pyClickModels
v0.0.2
การใช้งาน cython ของ clickmodels ที่ใช้โมเดลกราฟิกที่น่าจะเป็นเพื่ออนุมานพฤติกรรมของผู้ใช้เมื่อโต้ตอบกับผลลัพธ์หน้าการค้นหา (การจัดอันดับ)
ClickModels ใช้แนวคิดของโมเดลกราฟิกที่น่าจะเป็นในการจำลองส่วนประกอบที่อธิบายการโต้ตอบระหว่างผู้ใช้และรายการของรายการที่จัดอันดับโดยชุดของกฎการดึงข้อมูล
โมเดลเหล่านี้มีแนวโน้มที่จะเป็นประโยชน์เมื่อต้องการที่จะเข้าใจว่าเอกสารที่กำหนดนั้นเป็นคู่ที่ดีสำหรับคำค้นหาที่กำหนดหรือไม่ซึ่งเป็นที่รู้จักกันในวรรณคดีว่าเป็นเกรด การตัดสิน สิ่งนี้เป็นไปได้ผ่านการประเมินการคลิกที่สังเกตในอดีตและตำแหน่งที่เอกสารปรากฏบนหน้าผลลัพธ์สำหรับแต่ละแบบสอบถาม
มีวิธีการที่เสนอหลายวิธีในการจัดการกับปัญหานี้ ที่เก็บนี้ใช้เครือข่ายแบบเบย์แบบไดนามิกคล้ายกับงานก่อนหน้านี้ที่ทำใน Python:
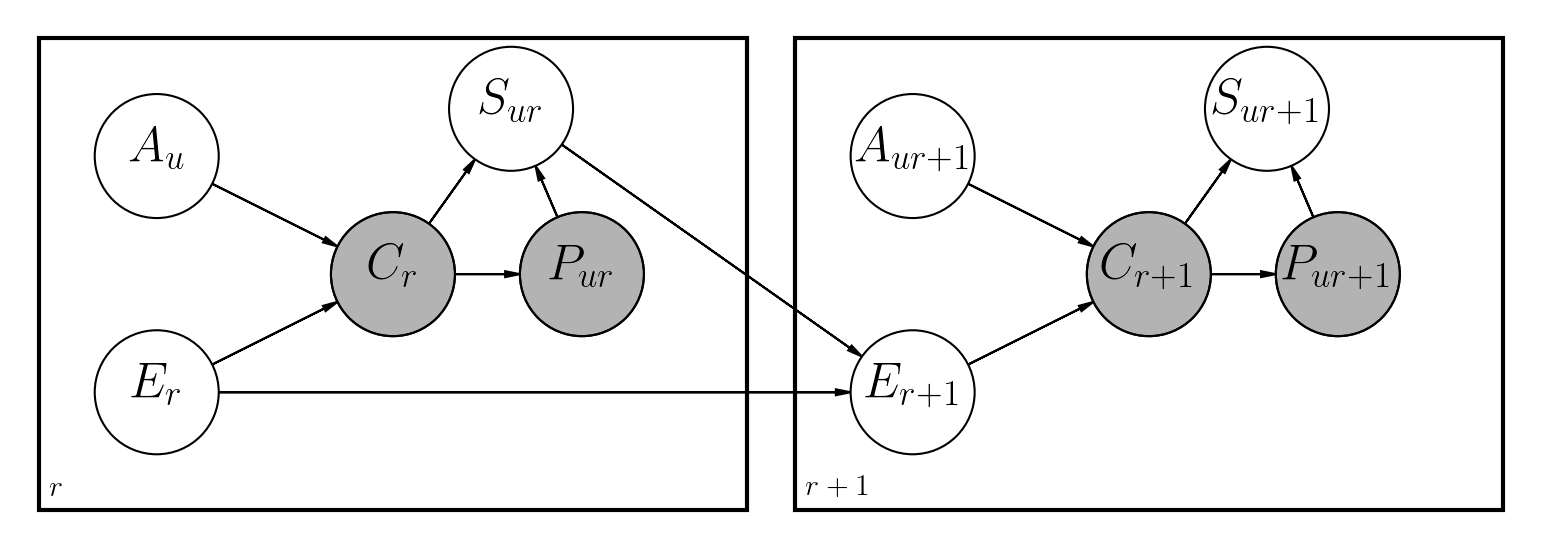
ความแตกต่างหลักคือ:
โน้ตบุ๊กไฟล์/dbn.ipynb มีคำอธิบายที่สมบูรณ์เกี่ยวกับวิธีการใช้งานแบบจำลองพร้อมกับคณิตศาสตร์ทั้งหมดที่เกี่ยวข้อง
เนื่องจากโครงการนี้อาศัยไบนารีที่รวบรวมโดย Cython ปัจจุบันรองรับแพลตฟอร์ม Linux (ManyLinux) เท่านั้น สามารถติดตั้งได้ด้วย:
pip install pyClickModels
PyclickModels คาดว่าข้อมูลอินพุตจะถูกเก็บไว้ในชุดไฟล์ gz ที่บีบอัดที่อยู่ในโฟลเดอร์เดียวกัน พวกเขาทั้งหมดควรเริ่มต้นด้วยสตริง "การตัดสิน" เช่น judgments0.gz แต่ละไฟล์ควรมี JSONs ที่คั่นด้วยบรรทัด ต่อไปนี้เป็นตัวอย่างของแต่ละบรรทัด JSON:
{
"search_keys" : {
"search_term" : " blue shoes " ,
"region" : " south " ,
"favorite_brand" : " super brand " ,
"user_size" : " L " ,
"avg_ticket" : 10
},
"judgment_keys" : [
{
"session" : [
{ "click" : 0 , "purchase" : 0 , "doc" : " doc0 " }
{ "click" : 1 , "purchase" : 0 , "doc" : " doc1 " }
{ "click" : 1 , "purchase" : 1 , "doc" : " doc2 " }
]
},
{
"session" : [
{ "click" : 1 , "purchase" : 0 , "doc" : " doc0 " }
{ "click" : 0 , "purchase" : 0 , "doc" : " doc1 " }
{ "click" : 0 , "purchase" : 0 , "doc" : " doc2 " }
]
}
]
