revery
1.0.0
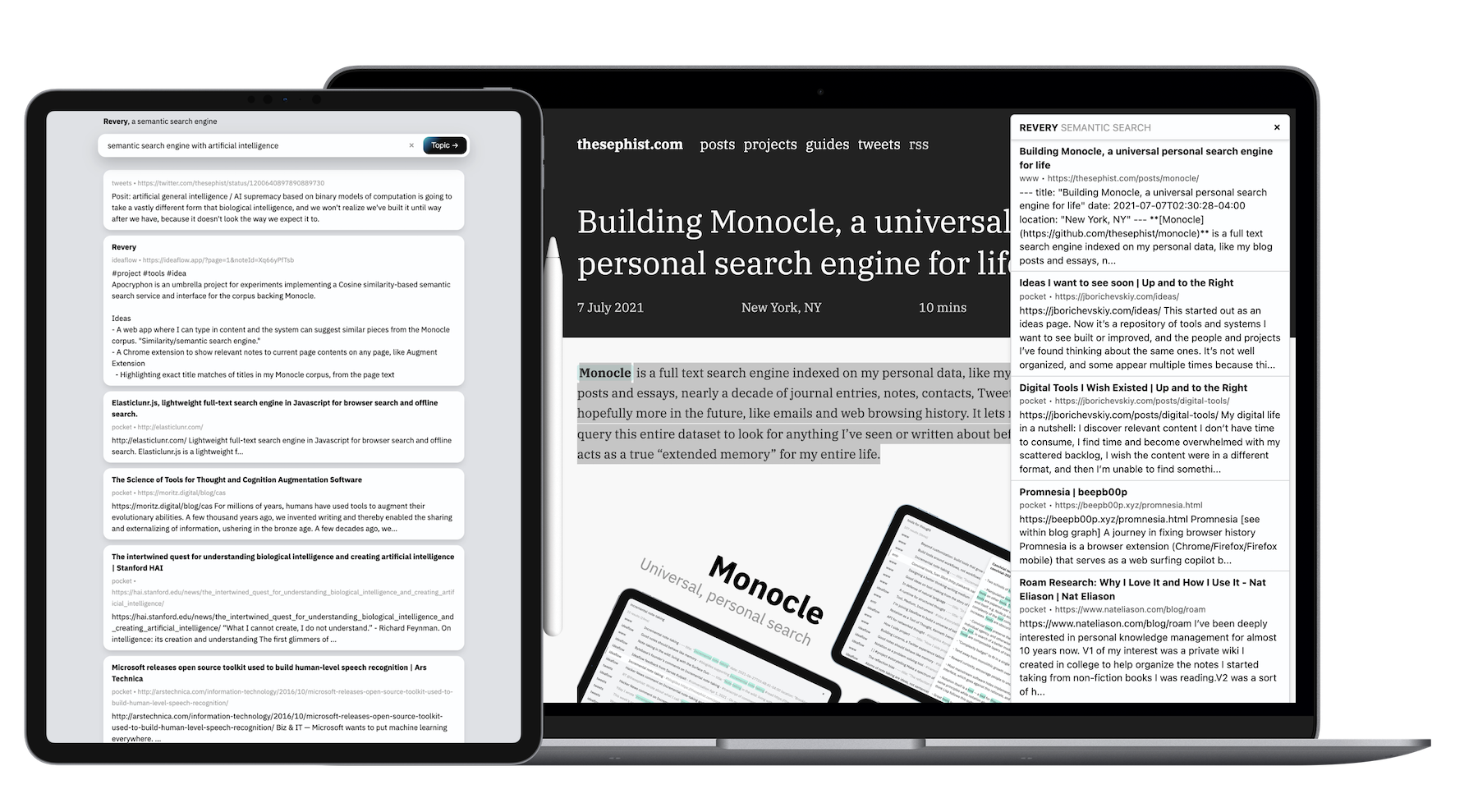
Revery ist eine semantische Suchmaschine , die in meinem Monocle -Suchindex arbeitet. Während Revery es mir über die gleiche Datenbank mit Zehntausenden von Notizen, Lesezeichen, Journaleinträgen, Tweets, Kontakten und Blog-Posts wie Monocle durchsuchen kann, liegt der Fokus von Revery nicht auf Keyword-basierter Suche, die Monocle ausführt, sondern auf semantische Suche nach den semantischen Suche, die topisch ähnlich sind, wie eine bestimmte Webseite oder Abfrage, selbst wenn sie nicht dieselben Worte teilen. Es ist als Browser -Erweiterung erhältlich, die relevante Ergebnisse auf der aktuellen Seite sowie eine mehr Standard -Web -App, die der Suchseite von Monocle ähnelt.
