revery
1.0.0
Revery es un motor de búsqueda semántico que funciona en mi índice de búsqueda de monocle. Mientras Revery me permite buscar a través de la misma base de datos de decenas de miles de notas, marcadores, entradas de diario, tweets, contactos y publicaciones de blog como Monocle, el enfoque de Revery no está en la búsqueda basada en palabras clave que Monocle realiza, sino en la búsqueda semántica , encontrando resultados que son tópicamente similares a algunas páginas web dadas, incluso si no comparten las mismas palabras. Está disponible como una extensión del navegador que puede producir resultados relevantes para la página actual, así como una aplicación web más estándar que se asemeja a la página de búsqueda de Monocle.
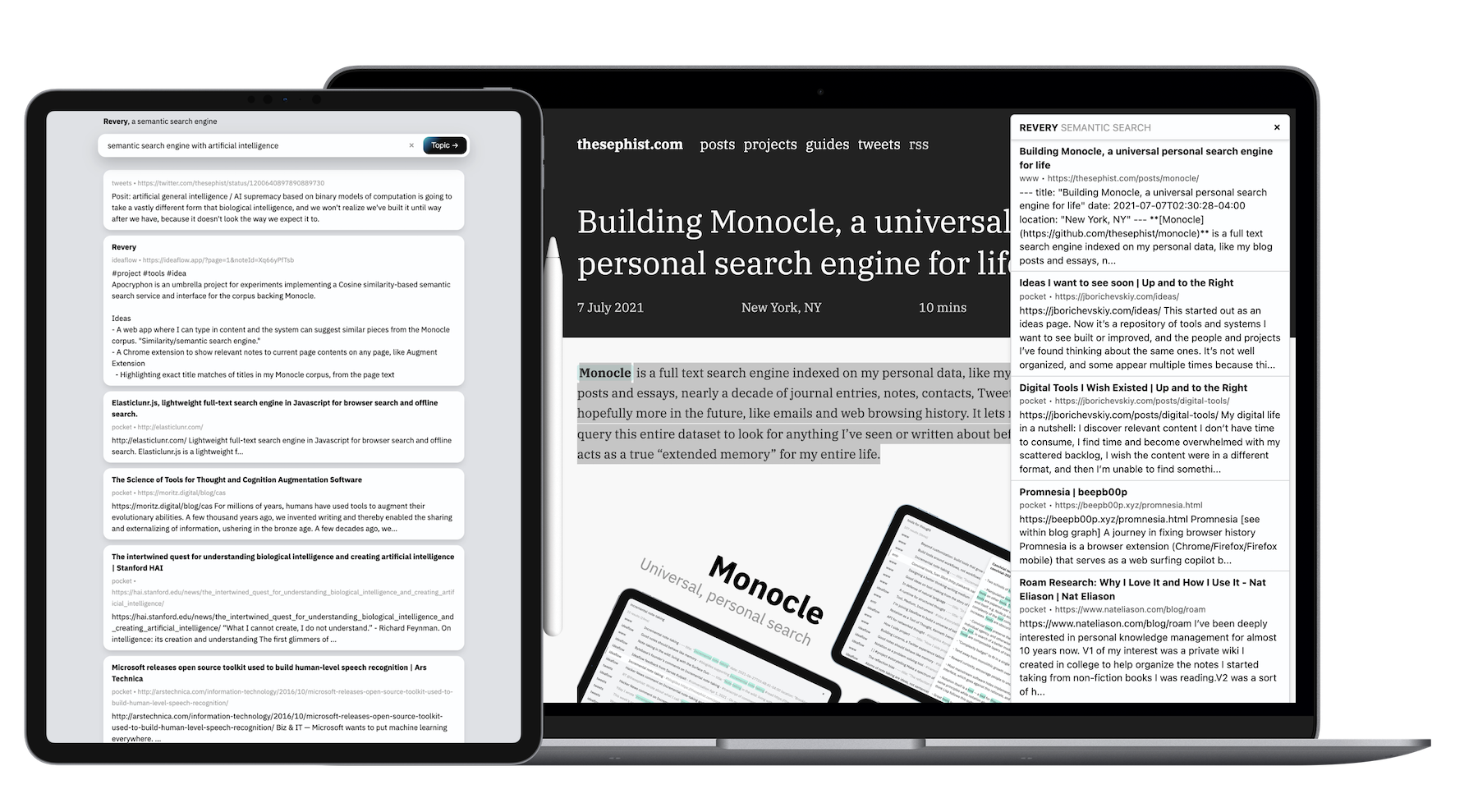
A diferencia de la mayoría de mis proyectos paralelos, debido al tamaño de los datos y la cantidad de trabajo computacional que Revery requiere, su backend está escrito en GO. Ambos clientes, la aplicación web y la extensión del navegador, están construidas con toro.
