revery
1.0.0
Revery هو محرك بحث دلالي يعمل على مؤشر البحث Monocle الخاص بي. على الرغم من أن Revery يتيح لي البحث من خلال نفس قاعدة البيانات لعشرات الآلاف من الملاحظات ، والإشارات المرجعية ، وإدخالات المجلات ، والتغريدات ، وجهات الاتصال ، ومشاركات المدونة كمونوكلي ، فإن تركيز Revery ليس على البحث القائم على الكلمات الرئيسية التي يؤديها Monocle ، ولكن بدلاً من ذلك على البحث الدلالي -العثور على نتائج تشبه إلى حد ما لبعض صفحة الويب أو الاستعلام المحددة ، حتى لو لم تشارك نفس الكلمات. يتوفر كملحق متصفح يمكن أن يبرز النتائج ذات الصلة إلى الصفحة الحالية ، بالإضافة إلى تطبيق ويب أكثر قياسيًا يشبه صفحة البحث في Monocle.
على عكس معظم مشاريعي الجانبية ، بسبب حجم البيانات وكمية العمل الحسابي الذي يتطلبه الأمر ، يتم كتابة الواجهة الخلفية في GO. تم تصميم كل من العملاء - تطبيق الويب وملحق المتصفح - مع Torus.
على الرغم من أنه يعمل بشكل جيد بما يكفي لاستخدامه كل يوم ، إلا أن Revery هو نموذج أولي من إثبات المفهوم من المنتج النهائي. أردت أن أثبت أنه يمكن بناء أداة كهذه للاستخدام الشخصي أعلى أدوات الإنتاجية الشخصية مثل الملاحظات والإشارات المرجعية ، وتجربة ما سيكون عليه تصفح الويب والكتابة بهذه الأداة.
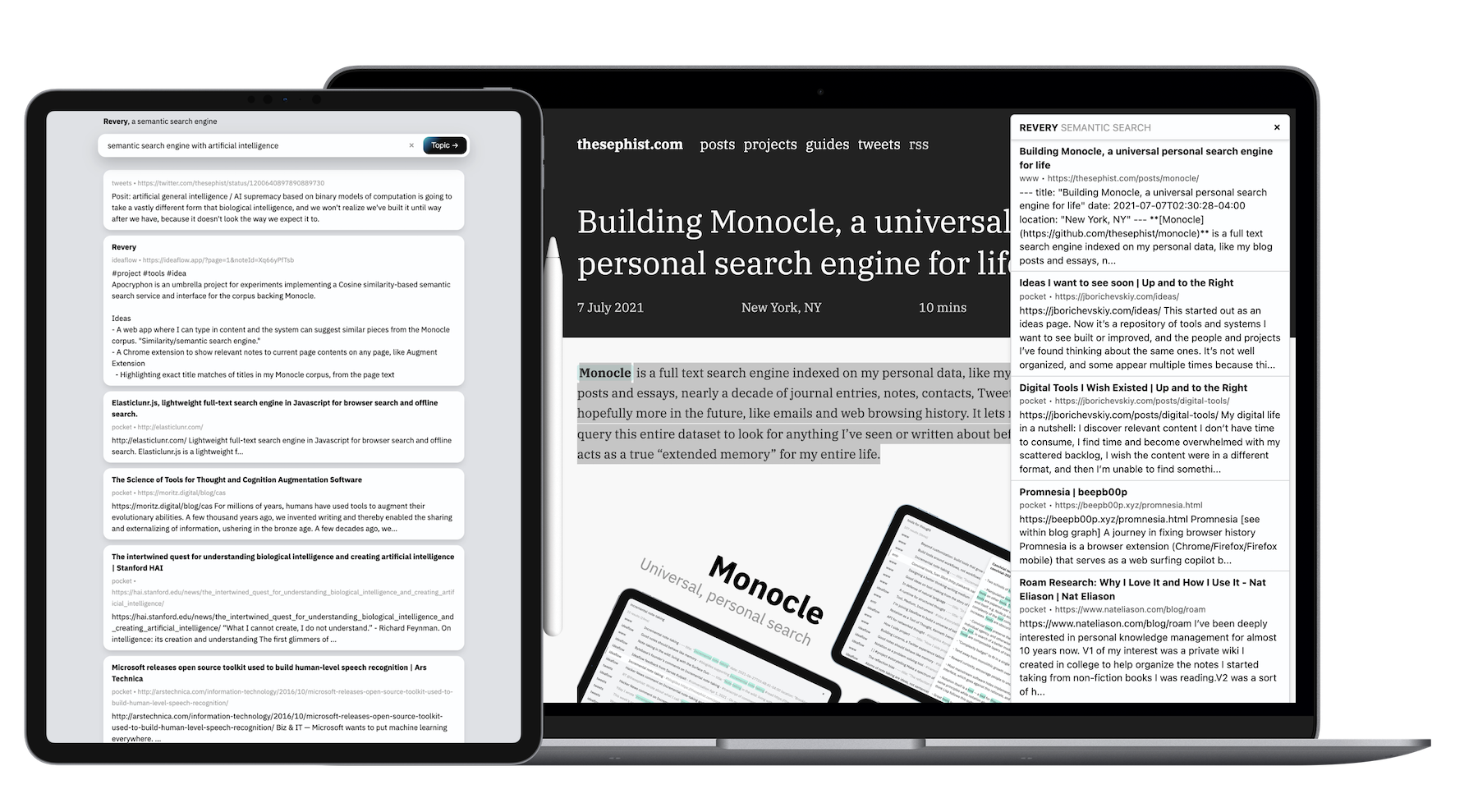