Im Gegensatz zu den meisten meiner Nebenprojekte ist die Größe der Daten und die Menge an Rechenarbeit, die Revery erfordert, sein Backend in Go geschrieben. Beide Kunden - die Web -App und die Browsererweiterung - sind mit Torus erstellt.
Obwohl es für mich gut genug funktioniert, es jeden Tag zu verwenden, ist Revery eher ein Proof-of-Concept-Prototyp als ein fertiges Produkt. Ich wollte nachweisen, dass ein Tool wie dieses für den persönlichen Gebrauch über persönliche Produktivitätstools wie Notizen und Lesezeichen erstellt werden kann und wie es sich anfühlen würde, das Web zu durchsuchen und mit einem solchen Tool zu schreiben.
Revery, im Kern, ist nur eine einzige API. Die API nimmt einen Text auf und kriecht durch meine Sammlung persönlicher Dokumente und Notizen, um die obersten zu finden, die am topisch am angegebenen Text verwandt zu sein scheinen. Um dies interessant zu machen, habe ich es in zwei verschiedenen Schnittstellen einbezogen: eine Browser-Erweiterung und eine Standard-webbasierte Suchschnittstelle.
Die Revery Browser-Erweiterung lebt in diesem ./extension in diesem Repository und macht genau eine Sache: Wenn ich auf jeder Webseite Ctrl-Shift-L anreiche, werden ich den Hauptkörper von Text von der Seite abkratzen (oder einen Teil davon, wenn ich mit der Revery-API, die am meisten mit dem, was mit dem, was ich mit dem verwandten, mit dem, was mit dem verwandt war, etwas, mithilfe, zu finden bin,, mit dem, was ich lese, hervorgehoben habe.

Wenn Monocle mit seinem Keyword-basierten Suchalgorithmus gut für die Erinnerung ist, habe ich die Revery-Erweiterung für Erkundungen zu einem bestimmten Thema gut gefunden. Wenn ich beispielsweise über die Verarbeitung natürlicher Sprache lese, kann ich ein paar Tastenanschläge treffen, um andere Artikel aufzurufen, die ich gelesen habe, oder Notizen, die ich in der Vergangenheit gemacht habe, auf die ich mich mental beziehen kann, wenn ich neue Ideen in NLP lese und über neue Ideen erfahren habe.
Wir lernen neue Ideen am besten, wenn wir vorhandene Referenzpunkte in unserem Gedächtnis finden, an denen wir neue Informationen anhängen können. Die Erweiterung von Revery automatisiert und beschleunigt diese Aufgabe. Als Revery beispielsweise einen Artikel über die einzigartige kulturelle und wirtschaftliche Position Südkoreas in der Welt las, tauchte er einige verwandte Newsletter und Artikel von völlig verschiedenen Autoren und Quellen zur koreanischen Popkultur und ihrem Bevölkerungsrückgang auf, was mir half, das zu rahmen, was ich in einem viel breiteren, gut informierten Kontext las.
