pyClickModels
v0.0.2
Implementasi Cython dari CLICKModels yang menggunakan model grafis probabilistik untuk menyimpulkan perilaku pengguna saat berinteraksi dengan hasil halaman pencarian (peringkat).
ClickModels menggunakan konsep model grafis probabilistik untuk memodelkan komponen yang menggambarkan interaksi antara pengguna dan daftar item yang diperingkat oleh serangkaian aturan pengambilan.
Model -model ini cenderung berguna ketika diinginkan untuk memahami apakah dokumen yang diberikan cocok untuk pertanyaan pencarian yang diberikan atau tidak yang juga dikenal dalam literatur sebagai nilai penilaian . Ini dimungkinkan melalui mengevaluasi klik yang diamati di masa lalu dan posisi di mana dokumen muncul di halaman hasil untuk setiap kueri.
Ada beberapa pendekatan yang diusulkan untuk menangani masalah ini. Repositori ini mengimplementasikan jaringan Bayesian yang dinamis, mirip dengan karya -karya sebelumnya yang juga dilakukan di Python:
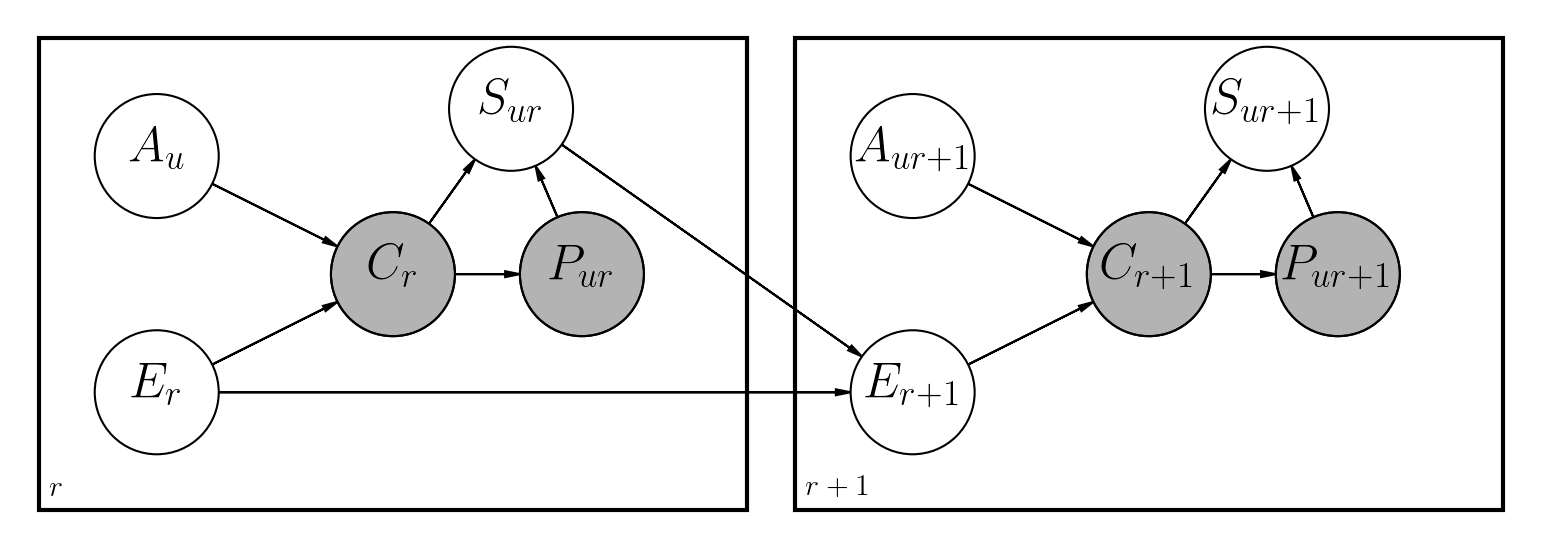
Perbedaan utama adalah:
File notebooks/dbn.ipynb memiliki deskripsi lengkap tentang bagaimana model telah diimplementasikan bersama dengan semua matematika yang terlibat.
