pyClickModels
v0.0.2
Une implémentation cython de Clickmodels qui utilise des modèles graphiques probabilistes pour déduire le comportement de l'utilisateur lors de l'interaction avec les résultats de la page de recherche (classement).
ClickModels utilise le concept de modèles graphiques probabilistes pour modéliser des composants qui décrivent les interactions entre les utilisateurs et une liste d'éléments classés par un ensemble de règles de récupération.
Ces modèles ont tendance à être utiles lorsqu'il est souhaité comprendre si un document donné est une bonne correspondance pour une requête de recherche donnée ou non, qui est également connue dans la littérature sous le nom de jugements . Ceci est possible en évaluant les clics observés passés et les positions auxquelles le document est apparu sur les pages de résultats pour chaque requête.
Il existe plusieurs approches proposées pour gérer ce problème. Ce référentiel implémente un réseau bayésien dynamique, similaire aux travaux précédents également réalisés dans Python:
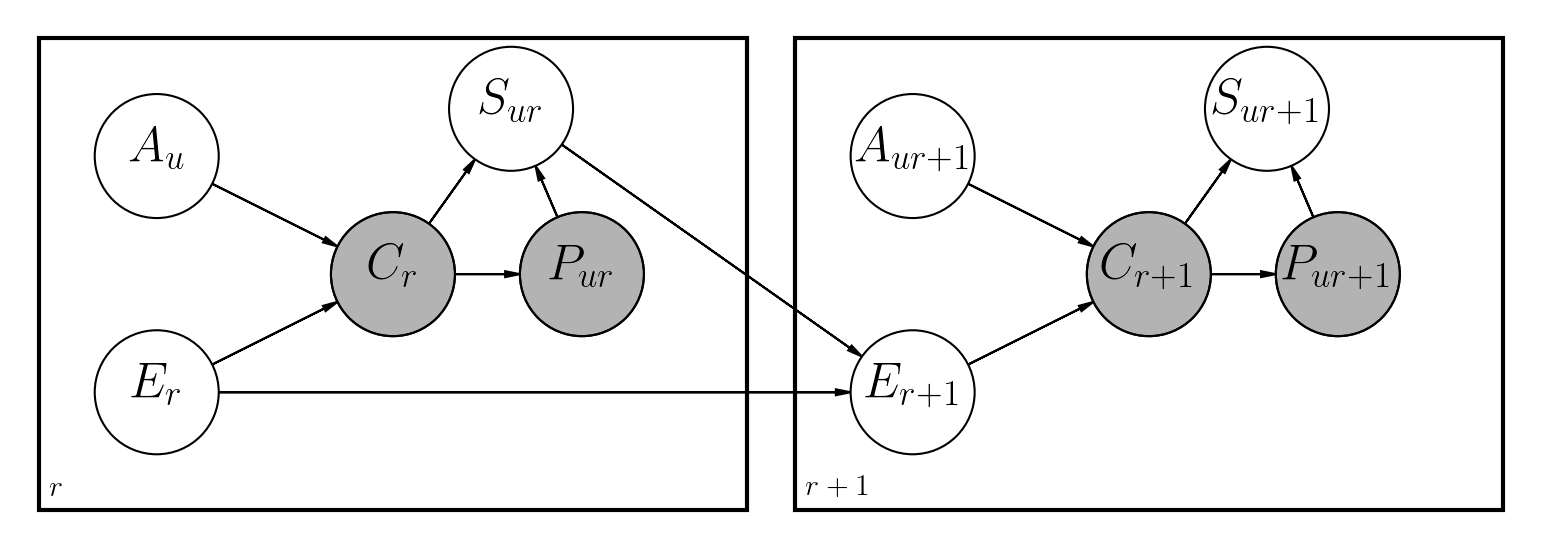
Les principales différences sont:
Les cahiers de fichiers / dbn.ipynb ont une description complète de la façon dont le modèle a été mis en œuvre avec toutes les mathématiques impliquées.
