revery
1.0.0
Revery est un moteur de recherche sémantique qui fonctionne sur mon index de recherche Monocle. Bien que Revery me permette de rechercher la même base de données de dizaines de milliers de notes, de signets, d'entrées de journal, de tweets, de contacts et de messages de blog en tant que monocle, la reveryme n'est pas sur la recherche basée sur les mots clés que Monocle effectue, mais plutôt sur la recherche sémantique - trouver des résultats topiquement similaires à une page Web ou une requête donnée, même si elles ne partagent pas les mêmes mots. Il est disponible en tant qu'extension de navigateur qui peut faire surface des résultats pertinents à la page actuelle, ainsi qu'une application Web plus standard ressemblant à la page de recherche de Monocle.
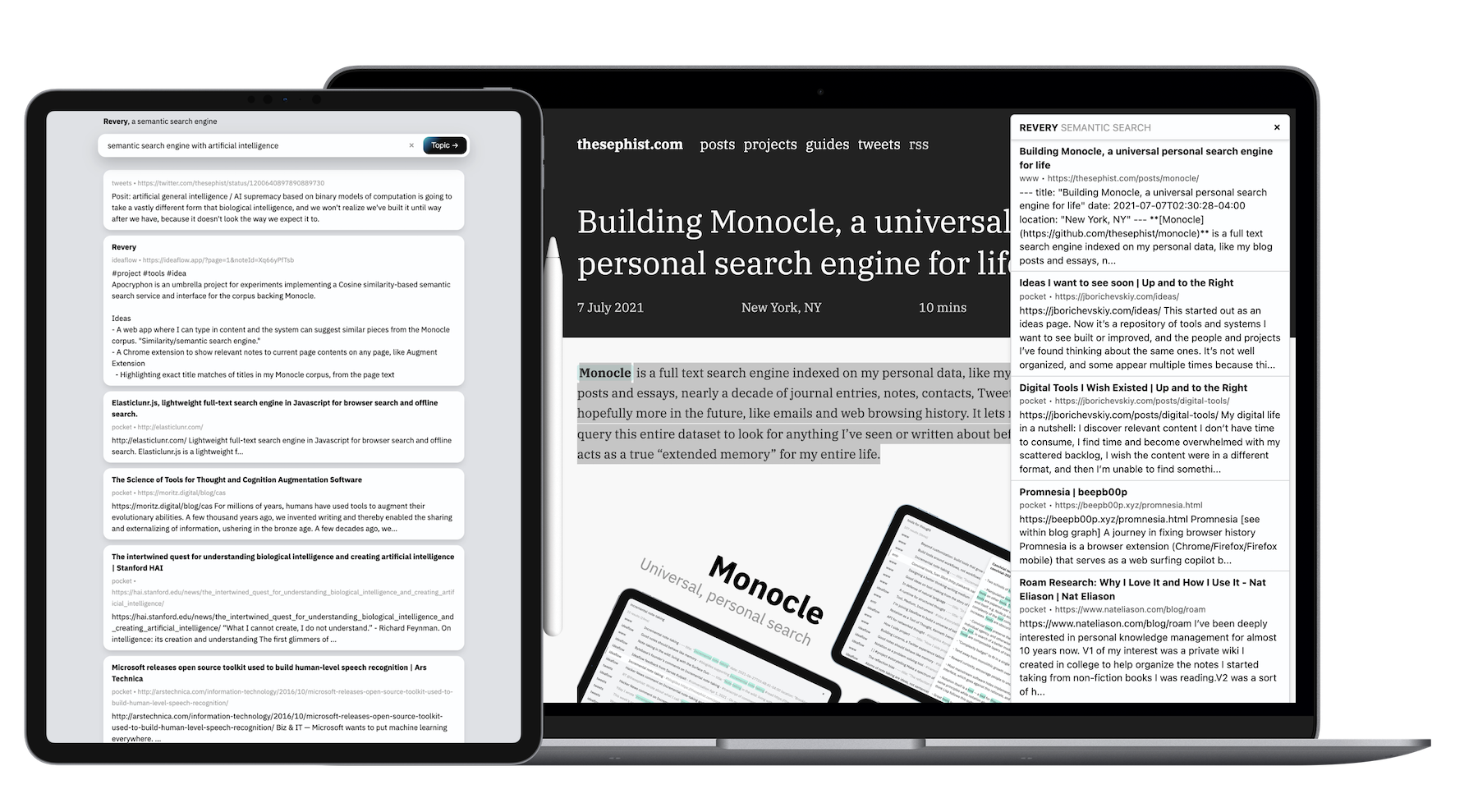
Contrairement à la plupart de mes projets parallèles, en raison de la taille des données et de la quantité de travail de calcul que la retraite exige, son backend est écrit en Go. Les deux clients - l'application Web et l'extension du navigateur - sont construits avec Torus.
