pyClickModels
v0.0.2
Cython实现了ClickModels,该单击模型使用概率图形模型在与搜索页面互动结果(排名)交互时推断用户行为。
ClickModels使用概率图形模型的概念来建模组件,这些组件描述用户之间的交互作用和按一组检索规则排名的项目列表。
当需要了解给定文档是否与给定的搜索查询不匹配时,这些模型往往很有用,这在文献中也被称为判断成绩。通过评估过去观察到的点击以及每个查询的结果页面上出现文档出现的位置,这是可能的。
有几种解决此问题的建议方法。该存储库实现了动态的贝叶斯网络,类似于以前在Python中完成的工作:
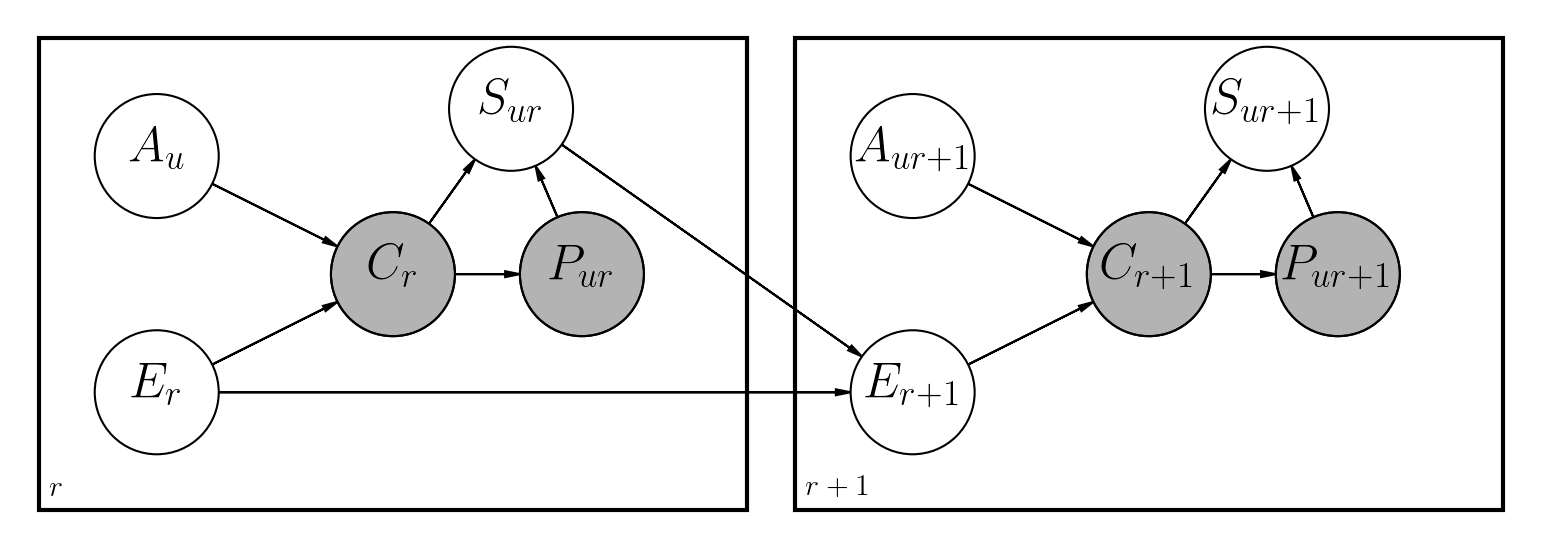
主要区别是:
文件笔记本/dbn.ipynb对模型以及所涉及的所有数学的实现方式有完整的描述。
由于该项目依赖于Cython编制的二进制文件,因此仅支持Linux(Manylinux)平台。它可以安装:
pip install pyClickModels
PyClickModels期望输入数据存储在同一文件夹上的一组压缩gz文件中。他们都应该从字符串“判断”开始,例如judgments0.gz每个文件都应包含分离的jsons行。以下是每个JSON系列的示例:
{
"search_keys" : {
"search_term" : " blue shoes " ,
"region" : " south " ,
"favorite_brand" : " super brand " ,
"user_size" : " L " ,
"avg_ticket" : 10
},
"judgment_keys" : [
{
"session" : [
{ "click" : 0 , "purchase" : 0 , "doc" : " doc0 " }
{ "click" : 1 , "purchase" : 0 , "doc" : " doc1 " }
{ "click" : 1 , "purchase" : 1 , "doc" : " doc2 " }
]
},
{
"session" : [
{ "click" : 1 , "purchase" : 0 , "doc" : " doc0 " }
{ "click" : 0 , "purchase" : 0 , "doc" : " doc1 " }
{ "click" : 0 , "purchase" : 0 , "doc" : " doc2 " }
]
}
]
}密钥search_keys设置了搜索的上下文。在上面的示例中,给定的客户(或具有相同上下文的客户群)搜索了blue shoes 。他们的地区是south (可能是任何选择的价值),最喜欢的品牌是super brand ,依此类推。
这些键设置了搜索发生的上下文。当PyClickModels运行优化时,它将一次考虑所有上下文。这意味着获得的判断也在整个上下文设置上。
如果不需要上下文,只需使用{"search_keys": {"search_term": "user search"}} 。
这里没有必需的模式,这意味着图书馆循环通过search_keys中可用的所有键,并考虑整个上下文作为单个查询的优化过程。
至于judgment_keys ,这是会议列表。关键session是强制性的。每个会话都包含用户的点击屏幕(如果不需要变量购买,则将其设置为0)。
对于从PyClickModels运行DBN,这是一个简单的示例:
from pyClickModels . DBN import DBN
model = DBN ()
model . fit ( input_folder = "/tmp/clicks_data/" , iters = 10 )
model . export_judgments ( "/tmp/output.gz" )输出文件将包含一个Newline JSON分离文件,并对每个查询的判断,并且为该查询观察到的每个文档,即:
{ "search_term:blue shoes|region:south|brand:super brand" : { "doc0" : 0.2 , "doc1" : 0.3 , "doc2" : 0.4 }}
{ "search_term:query|region:north|brand:other_brand" : { "doc0" : 0.0 , "doc1" : 0.0 , "doc2" : 0.1 }}这里的判断在0到1之间各不相同。一些库要求在整数0到4之间范围。在这种情况下,选择适当的转换,以更好地适合您的数据。
这个图书馆仍然是alpha!谨慎使用它。它已经完全统一,但它的一部分仍然使用了纯C,其例外可能尚未得到充分考虑。建议在生产环境中使用此库之前,用不同的数据集和大小对其进行全面测试以评估其性能。
贡献非常欢迎!另外,如果发现错误,请报告它们:)。


