revery
1.0.0
Revery - это семантическая поисковая система , которая работает в моем индексе монокланического поиска. В то время как Revery позволяет мне искать в одной и той же базе данных из десятков тысяч заметок, закладки, записи в журналах, твитах, контактов и постов в блогах как монокль, сосредоточено не на поиске на основе ключевых слов , который выполняет моноцен Он доступен в качестве расширения браузера, которое может привести к появлению соответствующих результатов на текущей странице, а также более стандартное веб -приложение, напоминающее страницу поиска Monocle.
В отличие от большинства моих побочных проектов из -за размера данных и объема вычислительной работы, требуемой Revery, его бэкэнд написан в Go. Оба клиента - веб -приложение и расширение браузера - построены из Torus.
Хотя это работает достаточно хорошо для меня, чтобы использовать его каждый день, Revery-это скорее прототип подтверждения концепции, чем готовый продукт. Я хотел продемонстрировать, что подобный инструмент может быть создан для личного использования в дополнение к инструментам личной производительности, такими как заметки и закладки, и испытать то, что он будет для просмотра сети и писать с таким инструментом.
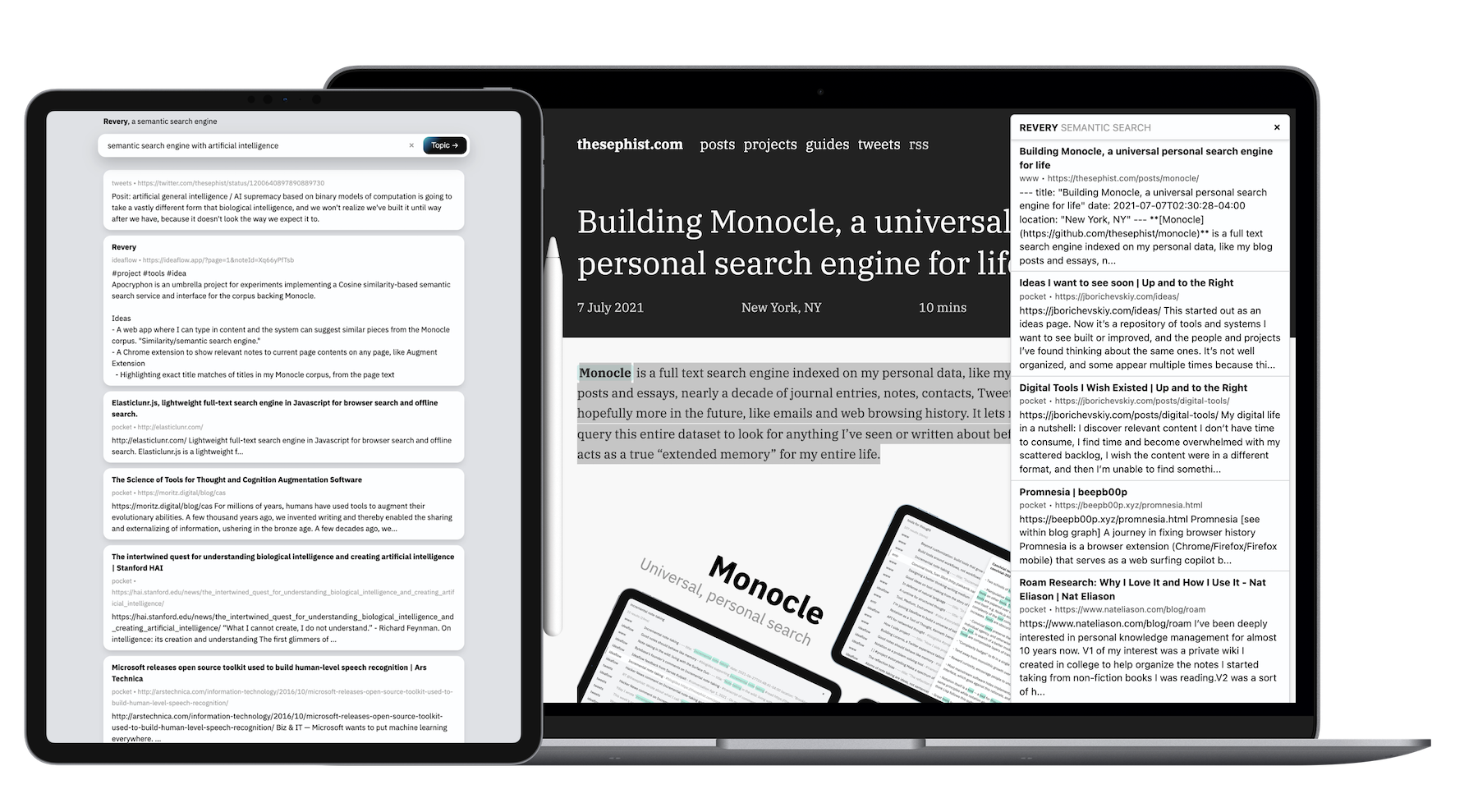