Bien que cela fonctionne assez bien pour que je l'utilise tous les jours, Revery est plus un prototype de preuve de concept qu'un produit fini. Je voulais démontrer qu'un outil comme celui-ci pourrait être conçu pour un usage personnel en plus d'outils de productivité personnelle comme les notes et les signets, et découvrir ce que cela ressentirait de parcourir le Web et d'écrire avec un tel outil.
Revery, à la base, n'est qu'une seule API. L'API prend un texte et rampe à travers ma collection de documents personnels et de notes pour trouver les meilleurs qui semblent le plus topiquement liés au texte donné. Pour rendre cela intéressant à utiliser, je l'ai terminé dans deux interfaces différentes: une extension de navigateur et une interface de recherche Web plus standard.
L'extension du navigateur de revery vit à l'intérieur ./extension dans ce référentiel, et fait exactement une chose: lorsque j'appuie Ctrl-Shift-L sur n'importe quelle page Web que je regarde, il grattera le corps principal du texte de la page (ou une partie sélectionnée, si je lis quelque chose) et parlera à l'API de réouverture pour trouver les documents qui sont les plus liés à ce que je lis.

Lorsque Monocle, avec son algorithme de recherche basé sur des mots clés, est bon pour le souvenir, j'ai trouvé l'extension de reveryme idéale pour les explorations sur un sujet spécifique . Si je lis sur le traitement du langage naturel, par exemple, je peux frapper quelques frappes pour élever d'autres articles que j'ai lus, ou des notes que j'ai prises dans le passé, que je peux référencer mentalement en lisant et en découvrant de nouvelles idées dans la PNL.
Nous apprenons le mieux de nouvelles idées lorsque nous pouvons trouver des points de référence existants dans notre mémoire sur lesquels nous pouvons joindre de nouvelles informations. L'extension de Revery automatise et accélère en partie cette tâche. Par exemple, tout en lisant un article sur la position culturelle et économique unique de la Corée du Sud dans le monde, Revery a fait surface quelques newsletters et articles connexes d'auteurs et de sources complètement différents sur la culture pop coréenne et sa baisse de la population, ce qui m'a aidé à encadrer ce que je lisais dans un contexte beaucoup plus large et bien informé.
L'interface de recherche Web, pour moi, est un peu secondaire à l'extension. Il existe principalement comme une démonstration de la technologie sous-jacente de Revery, et également, comme un moyen pour moi d'utiliser la réouverture lorsque l'extension n'est pas disponible (comme sur un navigateur mobile).
