进行的,而是在类似于给定的网页或Query或不共享同一单词的基于语义搜索上。它可作为浏览器扩展程序可用,可以将相关的结果呈现到当前页面,以及类似于Monocle的搜索页面的更标准的Web应用程序。
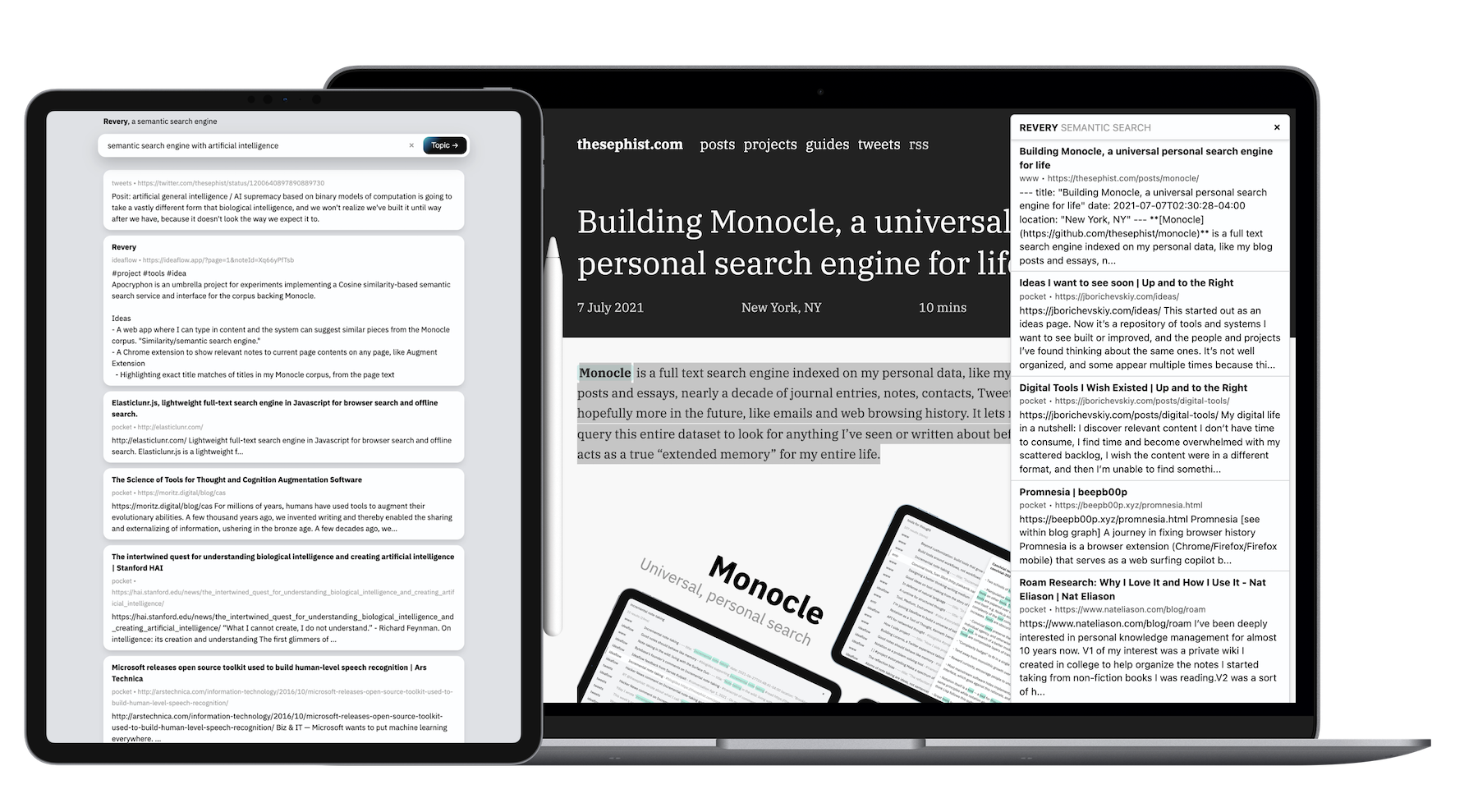
与我的大多数附带项目不同,由于数据的大小和计算工作的数量,它的后端是在GO中写成的。两个客户端(Web应用程序和浏览器扩展程序)都是由Torus构建的。
尽管它每天都可以使用它,但它每天都可以使用它,但Revery更像是概念验证的原型,而不是成品。我想证明可以在个人生产力工具(例如笔记和书签)上构建这样的工具,并体验浏览网络并使用这种工具写入的感觉。
Revery的核心只是一个API。 API收集了一些文本,并通过我的个人文档和注释收集的内容爬网,以找到与给定文本最局部相关的顶部文档。为了使此有趣的使用,我将其包装在两个不同的接口:浏览器扩展程序和一个基于Web的标准搜索界面。
Revery浏览器扩展存在于此存储库中的内部./extension当我查看的任何网页上击中Ctrl-Shift-L时,都会做一件事,它将从页面上刮擦文本的主体(或某些部分的部分,如果我强调了某些内容),并与Revery API与Revery API交谈以与我正在阅读的内容有关。

Monocle具有基于关键字的搜索算法,非常适合回忆,我发现Revery扩展非常适合探索特定主题。例如,如果我正在阅读有关自然语言处理的有关自然语言处理的信息,那么我可以击中一些击键,以提出我读过的其他文章,或者我过去记录的笔记,我可以在阅读并了解NLP中的新想法时进行精神参考。
当我们可以在内存中找到现有的参考点时,我们可以最好地学习新的想法,并在其中附加新信息。 REVER的扩展部分自动化并加快了该任务。例如,在阅读有关韩国在世界上独特的文化和经济地位的文章时,《狂欢》中的一些相关的新闻通讯和文章来自完全不同的作者和有关韩国流行文化及其人口下降的资源,这帮助我在更广泛,信息良好的环境中构筑了我正在阅读的内容。
对我而言,Web搜索界面是扩展名的次要。它主要是作为对Revery的基本技术的演示,也是顺便说一句,作为我在不可用时使用Reverre的一种方式(例如在移动浏览器上)。
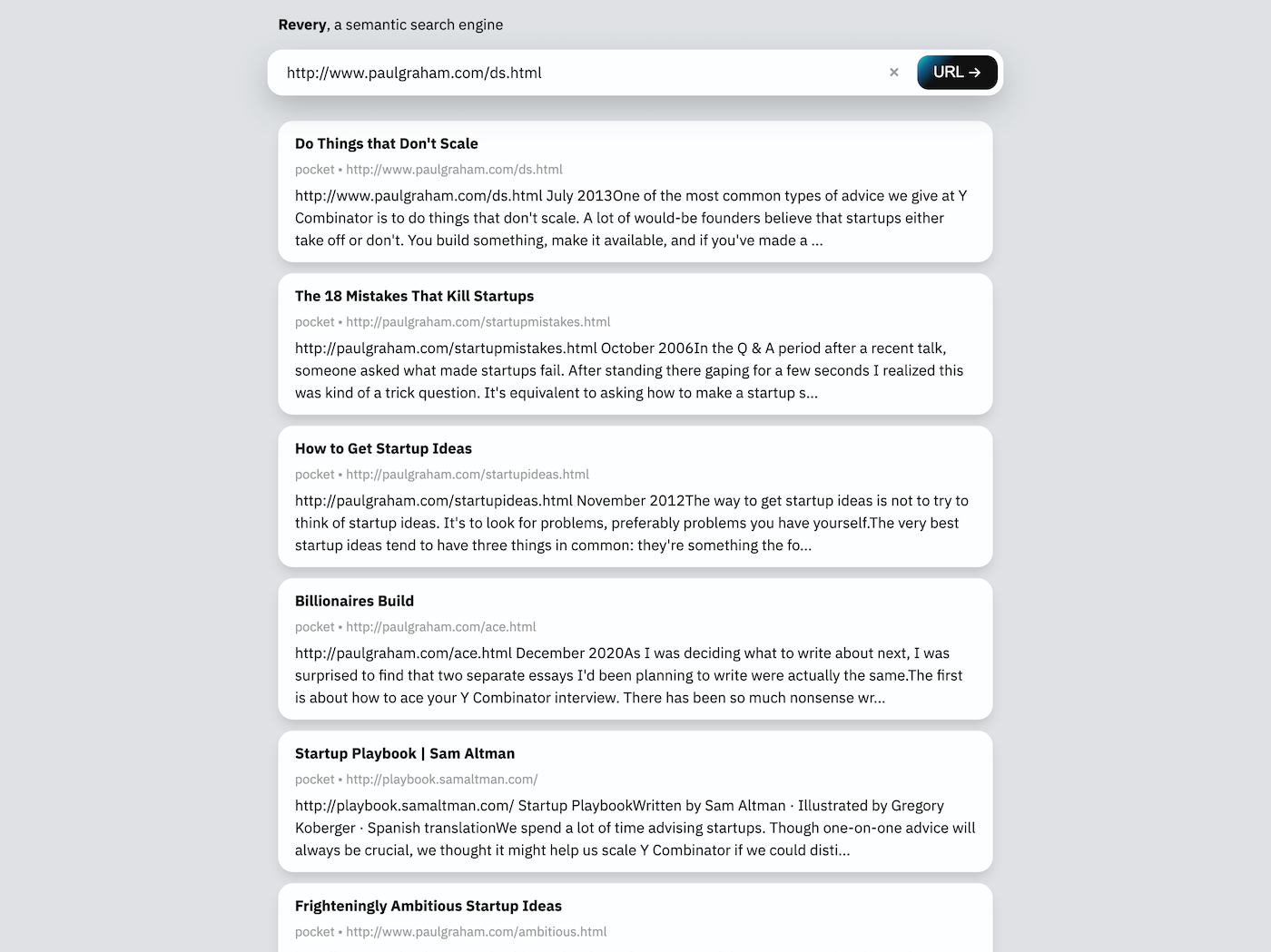