REDERY ، في جوهرها ، هي مجرد واجهة برمجة تطبيقات واحدة. يأخذ واجهة برمجة التطبيقات في بعض النصوص ، وينزح من خلال مجموعتي من المستندات والملاحظات الشخصية للعثور على أعلى الدرجات التي تبدو أكثر ارتباطًا بالنص المحدد. لجعل هذا الأمر مثيرًا للاهتمام للاستخدام ، قمت بلفه في واجهتين مختلفتين: امتداد المتصفح ، وواجهة بحث أكثر قياسية على الويب.
Ctrl-Shift-L امتداد المتصفح REDERY في الداخل ./extension

عندما يكون Monocle ، مع خوارزمية البحث المستندة إلى الكلمات الرئيسية ، مفيدًا للتذكر ، فقد وجدت امتدادًا كبيرًا لاستكشافات حول موضوع معين . إذا كنت أقرأ عن معالجة اللغة الطبيعية ، على سبيل المثال ، يمكنني الوصول إلى بعض ضربات المفاتيح لإظهار مقالات أخرى قرأتها ، أو الملاحظات التي أخذتها في الماضي ، والتي يمكنني الرجوع إليها عقلياً أثناء قراءة وأتعرف على الأفكار الجديدة في NLP.
نتعلم أفضل أفكار جديدة عندما نتمكن من العثور على النقاط المرجعية الحالية في ذاكرتنا والتي يمكننا إرفاق معلومات جديدة عليها. يعد امتداد Revery أتمتة ويسرع هذه المهمة جزئيًا. على سبيل المثال ، أثناء قراءة مقال عن الوضع الثقافي والاقتصادي الفريد لكوريا الجنوبية في العالم ، ظهرت على عدد قليل من النشرات الإخبارية والمقالات ذات الصلة من مؤلفين ومصادر مختلفة تمامًا عن ثقافة البوب الكورية وانخفاض سكانها ، مما ساعدني على تأطير ما كنت أقرأه في سياق أكثر إدراكًا ومستفيدًا.
واجهة بحث الويب ، بالنسبة لي ، هي ثانوية قليلاً للتمديد. إنه موجود في المقام الأول كدليل على التكنولوجيا الأساسية لـ Revery ، وكذلك بالمناسبة كوسيلة بالنسبة لي لاستخدام REDERY عندما لا يكون التمديد متاحًا (مثل متصفح الهاتف المحمول).