} คีย์ search_keys ตั้งค่าบริบทสำหรับการค้นหา ในตัวอย่างข้างต้นลูกค้าที่กำหนด (หรือกลุ่มลูกค้าที่มีบริบทเดียวกัน) ค้นหา blue shoes ภูมิภาคของพวกเขาอยู่ south (อาจเป็นคุณค่าใด ๆ ที่เลือก) แบรนด์โปรดคือ super brand และอื่น ๆ
คีย์เหล่านี้ตั้งค่าบริบทที่การค้นหาเกิดขึ้น เมื่อ PyclickModels ดำเนินการเพิ่มประสิทธิภาพมันจะพิจารณาบริบททั้งหมดในครั้งเดียว ซึ่งหมายความว่าการตัดสินที่ได้รับนั้นอยู่ในการตั้งค่าบริบททั้งหมด
หากไม่ต้องการบริบทเพียงใช้ {"search_keys": {"search_term": "user search"}}
ไม่มีสคีมาที่จำเป็นที่นี่ซึ่งหมายถึงห้องสมุดวนลูปผ่านคีย์ทั้งหมดที่มีอยู่ใน search_keys และสร้างกระบวนการปรับให้เหมาะสมโดยพิจารณาบริบททั้งหมดเป็นแบบสอบถามเดียว
สำหรับ judgment_keys นี่คือรายการของเซสชัน session ที่สำคัญนั้นจำเป็น แต่ละเซสชันมี clickstream ของผู้ใช้ (หากไม่จำเป็นต้องตั้งค่าตัวแปรให้ตั้งค่าเป็น 0)
สำหรับการรัน DBN จาก PyclickModels นี่เป็นตัวอย่างง่ายๆ:
from pyClickModels . DBN import DBN
model = DBN ()
model . fit ( input_folder = "/tmp/clicks_data/" , iters = 10 )
model . export_judgments ( "/tmp/output.gz" )ไฟล์เอาท์พุทจะมีไฟล์คั่นใหม่ JSON ใหม่พร้อมการตัดสินสำหรับแต่ละคำถามและเอกสารแต่ละฉบับที่สังเกตสำหรับแบบสอบถามนั้นเช่น:
{ "search_term:blue shoes|region:south|brand:super brand" : { "doc0" : 0.2 , "doc1" : 0.3 , "doc2" : 0.4 }}
{ "search_term:query|region:north|brand:other_brand" : { "doc0" : 0.0 , "doc1" : 0.0 , "doc2" : 0.1 }}การตัดสินที่นี่แตกต่างกันระหว่าง 0 ถึง 1 ห้องสมุดบางแห่งต้องการให้อยู่ในช่วงระหว่างจำนวนเต็ม 0 และ 4 เลือกการแปลงที่เหมาะสมในกรณีนี้ที่เหมาะกับข้อมูลของคุณดีกว่า
ห้องสมุดนี้ยังคงเป็นอัลฟ่า! ใช้ด้วยความระมัดระวัง มันยังไม่ได้รับการทดสอบอย่างสมบูรณ์ แต่ยังคงใช้ส่วนหนึ่งของ C ใช้ C บริสุทธิ์ซึ่งอาจมีข้อยกเว้นอาจยังไม่ได้รับการพิจารณาอย่างเต็มที่ ขอแนะนำให้ก่อนที่จะใช้ไลบรารีนี้ในการผลิต Evironments เพื่อทดสอบอย่างเต็มที่ด้วยชุดข้อมูลและขนาดที่แตกต่างกันเพื่อประเมินว่ามันทำงานอย่างไร
การบริจาคยินดีต้อนรับมาก! นอกจากนี้หากคุณพบข้อบกพร่องโปรดรายงานพวกเขา :)


