pyClickModels
v0.0.2
Cython實現了ClickModels,該單擊模型使用概率圖形模型在與搜索頁面互動結果(排名)交互時推斷用戶行為。
ClickModels使用概率圖形模型的概念來建模組件,這些組件描述用戶之間的交互作用和按一組檢索規則排名的項目列表。
當需要了解給定文檔是否與給定的搜索查詢不匹配時,這些模型往往很有用,這在文獻中也被稱為判斷成績。通過評估過去觀察到的點擊以及每個查詢的結果頁面上出現文檔出現的位置,這是可能的。
有幾種解決此問題的建議方法。該存儲庫實現了動態的貝葉斯網絡,類似於以前在Python中完成的工作:
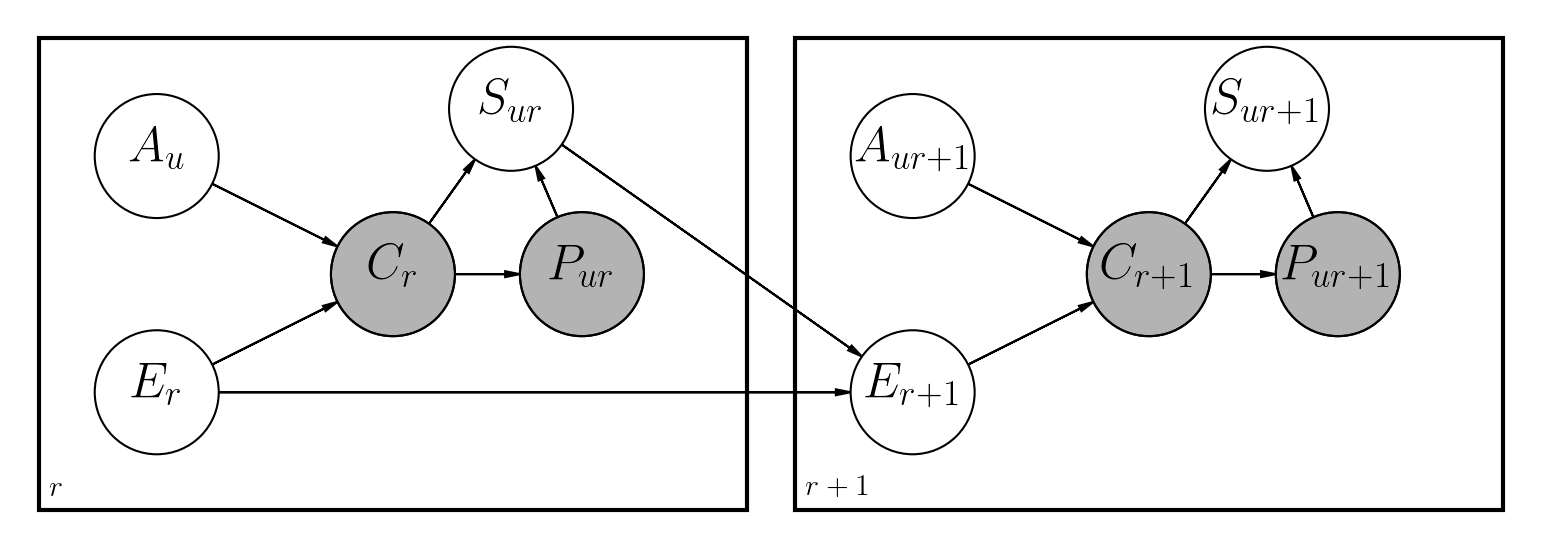
主要區別是:
文件筆記本/dbn.ipynb對模型以及所涉及的所有數學的實現方式有完整的描述。
由於該項目依賴於Cython編制的二進製文件,因此僅支持Linux(Manylinux)平台。它可以安裝:
pip install pyClickModels
PyClickModels期望輸入數據存儲在同一文件夾上的一組壓縮gz文件中。他們都應該從字符串“判斷”開始,例如judgments0.gz每個文件都應包含分離的jsons行。以下是每個JSON系列的示例:
{
"search_keys" : {
"search_term" : " blue shoes " ,
"region" : " south " ,
"favorite_brand" : " super brand " ,
"user_size" : " L " ,
"avg_ticket" : 10
},
"judgment_keys" : [
{
"session" : [
{ "click" : 0 , "purchase" : 0 , "doc" : " doc0 " }
{ "click" : 1 , "purchase" : 0 , "doc" : " doc1 " }
{ "click" : 1 , "purchase" : 1 , "doc" : " doc2 " }
]
},
{
"session" : [
{ "click" : 1 , "purchase" : 0 , "doc" : " doc0 " }
{ "click" : 0 , "purchase" : 0 , "doc" : " doc1 " }
{ "click" : 0 , "purchase" : 0 , "doc" : " doc2 " }
]
}
]
}密鑰search_keys設置了搜索的上下文。在上面的示例中,給定的客戶(或具有相同上下文的客戶群)搜索了blue shoes 。他們的地區是south (可能是任何選擇的價值),最喜歡的品牌是super brand ,依此類推。
這些鍵設置了搜索發生的上下文。當PyClickModels運行優化時,它將一次考慮所有上下文。這意味著獲得的判斷也在整個上下文設置上。
如果不需要上下文,只需使用{"search_keys": {"search_term": "user search"}} 。
這裡沒有必需的模式,這意味著圖書館循環通過search_keys中可用的所有鍵,並考慮整個上下文作為單個查詢的優化過程。
至於judgment_keys ,這是會議列表。關鍵session是強制性的。每個會話都包含用戶的點擊屏幕(如果不需要變量購買,則將其設置為0)。
對於從PyClickModels運行DBN,這是一個簡單的示例:
from pyClickModels . DBN import DBN
model = DBN ()
model . fit ( input_folder = "/tmp/clicks_data/" , iters = 10 )
model . export_judgments ( "/tmp/output.gz" )輸出文件將包含一個Newline JSON分離文件,並對每個查詢的判斷,並且為該查詢觀察到的每個文檔,即:
{ "search_term:blue shoes|region:south|brand:super brand" : { "doc0" : 0.2 , "doc1" : 0.3 , "doc2" : 0.4 }}
{ "search_term:query|region:north|brand:other_brand" : { "doc0" : 0.0 , "doc1" : 0.0 , "doc2" : 0.1 }}這裡的判斷在0到1之間各不相同。一些庫要求在整數0到4之間範圍。在這種情況下,選擇適當的轉換,以更好地適合您的數據。
這個圖書館仍然是alpha!謹慎使用它。它已經完全統一,但它的一部分仍然使用了純C,其例外可能尚未得到充分考慮。建議在生產環境中使用此庫之前,用不同的數據集和大小對其進行全面測試以評估其性能。
貢獻非常歡迎!另外,如果發現錯誤,請報告它們:)。