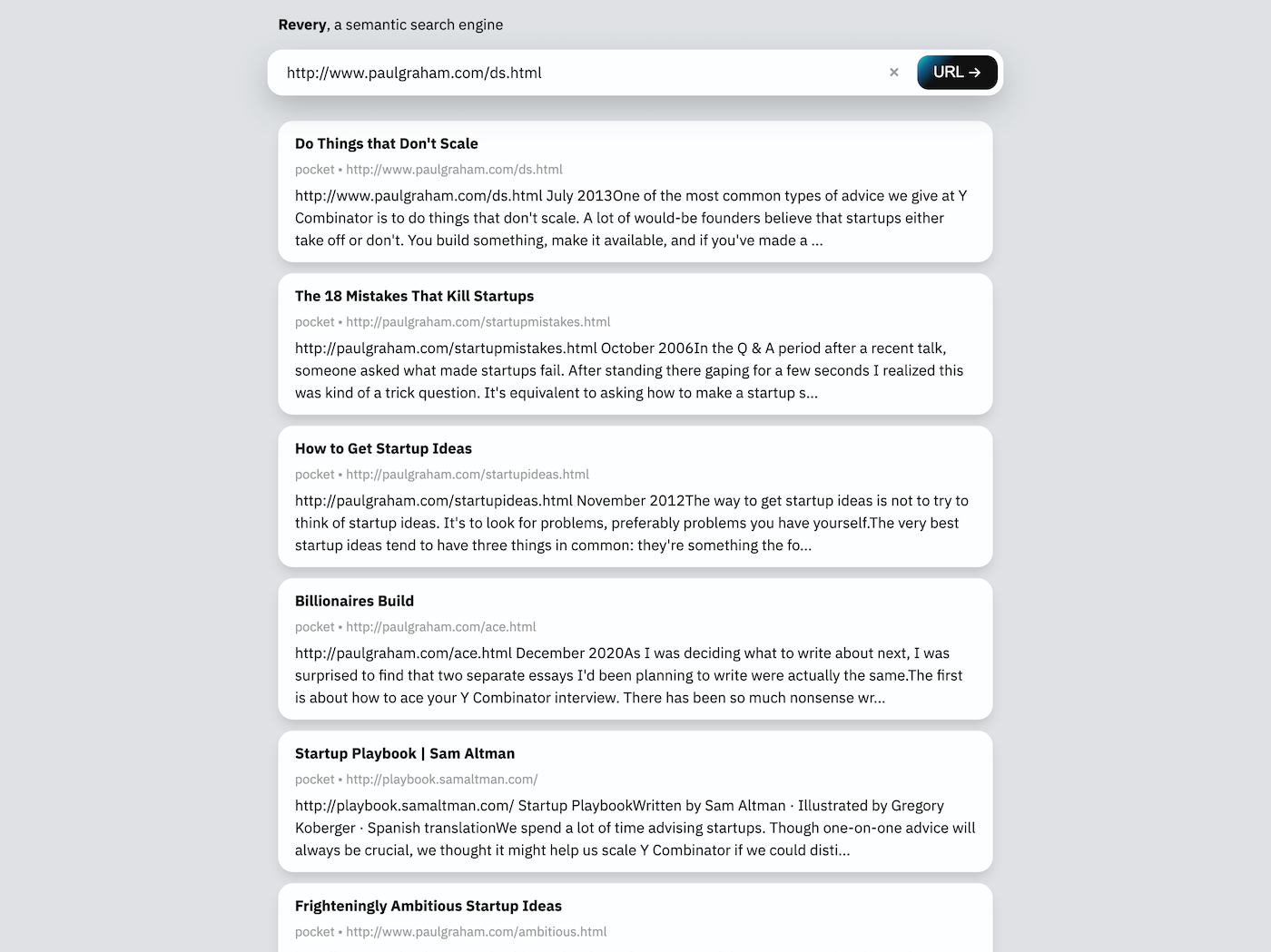
يمكن أن يأخذ شريط البحث في واجهة الويب إما عنوان URL أو عبارة رئيسية. بالنظر إلى عنوان URL (كما في لقطة الشاشة أعلاه) ، ستقوم Revery بتنزيل وقراءة صفحة الويب نفسها للعثور على المستندات ذات الصلة في فهرس البحث. بالنظر إلى عبارة رئيسية ، ستحاول Revery اقتراح مستندات تحتوي على كلمات مماثلة وتتحدث عن مواضيع مماثلة.