Karena proyek ini bergantung pada binari yang dikompilasi oleh Cython, saat ini hanya platform Linux (Manylinux) yang didukung. Itu dapat diinstal dengan:
pip install pyClickModels
PyClickModels mengharapkan data input disimpan dalam satu set file gz terkompresi yang terletak di folder yang sama. Mereka semua harus mulai dengan "penilaian" string, misalnya, judgments0.gz . Setiap file harus berisi jsons terpisah baris. Berikut ini adalah contoh dari setiap baris JSON:
{
"search_keys" : {
"search_term" : " blue shoes " ,
"region" : " south " ,
"favorite_brand" : " super brand " ,
"user_size" : " L " ,
"avg_ticket" : 10
},
"judgment_keys" : [
{
"session" : [
{ "click" : 0 , "purchase" : 0 , "doc" : " doc0 " }
{ "click" : 1 , "purchase" : 0 , "doc" : " doc1 " }
{ "click" : 1 , "purchase" : 1 , "doc" : " doc2 " }
]
},
{
"session" : [
{ "click" : 1 , "purchase" : 0 , "doc" : " doc0 " }
{ "click" : 0 , "purchase" : 0 , "doc" : " doc1 " }
{ "click" : 0 , "purchase" : 0 , "doc" : " doc2 " }
]
}
]
} Kunci search_keys menetapkan konteks untuk pencarian. Dalam contoh di atas, pelanggan yang diberikan (atau kelompok pelanggan dengan konteks yang sama) mencari blue shoes . Wilayah mereka adalah south (bisa jadi nilai yang dipilih), merek favorit adalah super brand dan sebagainya.
Kunci -kunci ini menetapkan konteks yang pencariannya terjadi. Ketika pyclickmodels menjalankan optimalisasi, ia akan mempertimbangkan semua konteks sekaligus. Ini berarti bahwa penilaian yang diperoleh juga pada seluruh pengaturan konteks.
Jika tidak ada konteks yang diinginkan, cukup gunakan {"search_keys": {"search_term": "user search"}} .
Tidak ada skema yang diperlukan di sini yang berarti loop perpustakaan melalui semua tombol yang tersedia di search_keys dan membangun proses optimasi mengingat seluruh konteks sebagai satu kueri.
Adapun judgment_keys , ini adalah daftar sesi. session utama adalah wajib. Setiap sesi berisi clickstream pengguna (jika pembelian variabel tidak diperlukan set ke 0).
Untuk menjalankan DBN dari pyclickmodels, inilah contoh sederhana:
from pyClickModels . DBN import DBN
model = DBN ()
model . fit ( input_folder = "/tmp/clicks_data/" , iters = 10 )
model . export_judgments ( "/tmp/output.gz" )File output akan berisi file terpisah JSON baru dengan penilaian untuk setiap kueri dan setiap dokumen yang diamati untuk kueri itu, yaitu:
{ "search_term:blue shoes|region:south|brand:super brand" : { "doc0" : 0.2 , "doc1" : 0.3 , "doc2" : 0.4 }}
{ "search_term:query|region:north|brand:other_brand" : { "doc0" : 0.0 , "doc1" : 0.0 , "doc2" : 0.1 }}Penilaian di sini bervariasi antara 0 dan 1. Beberapa perpustakaan mengharuskannya berkisar antara bilangan bulat 0 dan 4. Pilih transformasi yang tepat dalam hal ini yang lebih sesuai dengan data Anda.
Perpustakaan ini masih alfa! Gunakan dengan hati -hati. Sudah benar -benar tidak dicantumkan tetapi masih sebagian dari itu menggunakan C murni yang pengecualiannya mungkin belum sepenuhnya dipertimbangkan. Disarankan untuk, sebelum menggunakan perpustakaan ini dalam pembangkit produksi, untuk sepenuhnya mengujinya dengan set data dan ukuran yang berbeda untuk mengevaluasi kinerja.
Kontribusi sangat disambut! Juga, jika Anda menemukan bug, silakan laporkan :).