Web接口中的搜索栏可以使用URL或某些键短语。给定URL(如上面的屏幕截图),Revery将下载并阅读网页本身以在搜索索引中查找相关文档。给定一个关键短语,Revery将尝试提出包含类似单词的文档,并就类似主题讲话。
这种搜索界面(与扩展相反)对我开始思考新事物很有用,我可以在搜索框中输入相关单词列表,并立即获得我熟悉的我熟悉的想法和文档列表,而无需塑造特定且精心设计的搜索查询,这些查询像Monocle这样的关键字搜索引擎(例如Monocle(例如Monocle)所需的需求。
如上所述,Revery的核心是一个单个API端点,该端点吸收了一些文档,并从我的搜索索引中返回了大多数相关文档的列表。使Revery与众不同的是,此API执行语义搜索,而不仅仅是扫描匹配关键字的扫描。这意味着最高结果甚至可能不包含与查询相同的单词,只要其内容与局部相关。
这种语义搜索是通过搜索算法启用的,该算法使用余弦的相似性与索引文档的群集文档嵌入。如果这听起来像是您对您的一堆随机单词(就像我启动此项目时对我所做的那样),请让我分解:
首先,我们需要了解单词嵌入。嵌入单词是将自然语言单词词汇映射到空间中某些点(通常是高维数学空间)的一种方式,因此在此空间中,含义相似的单词相连。例如,嵌入单词中的“科学”一词将非常接近“科学家”一词,它与“研究”相当接近,并且可能与“马戏团”很远。当我们在单词嵌入的上下文中谈论“距离”时,我们通常使用余弦相似性而不是欧几里得距离,出于经验和理论原因,我在这里都不会介绍。
尽管单词嵌入的概念不是很新,但仍有积极的研究产生新的方法,以从相同的数据语料库中生成更准确和有用的单词嵌入。我对revery的个人部署使用Facebook的FastText工具生成的创意常见单词嵌入数据集,尤其是一个50,000字的数据集,其中具有300个维度,该数据集对公共爬网语料库进行了训练。
单词嵌入让我们提出有关哪些单词相关的推断,但是对于Revery,我们想对文档进行相同的推论,这些推论是单词列表。值得庆幸的是,有足够的文献建议文档中每个单词的加权平均值可以使我们获得代表整个文档的“文档向量”的良好近似。尽管我们可以使用更多的高级方法,例如段落或模型将单词顺序考虑在内,但平均文字向量可以很好地用于Revery的用例,并且易于实现和测试,因此请使用这种方法。
