pyClickModels
v0.0.2
検索ページの結果と対話するときにユーザーの動作を推測するために確率的グラフィカルモデルを使用するクリックモデルのCython実装(ランキング)。
ClickModelsは、確率的グラフィカルモデルの概念を使用して、ユーザー間の相互作用と、一連の検索ルールでランク付けされたアイテムのリストを記述するコンポーネントをモデル化します。
これらのモデルは、特定のドキュメントが特定の検索クエリに適しているかどうかを理解したい場合に役立つ傾向があります。これは、過去の観察されたクリックと、各クエリの結果ページにドキュメントが表示された位置を評価することで可能です。
この問題を処理するためのいくつかの提案されたアプローチがあります。このリポジトリは、Pythonで行われた以前の作品と同様に、動的なベイジアンネットワークを実装しています。
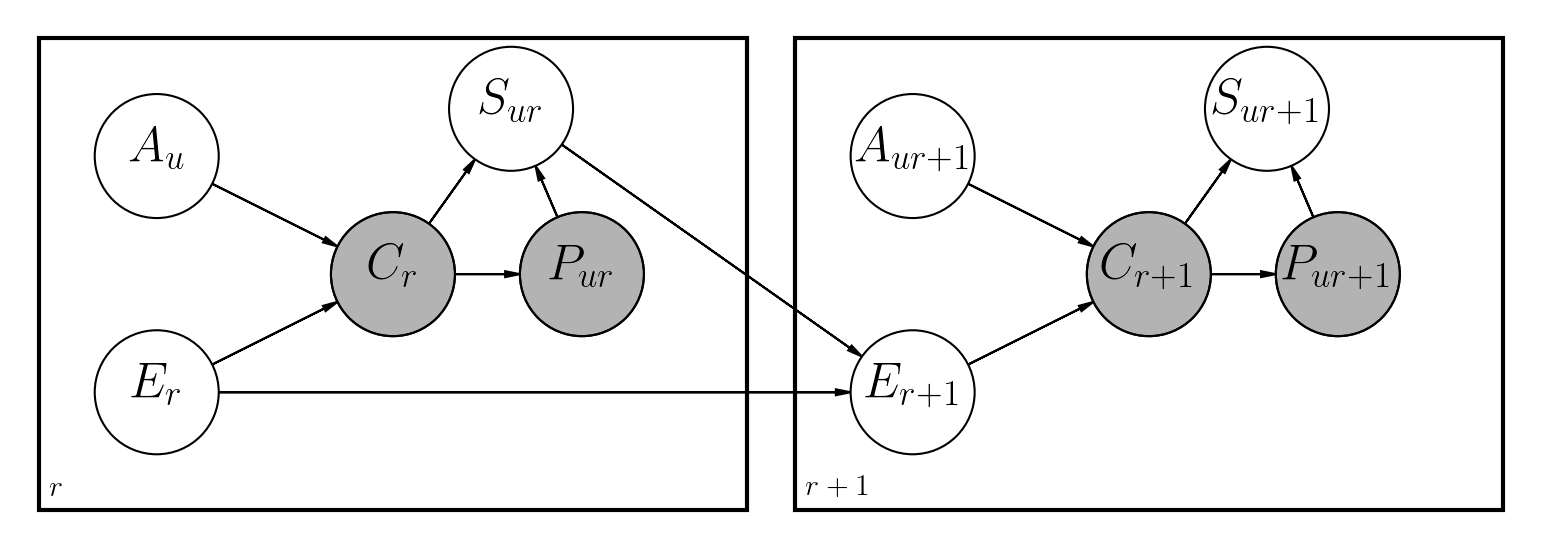
主な違いは次のとおりです。
ファイルノートブック/dbn.ipynbには、関連するすべての数学とともにモデルがどのように実装されているかについての完全な説明があります。
このプロジェクトはCythonによって編集されたバイナリに依存しているため、現在Linux(Manylinux)プラットフォームのみがサポートされています。でインストールできます。
pip install pyClickModels
PyclickModelsは、入力データが同じフォルダーにある圧縮gzファイルのセットに保存されることを期待しています。それらはすべて、文字列「判断」、たとえばjudgments0.gzから始める必要があります。各ファイルには、分離されたJsonsを含む必要があります。以下は、各JSON行の例です。
{
"search_keys" : {
"search_term" : " blue shoes " ,
"region" : " south " ,
"favorite_brand" : " super brand " ,
"user_size" : " L " ,
"avg_ticket" : 10
},
"judgment_keys" : [
{
"session" : [
{ "click" : 0 , "purchase" : 0 , "doc" : " doc0 " }
{ "click" : 1 , "purchase" : 0 , "doc" : " doc1 " }
{ "click" : 1 , "purchase" : 1 , "doc" : " doc2 " }
]
},
{
"session" : [
{ "click" : 1 , "purchase" : 0 , "doc" : " doc0 " }
{ "click" : 0 , "purchase" : 0 , "doc" : " doc1 " }
{ "click" : 0 , "purchase" : 0 , "doc" : " doc2 " }
]
}
]
}キーsearch_keys 、検索のコンテキストを設定します。上記の例では、特定の顧客(または同じコンテキストを持つ顧客のクラスター)がblue shoesを検索しました。彼らの地域はsouthあり(選ばれた価値があります)、お気に入りのブランドはsuper brandなどです。
これらのキーは、検索が起こったコンテキストを設定します。 PyclickModelsが最適化を実行すると、すべてのコンテキストを一度に考慮します。これは、得られた判断もコンテキスト設定全体であることを意味します。
コンテキストが必要ない場合は、 {"search_keys": {"search_term": "user search"}}を使用してください。
ここには、必要なスキーマはありません。これは、ライブラリがsearch_keysで利用可能なすべてのキーをループし、コンテキスト全体を単一のクエリとして考慮した最適化プロセスを構築することを意味します。
judgment_keysに関しては、これはセッションのリストです。キーsessionは必須です。各セッションには、ユーザーのクリックストリームが含まれています(可変購入が不要な場合は、0に設定します)。
PyclickModelsからDBNを実行するために、簡単な例を次に示します。
from pyClickModels . DBN import DBN
model = DBN ()
model . fit ( input_folder = "/tmp/clicks_data/" , iters = 10 )
model . export_judgments ( "/tmp/output.gz" )出力ファイルには、各クエリの判断とそのクエリのために観察された各ドキュメントを備えた新しいラインJSON分離ファイルが含まれます。
{ "search_term:blue shoes|region:south|brand:super brand" : { "doc0" : 0.2 , "doc1" : 0.3 , "doc2" : 0.4 }}
{ "search_term:query|region:north|brand:other_brand" : { "doc0" : 0.0 , "doc1" : 0.0 , "doc2" : 0.1 }}ここでの判断は0〜1の間で異なります。一部のライブラリでは、整数0と4の間の範囲を必要とします。この場合、データに適した適切な変換を選択します。
このライブラリはまだアルファです!注意して使用してください。それは完全には無関心でしたが、それでもその一部は純粋なCを使用していますが、その例外はまだ完全には考慮されていません。このライブラリを生産回避で使用する前に、さまざまなデータセットとサイズで完全にテストして、パフォーマンスを評価することをお勧めします。
貢献は大歓迎です!また、バグが見つかった場合は、それらを報告してください:)。