Comme ce projet s'appuie sur des binaires compilés par Cython, la plate-forme Linux (ManyLinux) est actuellement prise en charge. Il peut être installé avec:
pip install pyClickModels
PyclickModels s'attend à ce que les données d'entrée soient stockées dans un ensemble de fichiers gz compressés situés dans le même dossier. Ils devraient tous commencer par les «jugements» de chaîne, par exemple, judgments0.gz . Chaque fichier doit contenir des JSons séparés en ligne. Ce qui suit est un exemple de chaque ligne JSON:
{
"search_keys" : {
"search_term" : " blue shoes " ,
"region" : " south " ,
"favorite_brand" : " super brand " ,
"user_size" : " L " ,
"avg_ticket" : 10
},
"judgment_keys" : [
{
"session" : [
{ "click" : 0 , "purchase" : 0 , "doc" : " doc0 " }
{ "click" : 1 , "purchase" : 0 , "doc" : " doc1 " }
{ "click" : 1 , "purchase" : 1 , "doc" : " doc2 " }
]
},
{
"session" : [
{ "click" : 1 , "purchase" : 0 , "doc" : " doc0 " }
{ "click" : 0 , "purchase" : 0 , "doc" : " doc1 " }
{ "click" : 0 , "purchase" : 0 , "doc" : " doc2 " }
]
}
]
} La clé search_keys définit le contexte de la recherche. Dans l'exemple ci-dessus, un client donné (ou un groupe de clients avec le même contexte) a recherché des blue shoes . Leur région est south (ce pourrait être n'importe quelle valeur choisie), la marque préférée est super brand et ainsi de suite.
Ces clés définissent le contexte pour lequel la recherche s'est produite. Lorsque PyclickModels exécute son optimisation, il considérera tout le contexte à la fois. Cela signifie que les jugements obtenus sont également sur l'ensemble du contexte.
Si aucun contexte n'est souhaité, utilisez simplement {"search_keys": {"search_term": "user search"}} .
Il n'y a pas de schéma requis ici, ce qui signifie que la bibliothèque boucle via toutes les clés disponibles dans search_keys et construit le processus d'optimisation compte tenu de l'ensemble du contexte comme une requête unique.
Quant au judgment_keys , il s'agit d'une liste de sessions. La session clé est obligatoire. Chaque session contient le Clickstream des utilisateurs (si l'achat de variable n'est pas requis, définissez-le à 0).
Pour exécuter DBN à partir de PyclickModels, voici un exemple simple:
from pyClickModels . DBN import DBN
model = DBN ()
model . fit ( input_folder = "/tmp/clicks_data/" , iters = 10 )
model . export_judgments ( "/tmp/output.gz" )Le fichier de sortie contiendra un fichier séparé JSON Newline avec les jugements pour chaque requête et chaque document observé pour cette requête, c'est-à-dire:
{ "search_term:blue shoes|region:south|brand:super brand" : { "doc0" : 0.2 , "doc1" : 0.3 , "doc2" : 0.4 }}
{ "search_term:query|region:north|brand:other_brand" : { "doc0" : 0.0 , "doc1" : 0.0 , "doc2" : 0.1 }}Les jugements ici varient entre 0 et 1. Certaines bibliothèques exigent qu'il varie entre les entiers 0 et 4. Choisissez une transformation appropriée dans ce cas qui convient mieux à vos données.
Cette bibliothèque est toujours alpha! Utilisez-le avec prudence. Il a été entièrement testé mais des parties de celui-ci utilisent Pure C dont les exceptions n'auraient peut-être pas encore été pleinement envisagées. Il est recommandé, avant d'utiliser cette bibliothèque dans les évolutions de production, de la tester pleinement avec différents ensembles de données et tailles pour évaluer son fonctionnement.
Les contributions sont les bienvenues! De plus, si vous trouvez des bugs, veuillez les signaler :).