Aunque funciona lo suficientemente bien para que lo use todos los días, Revery es más un prototipo de prueba de concepto que un producto terminado. Quería demostrar que una herramienta como esta podría construirse para uso personal, además de herramientas de productividad personal, como notas y marcadores, y experimentar cómo se sentiría navegar por la web y escribir con tal herramienta.
Revery, en esencia, es solo una API. La API toma algún texto y se arrastra a través de mi colección de documentos personales y notas para encontrar los principales que parecen más relacionados con el texto dado. Para hacer esto interesante de usar, lo he envuelto en dos interfaces diferentes: una extensión del navegador y una interfaz de búsqueda basada en la web más estándar.
La extensión de Revery Browser vive dentro ./extension En este repositorio, y hace exactamente una cosa: cuando llego a Ctrl-Shift-L en cualquier página web que esté viendo, raspará el cuerpo principal de texto de la página (o alguna parte seleccionada, si he resaltado algo) y hablará con la API de Revery para encontrar los documentos que están más relacionados con lo que estoy leyendo.

Donde Monocle, con su algoritmo de búsqueda basado en palabras clave, es bueno para el recuerdo, he encontrado la extensión de Revery excelente para las exploraciones sobre un tema específico . Si estoy leyendo sobre el procesamiento del lenguaje natural, por ejemplo, puedo presionar algunas pulsaciones de teclas para mencionar otros artículos que he leído, o notas que he tomado en el pasado, que puedo hacer referencia mentalmente mientras leo y aprendo sobre nuevas ideas en PNL.
Aprendemos mejor las nuevas ideas cuando podemos encontrar puntos de referencia existentes en nuestra memoria en los que podemos adjuntar nueva información. La extensión de Revery automatiza y acelera en parte esa tarea. Por ejemplo, mientras leía un artículo sobre la posición cultural y económica única de Corea del Sur en el mundo, Revery apareció algunos boletines y artículos relacionados de autores y fuentes completamente diferentes sobre la cultura pop coreana y su disminución de la población, lo que me ayudó a enmarcar lo que estaba leyendo en un contexto mucho más amplio y bien informado.
La interfaz de búsqueda web, para mí, es un poco secundaria a la extensión. Existe principalmente como una demostración de la tecnología subyacente de Revery, y también por cierto como una forma de usar Revery cuando la extensión no está disponible (como en un navegador móvil).