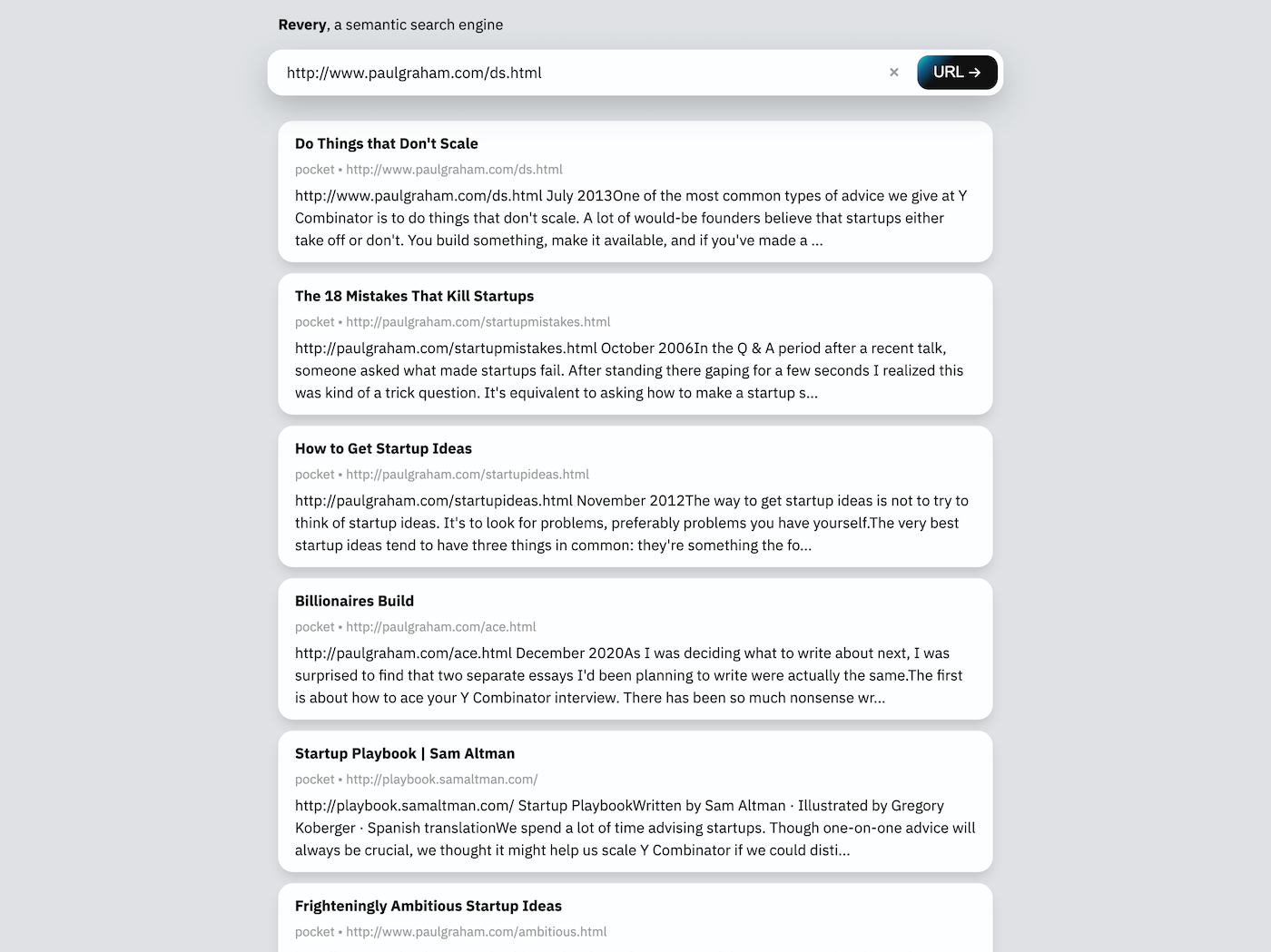
La barre de recherche dans l'interface Web peut prendre une URL ou une phrase clé. Étant donné une URL (comme dans la capture d'écran ci-dessus), Revery téléchargera et lira la page Web elle-même pour trouver des documents connexes dans l'index de recherche. Compte tenu d'une phrase clé, Revery essaiera de suggérer des documents qui contiennent des mots similaires et parlent de sujets similaires.
Ce type d'interface de recherche (par opposition à l'extension) est utile pour commencer à penser à quelque chose de nouveau, où je peux taper une liste de mots connexes dans la zone de recherche et obtenir immédiatement une liste d'idées et de documents que je connais qui sont liés, sans avoir à façonner les requêtes de recherche spécifiques et bien conçues que les moteurs de recherche basés sur des mots clés comme Monocle ont besoin.
Comme mentionné ci-dessus, le noyau de Revery est un seul point de terminaison de l'API qui adopte un document et renvoie une liste de la plupart des documents connexes à partir de mon index de recherche. Ce qui rend Revery Special, c'est que cette API effectue une recherche sémantique , pas simplement une analyse pour les mots clés correspondants. Cela signifie que les résultats supérieurs peuvent même ne pas contenir les mêmes mots que la requête, tant que son contenu est topiquement pertinent.
Ce type de recherche sémantique est activé par un algorithme de recherche qui utilise la similitude du cosinus avec les incorporations de documents de cluster des documents indexés. Si cela vous semble être un tas de mots aléatoires (comme cela m'a fait quand j'ai commencé ce projet), permettez-moi de le décomposer:
Tout d'abord, nous devrons comprendre les intégres de mots . Un mot incorporé est un moyen de cartographier un vocabulaire de mots en langage naturel à certains points de l'espace (généralement un espace mathématique de haute dimension), de sorte que les mots qui sont similaires sont proches les uns des autres dans cet espace. Par exemple, le mot «science» dans un mot incorporation serait très proche du mot «scientifique», raisonnablement proche de la «recherche», et probablement très loin du «cirque». Lorsque nous parlons de «distance» dans le contexte des incorporations de mots, nous utilisons généralement la similitude en cosinus plutôt que sur la distance euclidienne, pour des raisons empiriques et théoriques que je ne couvrirai pas ici.
