pyClickModels
v0.0.2
Реализация цинтона ClickModels, которая использует вероятностные графические модели для вывода поведения пользователей при взаимодействии с результатами страницы поиска (рейтинг).
ClickModels использует концепцию вероятностных графических моделей для моделирования компонентов, которые описывают взаимодействия между пользователями и список элементов, ранжированных по набору правил поиска.
Эти модели, как правило, полезны, когда желательно понять, является ли данное документ хорошим совпадением для данного поискового запроса или нет, который также известен в литературе как оценки суждений . Это возможно путем оценки прошлых наблюдаемых кликов и позиций, в которых документ появился на страницах результатов для каждого запроса.
Есть несколько предложенных подходов для решения этой проблемы. Этот репозиторий реализует динамическую байесовскую сеть, аналогичную предыдущим работам, также выполненным в Python:
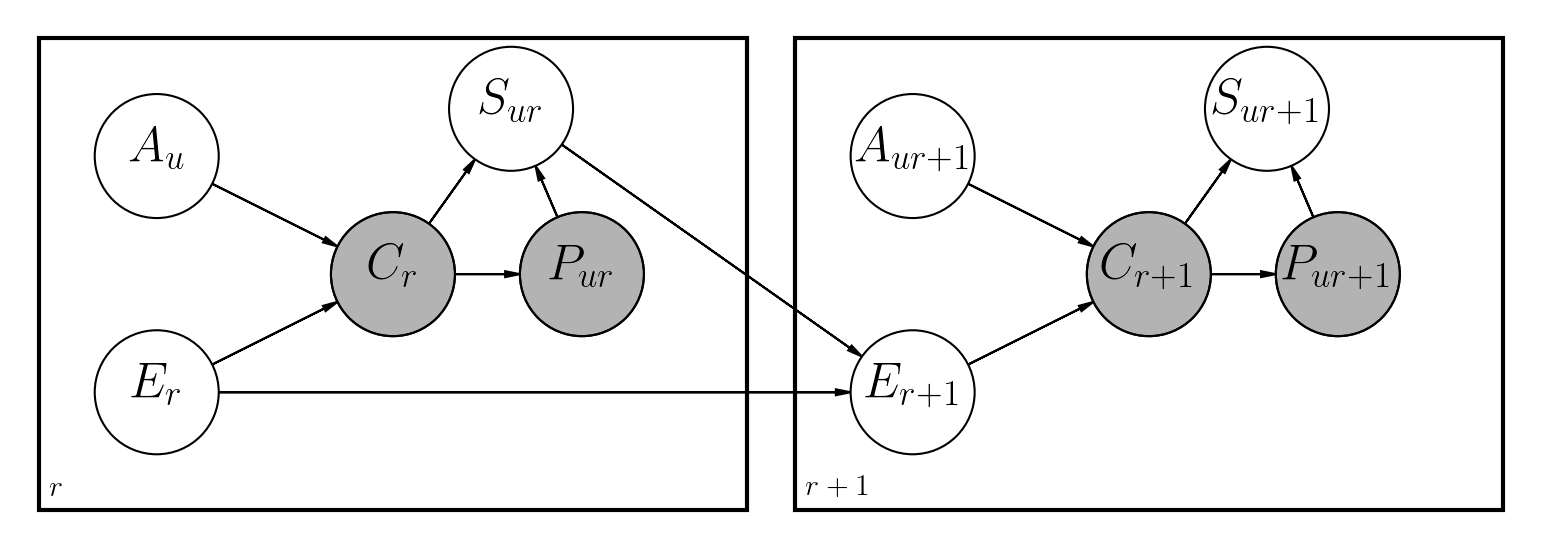
Основные различия:
File Notebooks/dbn.ipynb имеет полное описание того, как была реализована модель вместе со всей вовлеченной математикой.
Поскольку этот проект полагается на бинарные файлы, составленные Cython, в настоящее время поддерживается только платформа Linux (ManyLinux). Он может быть установлен с:
pip install pyClickModels
Pyclickmodels ожидает, что входные данные будут сохранены в наборе сжатых файлов gz , расположенных в той же папке. Все они должны начинать с строки «суждения», например, judgments0.gz . Каждый файл должен содержать отдельные jsons. Ниже приведен пример каждой линии JSON:
{
"search_keys" : {
"search_term" : " blue shoes " ,
"region" : " south " ,
"favorite_brand" : " super brand " ,
"user_size" : " L " ,
"avg_ticket" : 10
},
"judgment_keys" : [
{
"session" : [
{ "click" : 0 , "purchase" : 0 , "doc" : " doc0 " }
{ "click" : 1 , "purchase" : 0 , "doc" : " doc1 " }
{ "click" : 1 , "purchase" : 1 , "doc" : " doc2 " }
]
},
{
"session" : [
{ "click" : 1 , "purchase" : 0 , "doc" : " doc0 " }
{ "click" : 0 , "purchase" : 0 , "doc" : " doc1 " }
{ "click" : 0 , "purchase" : 0 , "doc" : " doc2 " }
]
}
]
} Ключ search_keys устанавливает контекст для поиска. В приведенном выше примере данный клиент (или кластер клиентов с тем же контекстом) искал blue shoes . Их регион - south (это может быть любая выбранная ценность), любимый бренд - super brand и так далее.
Эти ключи устанавливают контекст, для которого произошел поиск. Когда Pyclickmodels запускает свою оптимизацию, он будет рассмотреть весь контекст одновременно. Это означает, что полученные суждения также находятся на всем контекстом.
Если контекст не требуется, просто используйте {"search_keys": {"search_term": "user search"}} .
Здесь нет необходимой схемы, которая означает, что библиотека проходит через все ключи, доступные в search_keys , и создает процесс оптимизации, рассматривая весь контекст как один запрос.
Что касается judgment_keys , это список сессий. Ключевая session обязательно. Каждый сеанс содержит ClickStream пользователей (если покупка переменной не требуется, установите его на 0).
Для запуска DBN от Pyclickmodels, вот простой пример:
from pyClickModels . DBN import DBN
model = DBN ()
model . fit ( input_folder = "/tmp/clicks_data/" , iters = 10 )
model . export_judgments ( "/tmp/output.gz" )Выходной файл будет содержать отдельный файл json newline с помощью суждений для каждого запроса и каждого документа, наблюдаемого для этого запроса, т.е.
{ "search_term:blue shoes|region:south|brand:super brand" : { "doc0" : 0.2 , "doc1" : 0.3 , "doc2" : 0.4 }}
{ "search_term:query|region:north|brand:other_brand" : { "doc0" : 0.0 , "doc1" : 0.0 , "doc2" : 0.1 }}Суждения здесь варьируются от 0 до 1. Некоторые библиотеки требуют, чтобы они варьировались между целыми и 4 и 4. Выберите правильное преобразование в этом случае, которое лучше соответствует вашим данным.
Эта библиотека все еще альфа! Используйте его с осторожностью. Он был полностью проникновлен, но все еще его части используют Pure C, исключения которого еще не были полностью рассмотрены. Перед использованием этой библиотеки в производственных эвинациях рекомендуется полностью проверить ее с помощью различных наборов данных и размеров, чтобы оценить, как она работает.
Взносы очень приветствуются! Кроме того, если вы найдете ошибки, сообщите о них :).