Revery, по своей сути, - это всего лишь один API. API принимает какой -то текст и пробирается через мою коллекцию личных документов и заметок, чтобы найти лучшие, которые кажутся наиболее местными, связанными с данным текстом. Чтобы сделать это интересным в использовании, я завершил его в два разных интерфейса: расширение браузера и более стандартный интерфейс поиска в Интернете.
Расширение браузера Revery Ctrl-Shift-L внутри ./extension

Там, где Monocle, с его алгоритмом поиска на основе ключевых слов, хорошо подходит для воспоминания, я обнаружил, что расширение Revery отлично подходит для исследований по определенной теме . Например, если я читаю о обработке естественного языка, я могу нанести несколько нажатий клавиш, чтобы выпустить другие статьи, которые я читал, или примечания, которые я делал в прошлом, которые я могу мысленно ссылаться на то, что я читаю и узнаю о новых идеях в NLP.
Мы изучаем новые идеи лучше всего, когда мы можем найти существующие эталонные точки в нашей памяти, к которой мы можем прикрепить новую информацию. Расширение Revery частично автоматизирует и ускоряет эту задачу. Например, прочитав статью об уникальном культурном и экономическом положении Южной Кореи в мире, Рейвери появился в нескольких связанных информационных бюллетенях и статьях из совершенно разных авторов и источников в корейской поп-культуре и ее сокращении населения, что помогло мне создать то, что я читал в гораздо более широком, хорошо осведомленном контексте.