يعد هذا النوع من واجهة البحث (على عكس التمديد) مفيدًا بالنسبة لي لبدء التفكير في شيء جديد ، حيث يمكنني كتابة قائمة بالكلمات ذات الصلة في مربع البحث والحصول على قائمة بالأفكار والمستندات التي أعرفها على الفور ، دون الاضطرار إلى تصميم استعلامات البحث المحددة والمصممة جيدًا التي تتطلب محركات البحث القائمة على الكلمات الرئيسية مثل Monocle.
كما ذكر أعلاه ، فإن REDERY's Core هي نقطة نهاية API واحدة تأخذ في بعض المستندات وتُرجع قائمة بأكثر المستندات ذات الصلة من فهرس البحث الخاص بي. ما يجعل REDERY مميزًا هو أن واجهة برمجة التطبيقات هذه تقوم ببحث دلالي ، وليس مجرد فحص لمطابقة الكلمات الرئيسية. هذا يعني أن النتائج العليا قد لا تحتوي حتى على نفس الكلمات مثل الاستعلام ، طالما أن محتوياته ذات صلة موضعيا.
يتم تمكين هذا النوع من البحث الدلالي من خلال خوارزمية البحث التي تستخدم تشابه جيب التمام لتضمينات المستندات الكتلة للمستندات المفهرسة. إذا كان هذا يبدو وكأنه حفنة من الكلمات العشوائية لك (كما فعلت بالنسبة لي عندما بدأت هذا المشروع) ، دعني أتقسمه:
أولاً ، سنحتاج إلى فهم تضمينات الكلمات . تعد كلمة تضمينها وسيلة لتخطيط مفردات من كلمات اللغة الطبيعية إلى بعض النقاط في الفضاء (عادةً ما تكون مساحة رياضية عالية الأبعاد) ، بحيث تكون الكلمات المتشابهة في المعنى قريبة معًا في هذا الفضاء. على سبيل المثال ، ستكون كلمة "العلم" في كلمة تضمينها قريبة جدًا من كلمة "عالم" ، قريبة بشكل معقول من "البحث" ، ومن المحتمل أن تكون بعيدة جدًا عن "Circus". عندما نتحدث عن "المسافة" في سياق تضمينات الكلمات ، عادة ما نستخدم تشابه جيب التمام بدلاً من المسافة الإقليدية ، لأسباب تجريبية ونظرية على حد سواء لن أغطيها هنا.
على الرغم من أن مفهوم تضمينات الكلمات ليس بالأمر الجديد للغاية ، إلا أنه لا يزال هناك بحث نشط ينتج طرقًا جديدة لتوليد المزيد من تضمينات الكلمات الدقة والمفيدة من نفس مجموعة البيانات. يستخدم نشري الشخصي لـ REDERY مجموعة بيانات تضمين الكلمات المرخصة من Creative Commons التي تنتجها أداة FastText على Facebook ، وتحديداً مجموعة بيانات مكونة من 50000 كلمة مع 300 أبعاد مدربة على مجموعة الزحف المشتركة.
