revery
1.0.0
Reveryは、私のモノクル検索インデックスで動作するセマンティック検索エンジンです。 Reveryを使用すると、数万のノート、ブックマーク、ジャーナルエントリ、ツイート、連絡先、ブログの投稿の同じデータベースをモノクルとして検索できますが、Reveryの焦点は、Monocleが実行するキーワードベースの検索ではなく、同じワードを共有していても、与えられたWebページやクエリに類似した結果を見つけることができます。これは、現在のページに関連する結果を浮上させることができるブラウザ拡張機能と、Monocleの検索ページに似たより標準的なWebアプリとして利用できます。
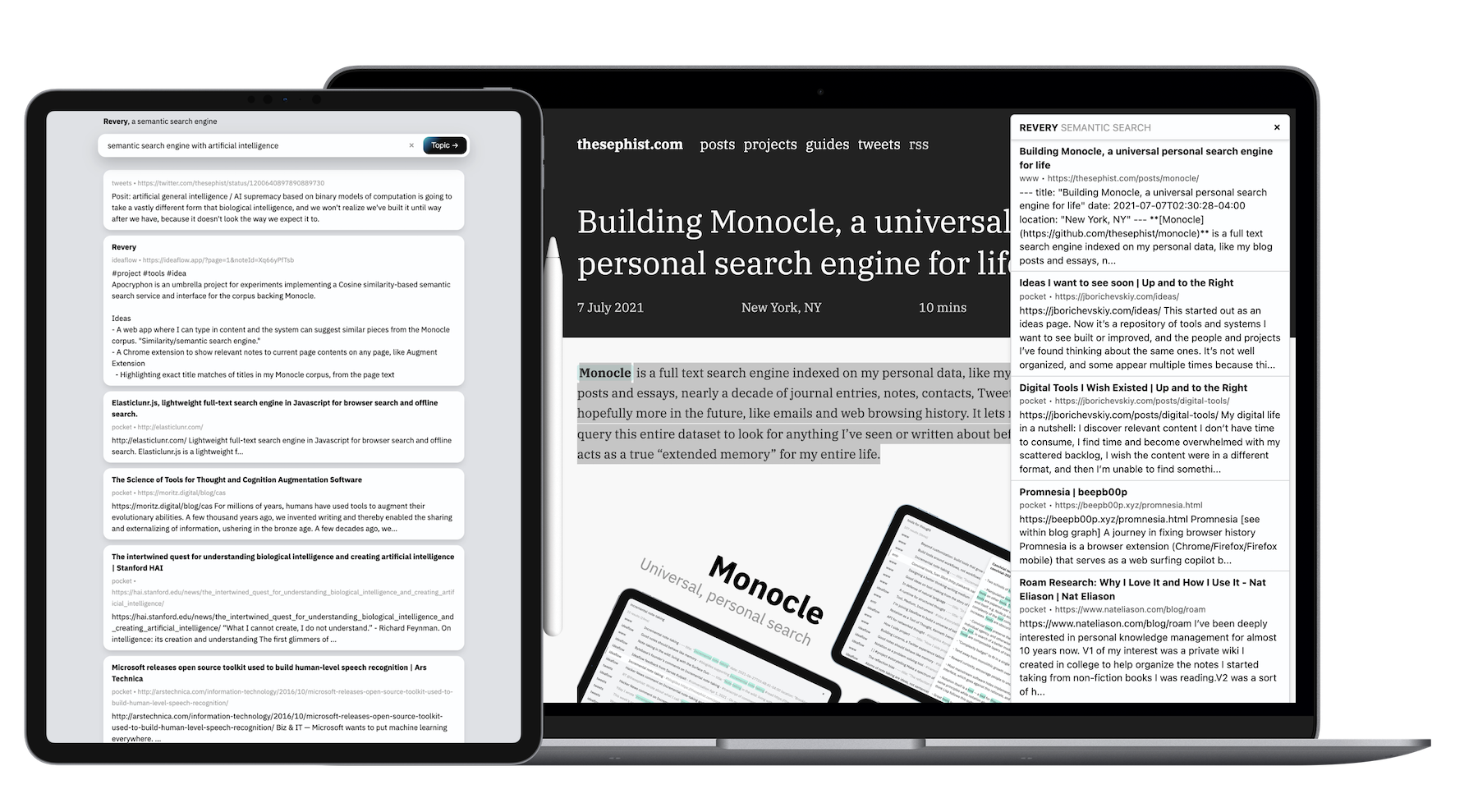
私のサイドプロジェクトのほとんどとは異なり、データのサイズと計算作業の量が必要な量のために、そのバックエンドはGOで記述されます。両方のクライアント(Webアプリとブラウザ拡張機能)は、Torusで構築されています。
毎日それを使用するのに十分なほどうまく機能しますが、Reveryは完成品よりも概念実証のプロトタイプです。このようなツールは、メモやブックマークなどの個人的な生産性ツールに加えて個人的な使用のために構築され、そのようなツールでWebを閲覧して書くのがどのように感じるかを体験できることを実証したかったのです。
Reveryは、そのコアにあるものは、単一のAPIです。 APIはいくつかのテキストを取り入れ、私の個人的な文書とメモのコレクションをcraい、指定されたテキストに最も局所的に関連していると思われる上位のものを見つけます。これを面白くするために、ブラウザ拡張機能と、より標準のWebベースの検索インターフェイスという2つの異なるインターフェイスに包みました。
Revery Browser拡張機能./extension 、このリポジトリの内部にあり、正確に1つのことを行います。表示しているWebページでCtrl-Shift-Lにヒットすると、ページからテキストのメインボディをこすります(または、選択した部分)を削り、Revery APIに話しかけて、私が読んでいるものを最も関連する文書を見つけます。

キーワードベースの検索アルゴリズムを備えたMonocleは、回想に適している場合、特定のトピックの調査に最適なRevery Extensionがわかりました。たとえば、自然言語処理について読んでいる場合、いくつかのキーストロークを叩いて、私が読んだ他の記事や過去に撮ったメモを育てることができます。