Интерфейс веб -поиска для меня немного вторичный по отношению к расширению. Он существует в первую очередь как демонстрация лежащей в основе технологии Revery, а также, кстати, как способ использовать Revery, когда расширение недоступно (например, в мобильном браузере).
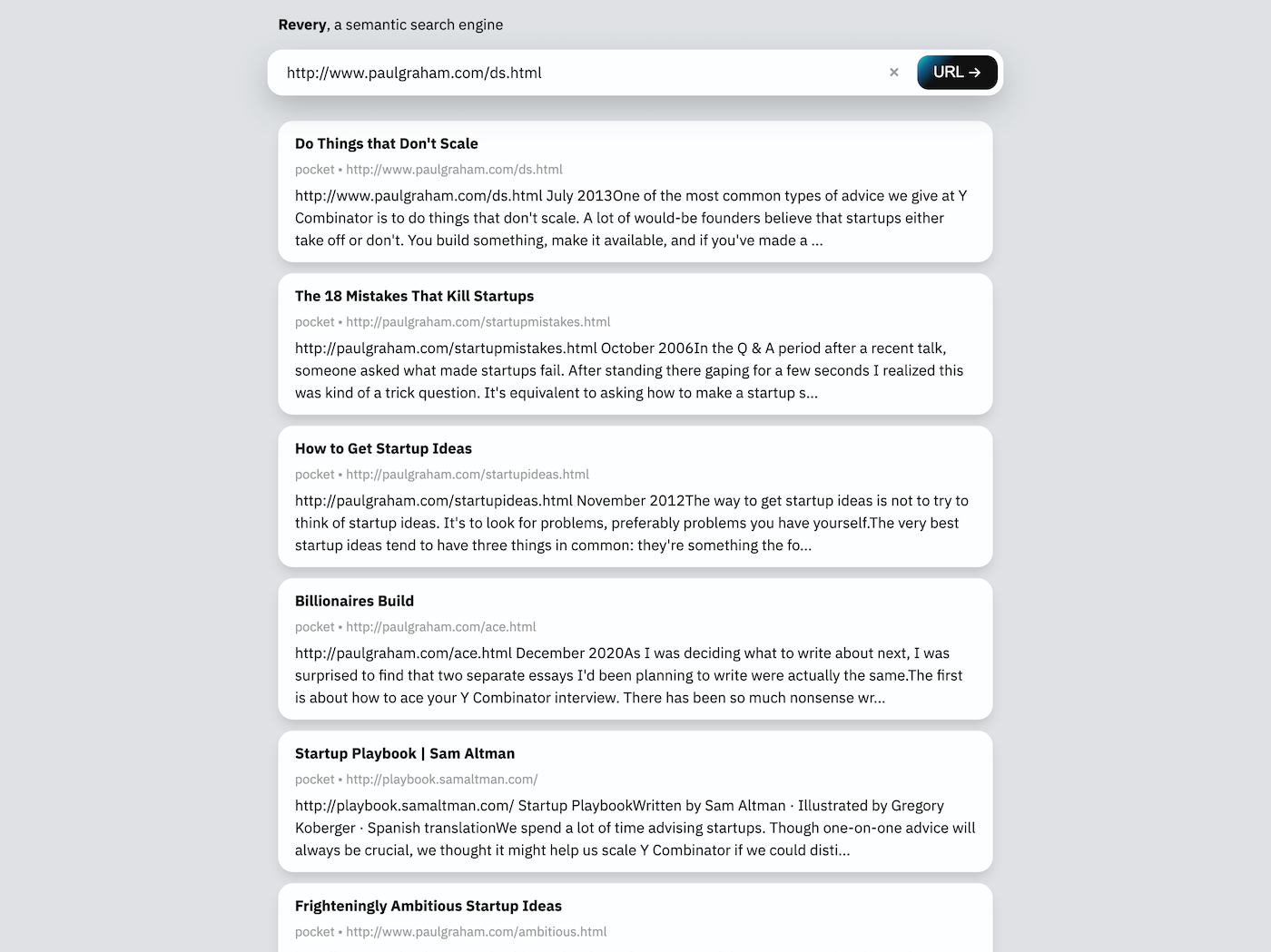
Поисковая строка в веб -интерфейсе может принимать либо URL, либо какую -то ключевую фразу. Учитывая URL (как и на скриншоте выше), Revery загрузит и прочтет саму веб -страницу, чтобы найти связанные документы в индексе поиска. Учитывая ключевую фразу, Revery попытается предложить документы, которые содержат похожие слова и говорят по аналогичным темам.
Этот вид интерфейса поиска (в отличие от расширения) полезен для меня для того, чтобы начать размышлять о чем-то новом, где я могу ввести список связанных слов в поле поиска и немедленно получить список идей и документов, с которыми я знаком, связаны, без необходимости создавать конкретные и хорошо продуманные поисковые запросы, которые требуются на основе ключевых поисковых систем, таких как моноцле.
Как упомянуто выше, ядро Revery - это единственная конечная точка API, которая принимает какой -то документ и возвращает список большинства связанных документов из моего индекса поиска. Что делает Revery особенным, так это то, что этот API выполняет семантический поиск, а не просто сканирование для сопоставления ключевых слов. Это означает, что верхние результаты могут даже не содержать те же слова, что и запрос, если его содержимое актуально.