Für mich ist die Web -Suchoberfläche ein bisschen sekundär zur Erweiterung. Es existiert in erster Linie als Demonstration der zugrunde liegenden Technologie von Revery und im Übrigen auch als eine Möglichkeit für mich, Revery zu verwenden, wenn die Erweiterung nicht verfügbar ist (wie in einem mobilen Browser).
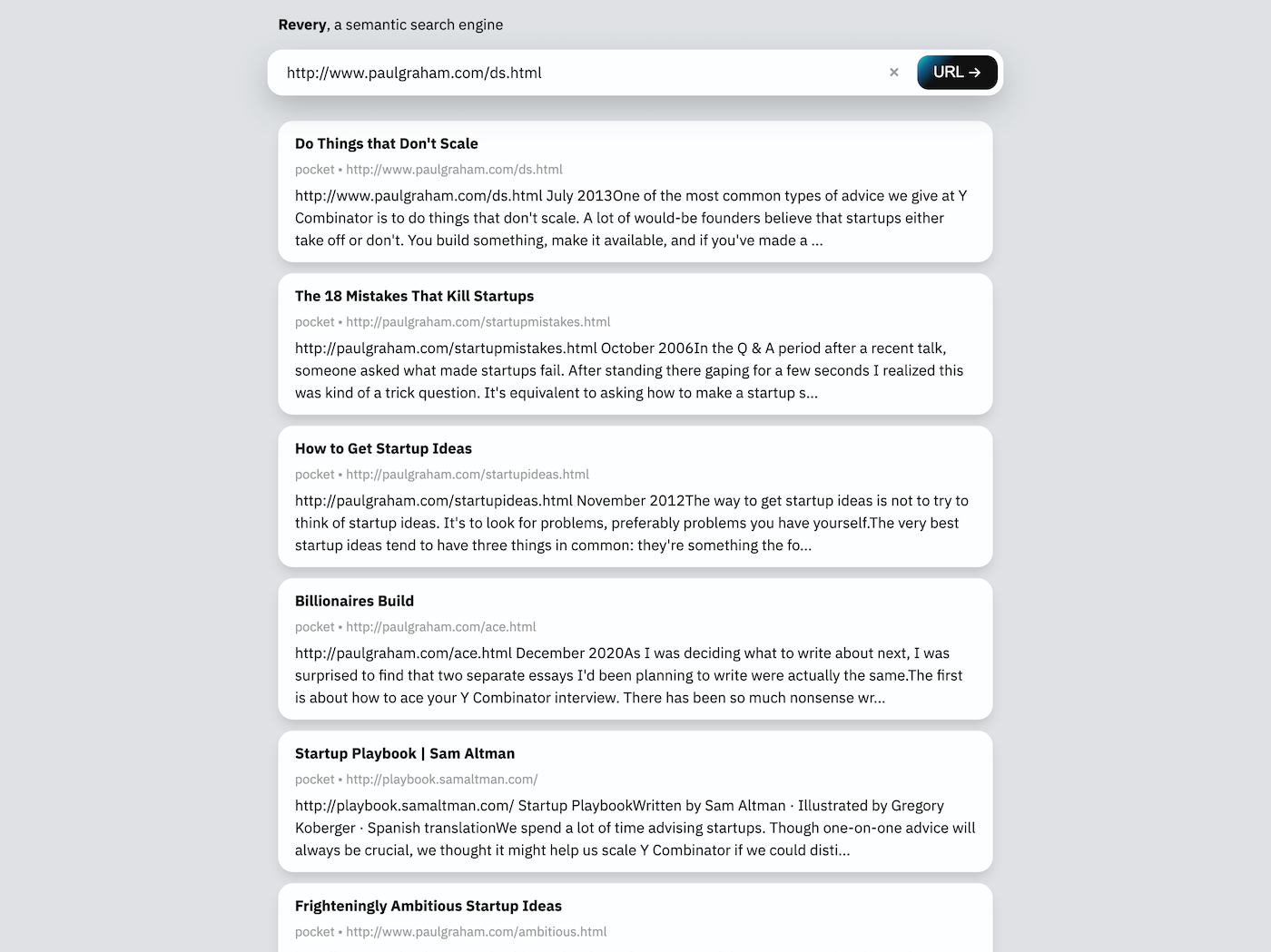
Die Suchleiste in der Webschnittstelle kann entweder eine URL oder einen Schlüsselausdruck einnehmen. Bei einer URL (wie im obigen Screenshot) wird Revery die Webseite selbst heruntergeladen und lesen, um verwandte Dokumente im Suchindex zu finden. Angesichts eines Schlüsselausfalls wird Revery versuchen, Dokumente vorzuschlagen, die ähnliche Wörter enthalten und über ähnliche Themen sprechen.
Diese Art von Suchschnittstelle (im Gegensatz zur Erweiterung) ist für mich nützlich, um über etwas Neues nachzudenken, in dem ich eine Liste verwandter Wörter in das Suchfeld eingeben und sofort eine Liste von Ideen und Dokumenten erhalten kann.
Wie oben erwähnt, ist der Kern von Revery ein einzelner API -Endpunkt, der ein Dokument aufnimmt und eine Liste der meisten verwandten Dokumente aus meinem Suchindex zurückgibt. Was Revery zu Besonderen macht, ist, dass diese API eine semantische Suche durchführt, nicht nur einen Scan zum Abpassen von Schlüsselwörtern. Dies bedeutet, dass die Top -Ergebnisse möglicherweise nicht einmal die gleichen Wörter wie die Abfrage enthalten, solange der Inhalt topisch relevant ist.
Diese Art der semantischen Suche wird durch einen Suchalgorithmus aktiviert, der die Ähnlichkeit der Kosinus mit Cluster -Dokumenteinbettungen der indizierten Dokumente verwendet. Wenn das für Sie wie ein Haufen zufälliger Wörter klingt (wie es mir als ich dieses Projekt begann), lassen Sie mich es aufschlüsseln:
Zunächst müssen wir Worteinbettungen verstehen. Eine Worteinbettung ist eine Möglichkeit, ein Vokabular natürlicher Sprachwörter auf einige Punkte im Raum zuzuordnen (normalerweise ein hochdimensionaler mathematischer Raum), so dass Wörter, die in der Bedeutung ähnlich sind, in diesem Raum nahe beieinander liegen. Zum Beispiel wäre das Wort "Wissenschaft" in einer Worteinbettung dem Wort "Wissenschaftler" sehr nahe an "Forschung" und wahrscheinlich sehr weit entfernt von "Zirkus". Wenn wir im Kontext von Worteinbettungen über "Distanz" sprechen, verwenden wir normalerweise eher die Ähnlichkeit mit Kosinus als die euklidische Distanz, sowohl für empirische als auch für theoretische Gründe, die ich hier nicht behandeln werde.