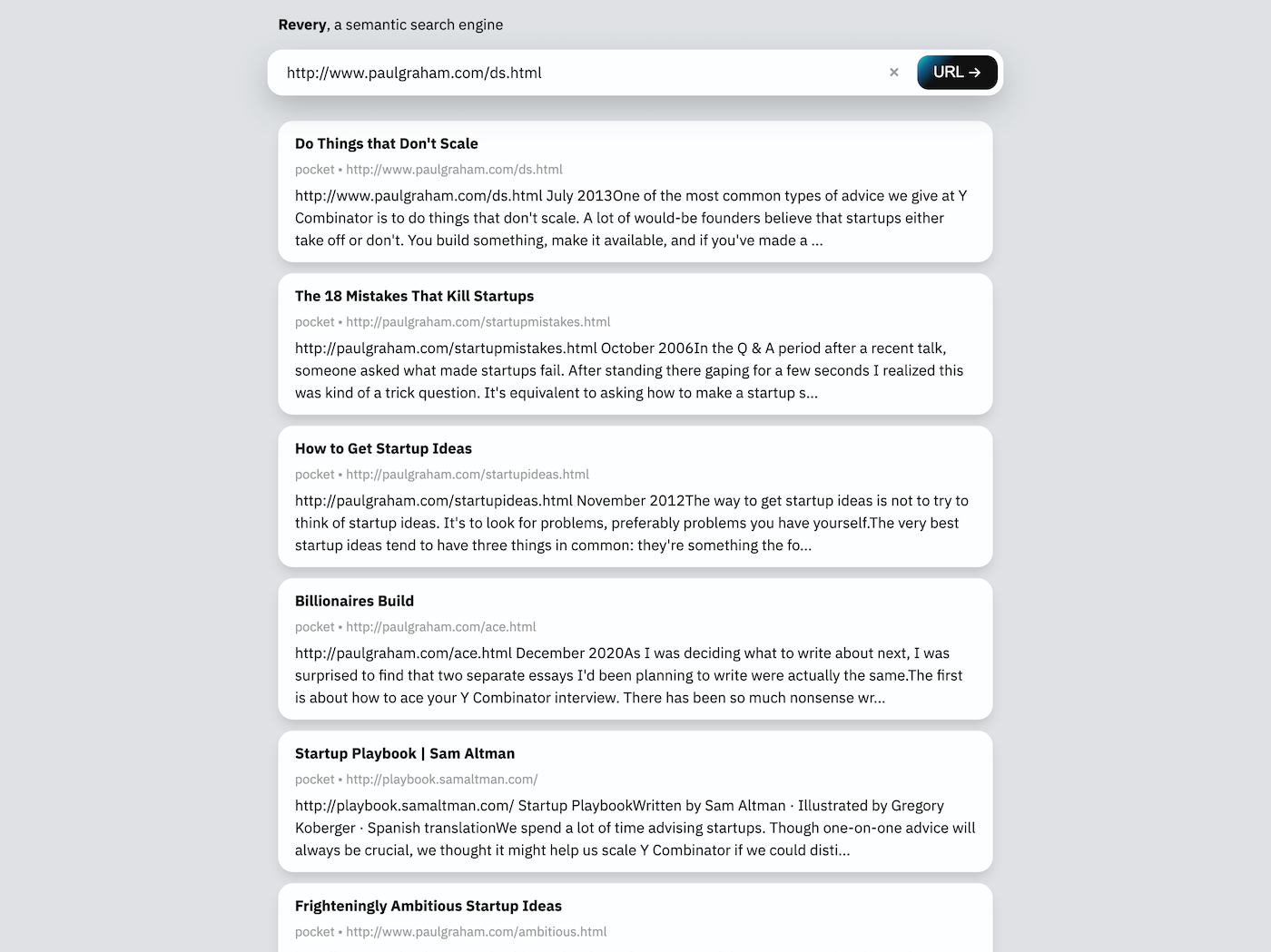
La barra de búsqueda en la interfaz web puede tomar una URL o alguna frase clave. Dada una URL (como en la captura de pantalla anterior), Revery descargará y leerá la página web en sí para encontrar documentos relacionados en el índice de búsqueda. Dada una frase clave, Revery intentará sugerir documentos que contengan palabras similares y hablaran sobre temas similares.
Este tipo de interfaz de búsqueda (a diferencia de la extensión) es útil para mí para comenzar a pensar en algo nuevo, donde puedo escribir una lista de palabras relacionadas en el cuadro de búsqueda e inmediatamente obtener una lista de ideas y documentos con los que estoy familiarizado que están relacionados, sin tener que modificar las consultas de búsqueda específicas y bien elaboradas que los motores de búsqueda basados en palabras clave como Monocle requieren.
Como se mencionó anteriormente, Revery's Core es un único punto final API que toma algún documento y devuelve una lista de los documentos más relacionados de mi índice de búsqueda. Lo que hace que Revery sea especial es que esta API realiza una búsqueda semántica , no simplemente un escaneo para las palabras clave coincidentes. Esto significa que los resultados principales pueden no contener las mismas palabras que la consulta, siempre que su contenido sea tópicamente relevante.
Este tipo de búsqueda semántica está habilitada por un algoritmo de búsqueda que utiliza similitud de coseno con incrustaciones de documentos de clúster de los documentos indexados. Si eso te suena como un montón de palabras aleatorias (como lo hizo cuando comencé este proyecto), déjame desglosarlo:
Primero, tendremos que comprender las incrustaciones de palabras . Una palabra incrustación es una forma de mapear un vocabulario de palabras de lenguaje natural a algunos puntos en el espacio (generalmente un espacio matemático de alta dimensión), de modo que las palabras que son similares en significado están juntas en este espacio. Por ejemplo, la palabra "ciencia" en una palabra incrustación estaría muy cerca de la palabra "científico", razonablemente cerca de "investigación" y probablemente muy lejos del "circo". Cuando hablamos de la "distancia" en el contexto de las incrustaciones de palabras, generalmente usamos similitud coseno en lugar de la distancia euclidiana, por razones empíricas y teóricas que no cubriré aquí.