Bien que le concept d'incorporation de mots ne soit pas très nouveau, il existe toujours des recherches actives produisant de nouvelles méthodes pour générer des intégres de mots de plus en plus précis et utiles dans le même corpus de données. Mon déploiement personnel de Revery utilise l'ensemble de données d'intégration de mots sous licence Creative Commons produit par l'outil FastText de Facebook, en particulier un ensemble de données de 50 000 mots avec 300 dimensions formées sur le corpus Crawl commun.
Les incorporations de mots nous ont tiré des inférences sur les mots liés, mais pour renvoyer, nous voulons dessiner le même type d'inférence sur les documents , qui sont une liste de mots. Heureusement, il y a une grande littérature pour suggérer que simplement prendre une moyenne pondérée de vecteurs de mots pour chaque mot dans un document peut nous permettre une bonne approximation d'un "vecteur de document" qui représente le document dans son ensemble. Bien qu'il existe des méthodes plus avancées que nous pouvons utiliser, comme les vecteurs de paragraphe ou les modèles qui tiennent compte de l'ordre des mots comme Bert, la moyenne des vecteurs de mots fonctionne assez bien pour les cas d'utilisation de Revery et est simple à mettre en œuvre et à tester, donc reveryer les collets avec cette approche.
Une fois que nous pouvons générer des Au démarrage, Revery's API Server index et génère des vecteurs de documents pour tous les documents qu'il peut trouver dans mon ensemble de données (qui n'est pas trop grand - environ 25 000 au moment de la rédaction), et à chaque demande, l'algorithme calcule un vecteur de document pour le document demandé, et trie chaque document dans l'index de recherche par sa distance cosinus vers le document de requête, pour renvoyer des résultats de top n .
En revergant, chaque partie de cet algorithme est écrite à la main dans Go. C'est pour plusieurs raisons:
Les clients de Revery - l'extension et l'application Web - parlent à ce point de terminaison API unique. Les clients eux-mêmes sont assez ordinaires, donc je n'entrerai pas dans les détails décrivant comment ils fonctionnent ici.
Ici, le même avertissement que j'ai partagé avec Monocle s'applique également:
Revery dépend de l'indice de recherche produit par l'indexeur de Monocle, donc je m'assure généralement que Revery ait une copie récente de l'index de recherche de Monocle disponible avant l'exécution.
Revery a deux bases de code indépendantes dans le même référentiel. Le premier est l'extension Chrome, qui vit entièrement à l'intérieur du dossier ./extension . Voici comment je l'ai configuré:
L'extension a besoin d'un jeton d'authentification de l'API pour parler à l'API de revertissement. Je choisis généralement simplement une chaîne aléatoire arbitrairement longue. Ensuite, je place un fichier dans ./extension appelé token.js avec le contenu:
const REVERY_TOKEN = '<some API key here>' ; Je vais à chrome://extensions et clique sur "Chargement Unlebacked" pour charger le dossier ./extension en tant que "extension déballée" dans mon navigateur, ce qui rendra l'extension disponible dans chaque onglet.
C'est tout pour la configuration d'extension. Ensuite, j'ai configuré le serveur:
tokens.txt dans la racine du dossier du projet. Le serveur de reveryme révèlera le contenu garni de Whitespace de ce fichier et l'utilisera comme clé API.make construira l'exécutable binaire revery dans le dossier du projet.docs.json de MonoCle généré par l'indexeur ./corpus/docs.json .revery devrait désormais correctement prétraiter l'index du modèle et de la recherche et démarrer le serveur d'applications Web. Bien que Revery soit suffisamment utile pour que je puisse utiliser quotidiennement, il y a beaucoup de recherches actives dans l'espace de recherche générale de la langue naturelle, et Revery lui-même a beaucoup de place pour les améliorations.
Du côté des données:
Du côté du code:
Il y a aussi beaucoup d'art antérieur dans cet espace. Bien que je ne puisse pas les énumérer ici, il y en a quelques-uns qui se distinguent comme des inspirations pour renommer.