一旦我们可以使用嵌入单词从文档中生成文档向量,则其余算法就会出现。在启动时,REVERY的API服务器索引并生成文档向量,用于在我的数据集中找到的所有文档(在写作时不太大 - 约25,000个),并且在每个请求下,算法都为请求的文档计算一个文档向量,并通过搜索索引中的每个文档来返回QUERY ncepine docection cool QUERY DOMECTE,以返回Query n Top n最高n的结果。
在Revery中,该算法的每个部分都在GO中手写。这是出于一些原因:
Revery的两个客户 - 扩展名和Web应用程序 - 与这个单个API端点进行了交谈。客户本身很普通,因此我不会详细描述他们在这里的工作方式。
在这里,我与Monocle共享的同一免责声明也适用:
Revery取决于Monocle索引器所产生的搜索索引,因此我通常会确保Revery在运行之前提供了Monocle搜索索引的最新副本。
Revery在同一存储库中有两个独立的代码库。第一个是Chrome Extension,它完全居住在./extension文件夹中。这是我设置的方式:
该扩展名需要API身份验证令牌与Revery API进行对话。我通常只选择一个任意长的随机字符串。然后,我将一个文件token.js ./extension
const REVERY_TOKEN = '<some API key here>' ;我转到chrome://extensions ,然后单击“加载打开包装”,将./extension文件夹作为“未包装扩展”加载到我的浏览器中,这将使每个选项卡中的扩展名可用。
就是这样的扩展设置。接下来,我设置了服务器:
tokens.txt中,将其放入项目文件夹的根部。 Revery Server将获取此文件的Whitespace Trimmed内容,并将其用作API密钥。make将在项目文件夹中构建revery二进制执行。docs.json文档Document Document DataSet to ./corpus/docs.json 。revery可执行文件应正确预处理模型和搜索索引,然后启动Web应用程序服务器。 尽管Revery对我每天都有足够的用处,但是在一般的自然语言搜索空间中有很多积极的研究,而Revery本身也有很大的改进空间。
在数据方面:
在代码方面:
这个领域也有很多伟大的艺术。尽管我不能在这里列出所有这些,但有些人脱颖而出是Revery的灵感。