Этот вид семантического поиска включен алгоритмом поиска, который использует сходство косинуса с кластерными документами встроенных документов индексированных документов. Если это звучит как куча случайных слов (как это было со мной, когда я начал этот проект), позвольте мне сломать его:
Во -первых, нам нужно понять встроенные слова . Слово, встраиваемое,-это способ отображения словарного запаса слов естественного языка в некоторые точки в космосе (обычно высокомерное математическое пространство), так что слова, похожие по значению, близки друг к другу в этом пространстве. Например, слово «наука» в словом, встраиваемое, было бы очень близко к слову «ученый», достаточно близко к «исследованиям» и, вероятно, очень далеко от «цирка». Когда мы говорим о «расстоянии» в контексте встроенных слов, мы обычно используем сходство косинуса, а не евклидово расстояние, как по эмпирическим, так и по теоретическим причинам, которые я здесь не буду покрывать.
Несмотря на то, что концепция встроенных слов не совсем новая, все еще существует активные исследования, создающие новые методы для создания все более точных и полезных встроенных слов из того же корпуса данных. В моем личном развертывании Revery используется набор данных Facebook, лицензируемый в Creative Commons, созданный инструментом Facebook Fastext Tool, в частности, набор данных из 50 000 слов с 300 измерениями, обученными на общем корпусе Crawl Corpus.
Слово внедрения давайте сделаем выводы о том, какие слова связаны, но для Revery мы хотим сделать тот же вид документов , которые являются списком слов. К счастью, есть достаточно литературы, чтобы предположить, что простой взвешенные векторы слов для каждого слова в документе может принести нам хорошее приближение «вектора документов», который представляет документ в целом. Хотя есть более продвинутые методы, которые мы можем использовать, такие как векторы для абзацев или модели, которые принимают во внимание порядок слов, такие как BERT, усреднение векторов слов работает достаточно хорошо для вариантов использования Revery и прост в реализации и тестировании, поэтому Revery придерживается этого подхода.
Как только мы сможем генерировать векторы документов из документов, используя наше слово «встраивание», остальная часть алгоритма становится на свои места. При запуске REVER API -сервера индексирует и генерирует векторы документов для всех документов, которые он может найти в моем наборе данных (который не слишком большой - около 25 000 во время написания), и по каждому запросу алгоритм вычисляет вектор документов для возврата некоторых верховных результатов.
В рамках Revery каждая часть этого алгоритма вручную написана вручную. Это по нескольким причинам:
Оба клиента Revery - расширение и веб -приложение - поговорите с этой единственной конечной точкой API. Сами клиенты довольно обычные, поэтому я не буду вдаваться в подробности, описывая, как они работают здесь.
Здесь тот же отказ, который я поделился с Monocle, также применяется:
Revery зависит от индекса поиска, созданного Indexer Monocle, поэтому я обычно следил за тем, как у Revery есть недавняя копия индекса поиска Monocle, доступной перед запуском.
У Revery есть две независимые кодовые базы в одном и том же хранилище. Первое - это расширение Chrome, которое живет полностью внутри папки ./extension . Вот как я его настроил:
Расширение нужен токен аутентификации API, чтобы поговорить с API Revery. Я обычно просто выбираю произвольно длинную случайную строку. Затем я размещаю файл в ./extension Call token.js с контентом:
const REVERY_TOKEN = '<some API key here>' ; Я перейду к chrome://extensions и нажимаю «Загрузить распаковку», чтобы загрузить папку ./extension как «распакованное расширение» в мой браузер, что предоставит расширение на каждой вкладке.
Вот и все для настройки расширения. Далее я настроил сервер:
tokens.txt в корне папки проекта. Сервер REAVER получит содержимое пробела в этом файле и использует его в качестве ключа API.make построит revery исполняемый файл в папке проекта.docs.json 's Docsle, сгенерированный индексером для ./corpus/docs.json .revery Now должен правильно предварительно обрабатывать модель и индекс поиска и запустить сервер веб-приложений. Несмотря на то, что Revery достаточно полезен для меня повседневной жизни, в общем пространстве поиска естественного языка проводится много активных исследований, и у самого Revery есть много возможностей для улучшений.
На стороне данных:
На стороне кода:
В этом пространстве также есть много отличного предшествующего искусства. Хотя я не могу перечислить их все здесь, есть некоторые, которые выделяются как вдохновения для Revery.