دعنا نطالب الكلمات التي ترسم استنتاجات حول الكلمات ذات الصلة ، ولكن من أجل العودة ، نريد أن نرسم نفس النوع من الاستدلال حول المستندات ، والتي هي قائمة بالكلمات. لحسن الحظ ، هناك أدبيات وافرة تشير إلى أن مجرد أخذ متوسط مرجح من ناقلات الكلمات لكل كلمة في المستند يمكن أن تجعلنا تقريبا جيدا لـ "متجه المستند" الذي يمثل المستند ككل. على الرغم من أن هناك طرقًا أكثر تقدمًا يمكننا استخدامها ، مثل متجهات الفقرة أو النماذج التي تأخذ ترتيب الكلمات في الاعتبار مثل Bert ، فإن متوسط ناقلات الكلمات تعمل بشكل جيد بما يكفي من أجل استخدام حالات استخدام ، وبسيطة في التنفيذ واختبارها ، لذلك تتمسك بهذا النهج.
بمجرد أن نتمكن من إنشاء متجهات المستندات خارج المستندات باستخدام تضمين كلماتنا ، فإن بقية الخوارزمية تقع في مكانها. في بدء التشغيل ، تقوم REPY'S API Server بفهارس وإنشاء متجهات المستندات لجميع المستندات التي يمكن أن تجدها في مجموعة البيانات الخاصة بي (وهي ليست كبيرة جدًا - حوالي 25000 وقت في كتابة هذا التقرير) ، وعلى كل طلب ، تقوم الخوارزمية بحساب ناقل المستند للوثيقة المطلوبة ، وفرز كل مستند في مؤشر البحث عن طريق مسافة مسافة التجميل إلى وثيقة الفاصل ، لإرجاع بعض النتائج.
في غضون عودة ، كل جزء من هذه الخوارزمية مكتوب يدويًا. هذا لعدة أسباب:
كل من عملاء REDERY - الامتداد وتطبيق الويب - يتحدثون إلى نقطة نهاية API الفردية هذه. العملاء أنفسهم عاديون تمامًا ، لذلك لن أخوض في التفاصيل واصفًا كيف يعملون هنا.
هنا ، ينطبق نفس إخلاء المسؤولية التي شاركتها مع Monocle:
يعتمد Revery على فهرس البحث الذي ينتج عن Monocle's Indexer ، لذلك عادةً ما أتأكد من أن Revery لديه نسخة حديثة من فهرس البحث Monocle المتاحة قبل التشغيل.
Revery لديه اثنين من codebases مستقلة في نفس المستودع. الأول هو امتداد الكروم ، الذي يعيش بالكامل داخل مجلد ./extension . إليك كيفية إعداده:
يحتاج الامتداد إلى رمز مصادقة API للتحدث إلى API REDERY. عادة ما أختار سلسلة عشوائية طويلة بشكل تعسفي. ثم أضع ملفًا في ./extension يسمى token.js مع المحتوى:
const REVERY_TOKEN = '<some API key here>' ; أذهب إلى chrome://extensions وانقر فوق "تحميل إلغاء التعبئة" لتحميل مجلد ./extension كـ "امتداد غير معبأ" في متصفحي ، مما سيجعل التمديد متاحًا في كل علامة تبويب.
هذا كل شيء لإعداد التمديد. بعد ذلك ، قمت بإعداد الخادم:
tokens.txt في جذر مجلد المشروع. سيحصل خادم REDERY على المحتوى المقطوع من مساحة البيضاء لهذا الملف ويستخدمه كمفتاح API.make سيقوم ببناء الثنائي revery للتنفيذ في مجلد المشروع.docs.json Monocle التي تم إنشاؤها بواسطة المفهرس إلى ./corpus/docs.json .revery COMMANT الآن بشكل صحيح معالجة النموذج وفهرس البحث ، وبدء تشغيل خادم تطبيق الويب. على الرغم من أن REDERY مفيد بما يكفي بالنسبة لي لاستخدام اليومية ، إلا أن هناك الكثير من الأبحاث النشطة في مساحة البحث في اللغة الطبيعية العامة ، ويتمتع Revery نفسها بالكثير من التحسينات.
على جانب البيانات:
على جانب الكود:
هناك أيضا الكثير من الفن السابق الرائع في هذا الفضاء. على الرغم من أنني لا أستطيع إدراجهم جميعًا هنا ، إلا أن هناك بعضًا يبرز كإلهام للعودة.


