pyClickModels
v0.0.2
Eine Cython -Implementierung von ClickModels, die probabilistische grafische Modelle verwendet, um das Benutzerverhalten zu schließen, wenn sie mit den Ergebnissen der Suchseite (Ranking) interagieren.
ClickModels verwendet das Konzept der probabilistischen grafischen Modelle, um Komponenten zu modellieren, die die Interaktionen zwischen Benutzern und eine Liste von Elementen beschreiben, die durch eine Reihe von Abrufregeln eingestuft werden.
Diese Modelle sind tendenziell nützlich, wenn sie verstehen möchten, ob ein bestimmtes Dokument gut zu einer bestimmten Suchabfrage entspricht oder nicht, die in der Literatur auch als Urteile bekannt ist. Dies ist möglich, indem früher beobachtete Klicks und die Positionen bewertet werden, an denen das Dokument auf den Ergebnisseiten für jede Abfrage erschien.
Es gibt mehrere vorgeschlagene Ansätze, um dieses Problem zu lösen. Dieses Repository implementiert ein dynamisches Bayesian -Netzwerk, ähnlich wie bei früheren Arbeiten auch in Python:
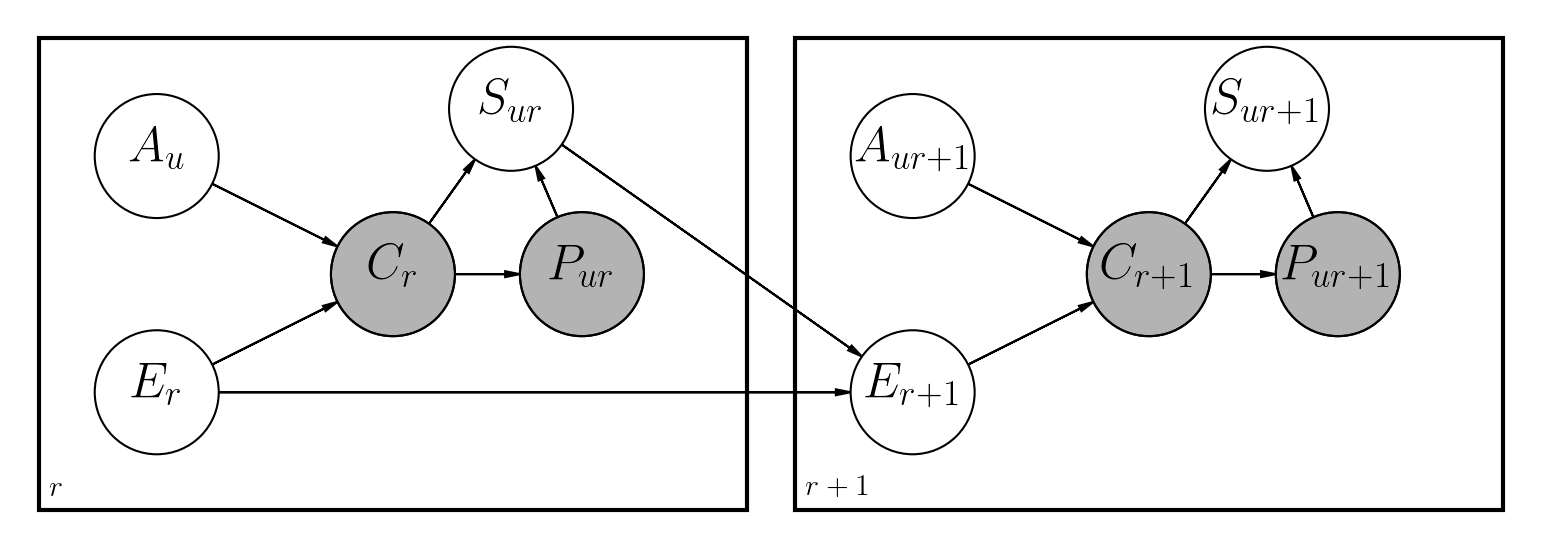
Hauptunterschiede sind:
Die Datei Notebooks/dbn.ipynb enthält eine vollständige Beschreibung, wie das Modell zusammen mit allen beteiligten Mathematik implementiert wurde.
