pyClickModels
v0.0.2
Una implementación de Cython de clickmodels que utiliza modelos gráficos probabilísticos para inferir el comportamiento del usuario al interactuar con los resultados de la página de búsqueda (clasificación).
ClickModels utiliza el concepto de modelos gráficos probabilísticos para modelar componentes que describen las interacciones entre los usuarios y una lista de elementos clasificados por un conjunto de reglas de recuperación.
Estos modelos tienden a ser útiles cuando se desea comprender si un documento determinado es una buena coincidencia para una consulta de búsqueda dada o no que también se conoce en la literatura como calificaciones de juicios . Esto es posible mediante la evaluación de los clics observados pasados y las posiciones en las que el documento apareció en las páginas de resultados para cada consulta.
Hay varios enfoques propuestos para manejar este problema. Este repositorio implementa una red bayesiana dinámica, similar a los trabajos anteriores también realizados en Python:
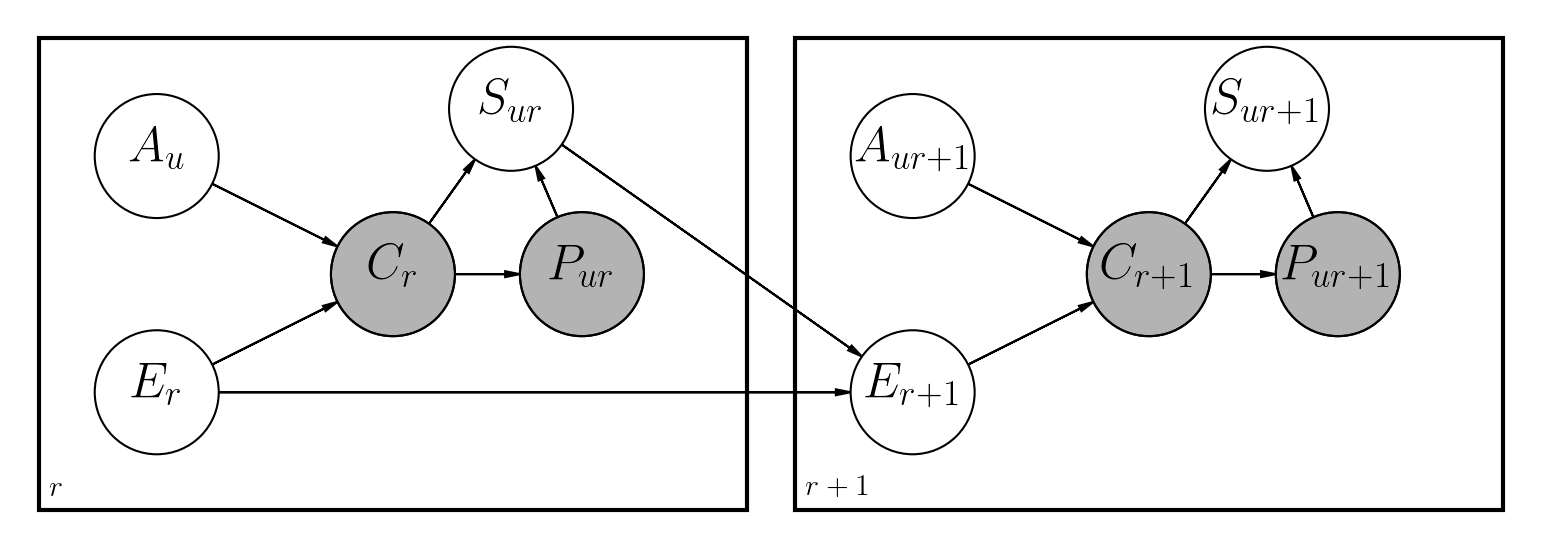
Las principales diferencias son:
El archivo cuadernos/dbn.ipynb tiene una descripción completa de cómo se ha implementado el modelo junto con todas las matemáticas involucradas.
Como este proyecto se basa en binarios compilados por Cython, actualmente solo es compatible con Linux (ManyLinux). Se puede instalar con:
pip install pyClickModels
PyClickModels espera que los datos de entrada se almacenen en un conjunto de archivos gz comprimidos ubicados en la misma carpeta. Todos deberían comenzar con los "juicios" de cadena, por ejemplo, judgments0.gz . Cada archivo debe contener JSON separados por línea. El siguiente es un ejemplo de cada línea JSON:
{
"search_keys" : {
"search_term" : " blue shoes " ,
"region" : " south " ,
"favorite_brand" : " super brand " ,
"user_size" : " L " ,
"avg_ticket" : 10
},
"judgment_keys" : [
{
"session" : [
{ "click" : 0 , "purchase" : 0 , "doc" : " doc0 " }
{ "click" : 1 , "purchase" : 0 , "doc" : " doc1 " }
{ "click" : 1 , "purchase" : 1 , "doc" : " doc2 " }
]
},
{
"session" : [
{ "click" : 1 , "purchase" : 0 , "doc" : " doc0 " }
{ "click" : 0 , "purchase" : 0 , "doc" : " doc1 " }
{ "click" : 0 , "purchase" : 0 , "doc" : " doc2 " }
]
}
]
} La tecla search_keys establece el contexto para la búsqueda. En el ejemplo anterior, un cliente determinado (o clúster de clientes con el mismo contexto) buscó blue shoes . Su región es south (podría ser cualquier valor elegido), la marca favorita es super brand , etc.
Estas claves establecen el contexto para el cual ocurrió la búsqueda. Cuando PyClickModels ejecuta su optimización, considerará todo el contexto a la vez. Esto significa que los juicios obtenidos también están en toda la configuración del contexto.
Si no se desea un contexto, simplemente use {"search_keys": {"search_term": "user search"}} .
Aquí no hay un esquema requerido, lo que significa que la biblioteca a través de todas las claves disponibles en search_keys y construye el proceso de optimización considerando todo el contexto como una sola consulta.
En cuanto a los judgment_keys , esta es una lista de sesiones. La session clave es obligatoria. Cada sesión contiene el clickstream de los usuarios (si no se requiere la compra variable, establecerla en 0).
Para ejecutar DBN de PyClickModels, aquí hay un ejemplo simple:
from pyClickModels . DBN import DBN
model = DBN ()
model . fit ( input_folder = "/tmp/clicks_data/" , iters = 10 )
model . export_judgments ( "/tmp/output.gz" )El archivo de salida contendrá un archivo separado JSON Newline con los juicios para cada consulta y cada documento observado para esa consulta, es decir:
{ "search_term:blue shoes|region:south|brand:super brand" : { "doc0" : 0.2 , "doc1" : 0.3 , "doc2" : 0.4 }}
{ "search_term:query|region:north|brand:other_brand" : { "doc0" : 0.0 , "doc1" : 0.0 , "doc2" : 0.1 }}Los juicios aquí varían entre 0 y 1. Algunas bibliotecas requieren que varíe entre enteros 0 y 4. Elija una transformación adecuada en este caso que se adapte mejor a sus datos.
¡Esta biblioteca sigue siendo alfa! Úselo con precaución. Ha estado completamente sin estar atento, pero aún así usan C pura C cuyas excepciones podrían no haber sido consideradas completamente todavía. Se recomienda, antes de usar esta biblioteca en emirmentos de producción, para probarlo completamente con diferentes conjuntos de datos y tamaños para evaluar cómo funciona.
¡Las contribuciones son muy bienvenidas! Además, si encuentra errores, infórmalos :).