Aunque el concepto de incrustaciones de palabras no es muy nuevo, todavía existe una investigación activa que produce nuevos métodos para generar incrustaciones de palabras cada vez más precisas y útiles del mismo corpus de datos. Mi despliegue personal de Revery utiliza el conjunto de datos de incrustación de palabras creativas con licencia de los bienes comunes producidos por la herramienta FastText de Facebook, específicamente un conjunto de datos de 50,000 palabras con 300 dimensiones entrenadas en el Corpus de Crawl Common.
Incrustos de palabras dibujemos inferencias sobre qué palabras están relacionadas, pero para Revery, queremos dibujar el mismo tipo de inferencia sobre los documentos , que son una lista de palabras. Afortunadamente, hay una amplia literatura que sugiere que simplemente tomar un promedio ponderado de vectores de palabras para cada palabra en un documento puede obtener una buena aproximación de un "vector de documento" que representa el documento en su conjunto. Aunque hay métodos más avanzados que podemos usar, como los vectores de párrafo o los modelos que tienen en cuenta el orden de las palabras como Bert, promediar los vectores de palabras funciona lo suficientemente bien para los casos de uso de Revery, y es fácil de implementar y probar, por lo que Revery se adhiere a este enfoque.
Una vez que podemos generar vectores de documentos fuera de los documentos utilizando nuestra incrustación de palabras, el resto del algoritmo encaja en su lugar. En el inicio, el servidor API de Revery indexa y genera vectores de documentos para todos los documentos que puede encontrar en mi conjunto de datos (que no es demasiado grande: alrededor de 25,000 al momento de la escritura), y en cada solicitud, el algoritmo calcula un vector de documento para el documento solicitado, y clasifica cada documento en el índice de búsqueda por su distancia de consulta al documento de consulta, para devolver algunos resultados principales de N.
Dentro de Revery, cada parte de este algoritmo está escrita a mano en Go. Esto es por algunas razones:
Ambos clientes de Revery, la extensión y la aplicación web, hablan con este punto final de API único. Los clientes mismos son bastante comunes, por lo que no entraré en detalles que describan cómo funcionan aquí.
Aquí, el mismo descargo de responsabilidad que compartí con Monocle también se aplica:
Revery depende del índice de búsqueda producido por el indexador de Monocle, por lo que generalmente me aseguro de que Revery tenga una copia reciente del índice de búsqueda de Monocle disponible antes de ejecutarse.
Revery tiene dos bases de código independientes en el mismo repositorio. La primera es la extensión de Chrome, que vive completamente dentro de la carpeta ./extension . Así es como lo configuré:
La extensión necesita un token de autenticación API para hablar con la API de Revery. Por lo general, solo elijo una cadena aleatoria arbitrariamente larga. Luego, coloco un archivo ./extension llamado token.js con el contenido:
const REVERY_TOKEN = '<some API key here>' ; Voy a chrome://extensions y hago clic en "Cargar desempaquetado" para cargar la carpeta ./extension como una "extensión desempaquetada" en mi navegador, lo que pondrá a disposición la extensión en cada pestaña.
Eso es todo para la configuración de extensión. A continuación, configuré el servidor:
tokens.txt en la raíz de la carpeta del proyecto. El servidor Revery obtendrá el contenido con el espacio en blanco de este archivo y lo usará como la clave API.make construirá el ejecutable de revery Binary en la carpeta del proyecto.docs.json generado por el indexador a ./corpus/docs.json .revery Ejecutable ahora debe preprocesar correctamente el modelo y el índice de búsqueda, e iniciar el servidor de aplicaciones web. Aunque Revery es lo suficientemente útil para que yo use día a día, hay mucha investigación activa en el espacio general de búsqueda de idiomas naturales, y Revery tiene mucho espacio para mejoras.
En el lado de los datos:
En el lado del código:
También hay mucha arte anterior en este espacio. Aunque no puedo enumerarlos todos aquí, hay algunos que se destacan como inspiraciones para Revery.