Obwohl das Konzept der Worteinbettungen nicht sehr neu ist, gibt es immer noch aktive Forschung, die neue Methoden erzeugen, um immer genauere und nützlichere Wortbettendings aus demselben Datenkorpus zu generieren. Meine persönliche Bereitstellung von Revery verwendet das Creative Commons-Licensed Word-Einbettungsdatensatz, das vom FastText-Tool von Facebook erstellt wurde, insbesondere eines 50.000-Wörter-Datensatzes mit 300 Dimensionen, die auf dem gemeinsamen Crawl Corpus trainiert wurden.
Word -Einbettungen lassen uns Schlussfolgerungen darüber ziehen, welche Wörter verwandt sind, aber für Revery möchten wir dieselbe Art von Schlussfolgerung über Dokumente zeichnen, die eine Liste von Wörtern sind. Zum Glück gibt es ausreichend Literatur, die darauf hindeutet, dass das ledigliche Einnehmen eines gewichteten Durchschnitts von Wortvektoren für jedes Wort in einem Dokument eine gute Annäherung an einen "Dokumentvektor" veranlassen kann, der das Dokument als Ganzes darstellt. Obwohl es fortgeschrittenere Methoden gibt, können wir wie Absatzvektoren oder Modelle, die wie Bert berücksichtigt werden, anwenden können. Die Mittelung von Wortvektoren funktioniert gut genug für die Anwendungsfälle von Revery und ist einfach zu implementieren und zu testen.
Sobald wir unter Verwendung unseres Worteinbettung Dokumentvektoren aus Dokumenten generieren können, fällt der Rest des Algorithmus zusammen. Beim Start wird die API -Server von Revery Dokumentvektoren für alle Dokumente in meinem Datensatz (was nicht zu groß ist - zum Zeitpunkt des Schreibens) und in jedem Anfrage berechnet der Algorithmus einen Dokumentvektor für das angeforderte Dokument und sortiert auf jedem Suchindex mit dem Algorithmus im Zusammenhang mit dem Dokument Vektor, um einige Top -N -Ergebnisse zurückzugeben.
Innerhalb des Revery ist jeder Teil dieses Algorithmus in Go handgeschrieben. Dies ist aus ein paar Gründen:
Beide Kunden von Revery - der Erweiterung und der Web -App - sprechen mit diesem einzelnen API -Endpunkt. Die Kunden selbst sind ziemlich gewöhnlich, daher werde ich nicht ins Detail gehen und beschreiben, wie sie hier funktionieren.
Hier gilt der gleiche Haftungsausschluss, den ich mit Monocle geteilt habe, auch:
Revery hängt von dem vom Monocle -Indexer erstellten Suchindex ab. Daher stelle ich normalerweise sicher, dass Revery vor dem Ausführen eine kürzlich verfügbare Kopie des Suchindex von Monocle hat.
Revery hat zwei unabhängige Codebasen im selben Repository. Das erste ist die Chromverlängerung, die vollständig im Ordner ./extension lebt. So habe ich es eingerichtet:
Die Erweiterung benötigt eine API -Authentifizierungs -Token, um mit der Revery -API zu sprechen. Normalerweise wähle ich einfach eine willkürlich lange zufällige Zeichenfolge aus. Dann platziere ich eine Datei ./extension namens token.js mit dem Inhalt:
const REVERY_TOKEN = '<some API key here>' ; Ich gehe zu chrome://extensions und klicke auf "Auspacken", um ./extension Ordner.
Das ist es für das Erweiterungsaufbau. Als nächstes habe ich den Server eingerichtet:
tokens.txt im Stammverschluss des Projektordners. Der Revery-Server greift den WhiteSpace-instrumentierten Inhalt dieser Datei und verwendet sie als API-Schlüssel.make wird die revery Binary ausführbare Datei in den Projektordner aufbauen.docs.json -Dokumentdatensatz, das vom Indexer generiert wurde, um ./corpus/docs.json .revery -Datei sollte den Modell- und Suchindex korrekt vorbereiten und den Webanwendungsserver starten. Obwohl Revery so nützlich genug ist, dass ich täglich nutze, gibt es viele aktive Forschungen im allgemeinen Suchraum der natürlichen Sprache, und Revery selbst hat viel Raum für Verbesserungen.
Auf der Datenseite:
Auf der Codeseite:
In diesem Raum gibt es auch viele großartige frühere Kunst. Obwohl ich sie nicht alle hier auflisten kann, gibt es einige, die sich als Inspirationen für den Rätsel auszeichnen.