新しい情報を添付できることに、メモリ内の既存の参照ポイントを見つけることができるとき、新しいアイデアを最もよく学びます。 Reveryの拡張機能は、そのタスクを部分的に自動化し、高速化します。たとえば、世界における韓国のユニークな文化的および経済的地位に関する記事を読んでいる間、韓国のポップカルチャーとその人口減少に関する完全に異なる著者や情報源からいくつかの関連するニュースレターや記事を表面化しました。
私にとって、Web検索インターフェイスは、拡張機能に少し順行しています。それは主に、Reveryの基礎となるテクノロジーのデモとして、また偶然にも、拡張機能が利用できない場合(モバイルブラウザのように)Reveryを使用する方法として存在します。
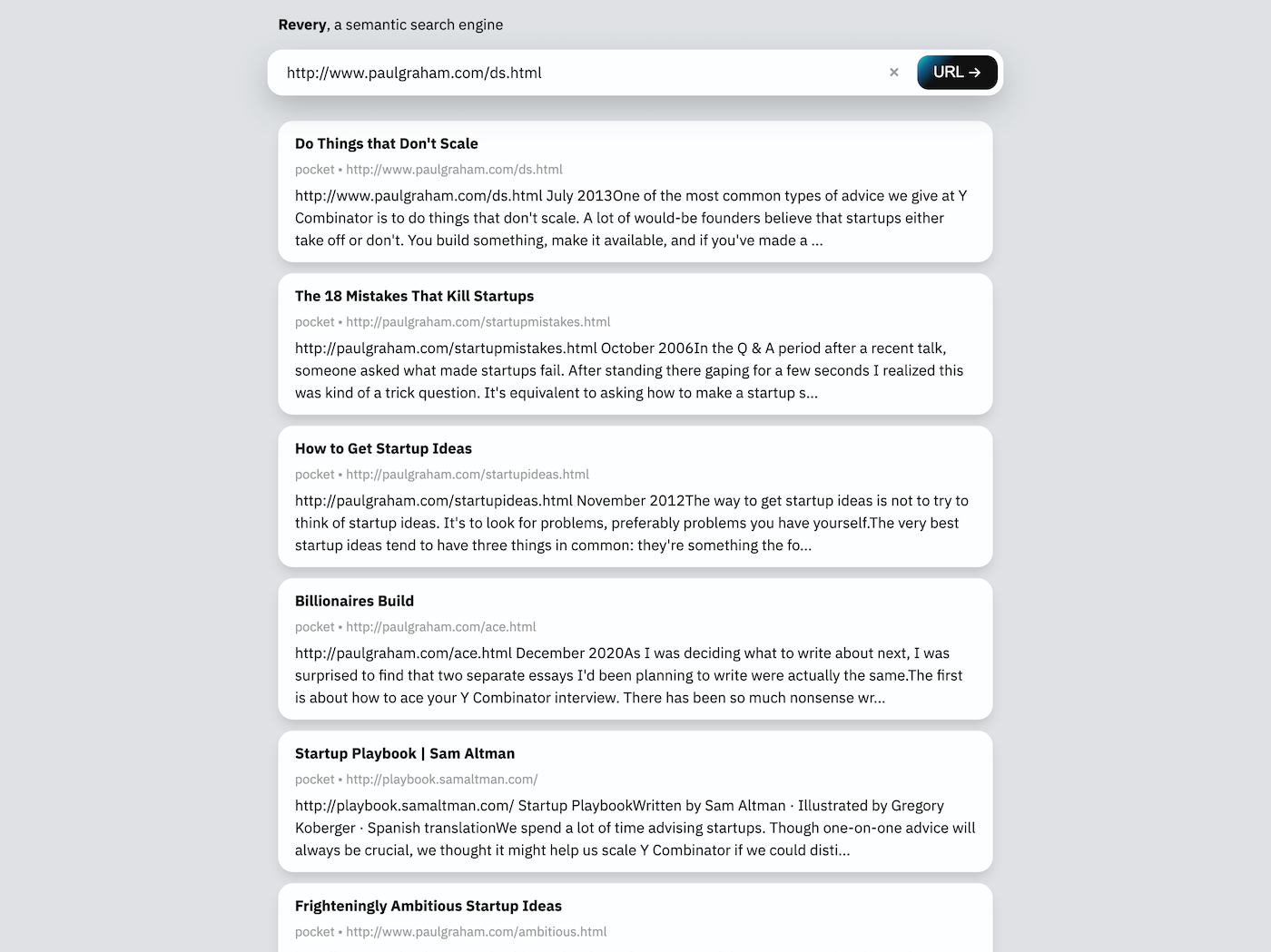
Webインターフェイスの検索バーは、URLまたはキーフレーズのいずれかを採取できます。 URL(上記のスクリーンショットのように)が与えられた場合、ReveryはWebページ自体をダウンロードして読み取り、検索インデックスに関連ドキュメントを見つけます。重要なフレーズを考えると、Reveryは同様の単語を含むドキュメントを提案し、同様のトピックについて話そうとします。
この種の検索インターフェイス(拡張機能とは対照的に)は、新しいことを考え始めるのに役立ちます。ここで、関連する単語のリストを検索ボックスに入力し、モノクルのようなキーワードベースの検索エンジンが必要とする特定のよく作成された検索クエリを作成することなく、関連するアイデアやドキュメントのリストをすぐに取得できます。
上記のように、Reveryのコアは、いくつかのドキュメントを取り入れ、検索インデックスから最も関連するドキュメントのリストを返す単一のAPIエンドポイントです。 Reveryを特別なものにしているのは、このAPIがキーワードを一致させるためのスキャンではなく、セマンティック検索を実行することです。これは、その内容が局所的に関連性がある限り、トップの結果にクエリと同じ単語さえ含まれていないことを意味します。
この種のセマンティック検索は、インデックス付きドキュメントのクラスタードキュメント埋め込みとCosineの類似性を使用する検索アルゴリズムによって有効になります。それがあなたにランダムな言葉の束のように聞こえるなら(私がこのプロジェクトを始めたときに私にしたように)、それを分解させてください:
まず、単語の埋め込みを理解する必要があります。単語の埋め込みは、自然言語の単語の語彙を空間のいくつかのポイント(通常は高次元数学空間)にマッピングする方法であり、意味が似ている単語がこの空間で近くにあるようにします。たとえば、単語の埋め込みという言葉の「科学」は、「科学者」という言葉に非常に近く、「研究」に合理的に近く、「サーカス」から非常に遠いでしょう。単語の埋め込みの文脈で「距離」について話すとき、私たちは通常、ユークリッドの距離ではなくコサインの類似性を使用します。
単語の埋め込みの概念はそれほど新しいものではありませんが、同じデータのコーパスからますます正確で有用な単語埋め込みを生成するための新しい方法を生み出す積極的な研究がまだあります。私の個人的な展開は、FacebookのFastTextツール、特に一般的なクロールコーパスで訓練された300の寸法を備えた50,000ワードのデータセットによって作成されたクリエイティブコモンズライセンスのワードエンミングデータセットを使用しています。
単語の埋め込みは、どの単語が関連しているかについて推論を描画できますが、reveryのために、単語のリストであるドキュメントについて同じ種類の推論を描きたいと思います。ありがたいことに、ドキュメント内のすべての単語に対して単語ベクトルの加重平均を使用するだけで、ドキュメント全体を表す「ドキュメントベクター」の適切な近似値を得ることができることを示唆する十分な文献があります。 Bertのような言葉の順序を考慮する段落ベクターやモデルなど、より高度な方法がありますが、平均的な単語ベクトルは、Reveryのユースケースに十分に機能し、実装とテストが簡単であるため、このアプローチにはReveryが固執します。
単語の埋め込みを使用してドキュメントからドキュメントベクトルを生成できたら、アルゴリズムの残りの部分が所定の位置に分類されます。スタートアップでは、ReveryのAPIサーバーインデックスをインデックス化して、データセットで見つけることができるすべてのドキュメント(執筆時点で約25,000)で見つけられるすべてのドキュメントのドキュメントベクトルを生成し、すべてのリクエストで、アルゴリズムは要求されたドキュメントのドキュメントベクトルを計算し、検索インデックスのすべてのドキュメントをCOSIREドキュメントに並べ替え、クエリの結果を返します。
再によって、このアルゴリズムのすべての部分がGOで手書きされています。これはいくつかの理由です:
Reveryのクライアント(拡張機能とWebアプリ)は、この単一のAPIエンドポイントに相談してください。クライアント自体は非常に普通であるため、ここでどのように機能するかについて詳しく説明しません。
ここで、私がモノクルと共有したのと同じ免責事項も適用されます。
Reveryは、Monocleのインデクサーによって作成された検索インデックスに依存しているため、通常、Reverが実行する前にMonocleの検索インデックスの最近のコピーがあることを確認します。
Reveryには、同じリポジトリに2つの独立したコードベースがあります。 1つ目は、 ./extensionフォルダー内に完全に存在するChrome拡張機能です。これが私がそれをセットアップする方法です:
拡張機能には、Revery APIと通信するためにAPI認証トークンが必要です。私は通常、任意の長いランダムな文字列を選択します。次に、コンテンツを使用してtoken.jsと呼ばれる./extensionにファイルを配置します。
const REVERY_TOKEN = '<some API key here>' ; chrome://extensionsに移動し、[[アンパック]の読み込み]をクリックして、 ./extensionアンデレクション]フォルダーを[アンダーエクステンション]としてブラウザにロードします。これにより、すべてのタブで拡張機能が利用可能になります。
それは拡張セットアップのためです。次に、サーバーを設定します。
tokens.txt内にトークンストリング自体を配置します。 Reveryサーバーは、このファイルのWhitespace-Trimmedコンテンツを取得し、APIキーとして使用します。makeするだけで、 revery Binary Exectabalがプロジェクトフォルダーに組み込まれます。docs.json Document Datasetをコピーして、インデクサーが./corpus/docs.jsonに生成しました。revery Exectableを実行すると、モデルと検索インデックスを正しく処理し、Webアプリケーションサーバーを起動する必要があります。 私は日々使用するのに十分なほど便利ですが、一般的な自然言語の検索スペースには多くの積極的な研究があり、Revery自体には改善の余地がたくさんあります。
データ側:
コード側:
また、この分野にはたくさんの素晴らしい以前のアートがあります。ここにすべてリストすることはできませんが、reveryのインスピレーションとして際立っている人がいくつかあります。