Da dieses Projekt auf Binärdateien beruht, die von Cython zusammengestellt wurden, wird derzeit nur Linux (ManyLinux) -Plattform unterstützt. Es kann installiert werden mit:
pip install pyClickModels
Pyclickmodels erwartet, dass Eingabedaten in einem Satz komprimierter gz -Dateien auf demselben Ordner gespeichert werden. Sie alle sollten mit der Zeichenfolge "Urteile" beginnen, zum Beispiel judgments0.gz . Jede Datei sollte eine von Zeilen getrennte Jsons enthalten. Das Folgende ist ein Beispiel für jede JSON -Linie:
{
"search_keys" : {
"search_term" : " blue shoes " ,
"region" : " south " ,
"favorite_brand" : " super brand " ,
"user_size" : " L " ,
"avg_ticket" : 10
},
"judgment_keys" : [
{
"session" : [
{ "click" : 0 , "purchase" : 0 , "doc" : " doc0 " }
{ "click" : 1 , "purchase" : 0 , "doc" : " doc1 " }
{ "click" : 1 , "purchase" : 1 , "doc" : " doc2 " }
]
},
{
"session" : [
{ "click" : 1 , "purchase" : 0 , "doc" : " doc0 " }
{ "click" : 0 , "purchase" : 0 , "doc" : " doc1 " }
{ "click" : 0 , "purchase" : 0 , "doc" : " doc2 " }
]
}
]
} Die search_keys legt den Kontext für die Suche fest. Im obigen Beispiel suchte ein bestimmter Kunde (oder Cluster von Kunden mit demselben Kontext) nach blue shoes . Ihre Region ist south (es könnte jeder gewählte Wert sein), die Lieblingsmarke ist super brand und so weiter.
Diese Schlüssel setzen den Kontext, für den die Suche stattfand. Wenn Pyclickmodels seine Optimierung ausführt, wird der gesamte Kontext gleichzeitig berücksichtigt. Dies bedeutet, dass die erhaltenen Urteile ebenfalls im gesamten Kontexteinstellung sind.
Wenn kein Kontext gewünscht ist, verwenden Sie einfach {"search_keys": {"search_term": "user search"}} .
Hier gibt es kein erforderliches Schema, was bedeutet, dass die Bibliothek über alle in search_keys verfügbaren Schlüssel verläuft und den Optimierungsprozess unter Berücksichtigung des gesamten Kontextes als einzelne Abfrage erstellt.
Was das judgment_keys betrifft, so ist dies eine Liste von Sitzungen. Die session ist obligatorisch. Jede Sitzung enthält den ClickStream der Benutzer (wenn der Variablenkauf nicht erforderlich ist, setzen Sie ihn auf 0).
Für das Ausführen von DBN von Pyclickmodels finden Sie hier ein einfaches Beispiel:
from pyClickModels . DBN import DBN
model = DBN ()
model . fit ( input_folder = "/tmp/clicks_data/" , iters = 10 )
model . export_judgments ( "/tmp/output.gz" )Die Ausgabedatei enthält eine von der neu getrennte Datei mit den Urteilen für jede Abfrage und jedes für diese Abfrage beobachtete Dokument, dh:
{ "search_term:blue shoes|region:south|brand:super brand" : { "doc0" : 0.2 , "doc1" : 0.3 , "doc2" : 0.4 }}
{ "search_term:query|region:north|brand:other_brand" : { "doc0" : 0.0 , "doc1" : 0.0 , "doc2" : 0.1 }}Die Urteile hier variieren zwischen 0 und 1. Einige Bibliotheken verlangen, dass es zwischen Ganzzahlen 0 und 4 liegt. Wählen Sie in diesem Fall eine ordnungsgemäße Transformation aus, die Ihren Daten besser entspricht.
Diese Bibliothek ist immer noch Alpha! Verwenden Sie es mit Vorsicht. Es wurde vollständig nicht eingestellt, aber Teile davon verwenden reine C, deren Ausnahmen möglicherweise noch nicht vollständig in Betracht gezogen worden sein. Es wird empfohlen, diese Bibliothek in Produktionsentwicklungen zu verwenden, um sie mit unterschiedlichen Datensätzen und Größen vollständig zu testen, um die Leistung zu bewerten.
Beiträge sind sehr willkommen! Wenn Sie Fehler finden, melden Sie sie bitte :).


