pyClickModels
v0.0.2
Uma implementação do Cython de modelos clickmodels que usa modelos gráficos probabilísticos para inferir o comportamento do usuário ao interagir com os resultados da página de pesquisa (classificação).
O ClickModels usa o conceito de modelos gráficos probabilísticos para modelar componentes que descrevem as interações entre os usuários e uma lista de itens classificados por um conjunto de regras de recuperação.
Esses modelos tendem a ser úteis quando se deseja entender se um determinado documento é uma boa correspondência para uma determinada consulta de pesquisa ou não, que também é conhecida na literatura como graus de julgamentos . Isso é possível avaliando os cliques observados passados e as posições nas quais o documento apareceu nas páginas de resultados para cada consulta.
Existem várias abordagens propostas para lidar com esse problema. Este repositório implementa uma rede bayesiana dinâmica, semelhante aos trabalhos anteriores também feitos no Python:
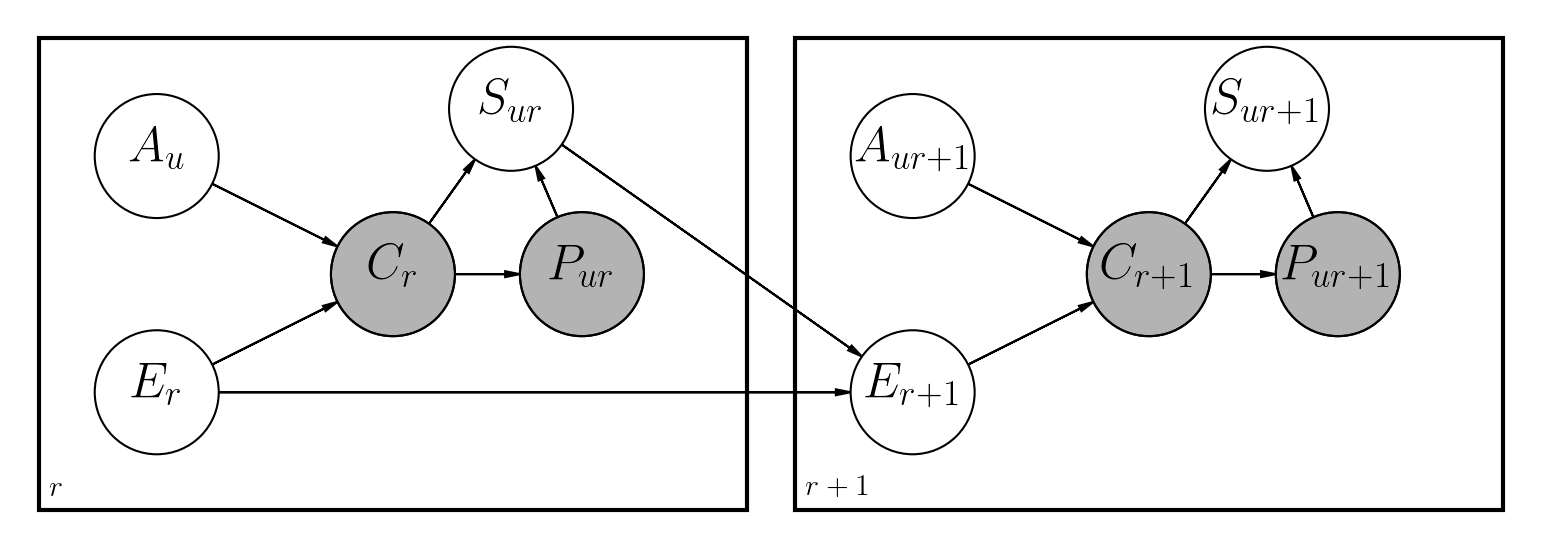
As principais diferenças são:
Os notebooks de arquivos/dbn.ipynb têm uma descrição completa de como o modelo foi implementado junto com todas as matemáticas envolvidas.
Como este projeto depende de binários compilados pela Cython, atualmente é suportado apenas a plataforma Linux (ManyLlinux). Pode ser instalado com:
pip install pyClickModels
O PyclickModels espera que os dados de entrada sejam armazenados em um conjunto de arquivos gz compactados localizados na mesma pasta. Todos eles devem começar com a string "julgamentos", por exemplo, judgments0.gz . Cada arquivo deve conter JSOs separados por linha. A seguir, é apresentado um exemplo de cada linha JSON:
{
"search_keys" : {
"search_term" : " blue shoes " ,
"region" : " south " ,
"favorite_brand" : " super brand " ,
"user_size" : " L " ,
"avg_ticket" : 10
},
"judgment_keys" : [
{
"session" : [
{ "click" : 0 , "purchase" : 0 , "doc" : " doc0 " }
{ "click" : 1 , "purchase" : 0 , "doc" : " doc1 " }
{ "click" : 1 , "purchase" : 1 , "doc" : " doc2 " }
]
},
{
"session" : [
{ "click" : 1 , "purchase" : 0 , "doc" : " doc0 " }
{ "click" : 0 , "purchase" : 0 , "doc" : " doc1 " }
{ "click" : 0 , "purchase" : 0 , "doc" : " doc2 " }
]
}
]
} A chave search_keys define o contexto para a pesquisa. No exemplo acima, um determinado cliente (ou cluster de clientes com o mesmo contexto) procurou blue shoes . A região deles é south (pode ser qualquer valor escolhido), a marca favorita é super brand e assim por diante.
Essas chaves definem o contexto para o qual a pesquisa aconteceu. Quando o Pyclickmodels executa sua otimização, ele considerará todo o contexto de uma só vez. Isso significa que os julgamentos obtidos também estão em toda a configuração de contexto.
Se nenhum contexto for desejado, basta usar {"search_keys": {"search_term": "user search"}} .
Não há esquema necessário aqui, o que significa que a biblioteca faz uma londa através de todas as teclas disponíveis em search_keys e cria o processo de otimização, considerando todo o contexto como uma única consulta.
Quanto aos judgment_keys , esta é uma lista de sessões. A session principal é obrigatória. Cada sessão contém a corrente de clique dos usuários (se a compra da variável não for necessária, defina -a como 0).
Para executar o DBN da Pyclickmodels, aqui está um exemplo simples:
from pyClickModels . DBN import DBN
model = DBN ()
model . fit ( input_folder = "/tmp/clicks_data/" , iters = 10 )
model . export_judgments ( "/tmp/output.gz" )O arquivo de saída conterá um arquivo separado da Newline JSON com os julgamentos de cada consulta e cada documento observado para essa consulta, ou seja::
{ "search_term:blue shoes|region:south|brand:super brand" : { "doc0" : 0.2 , "doc1" : 0.3 , "doc2" : 0.4 }}
{ "search_term:query|region:north|brand:other_brand" : { "doc0" : 0.0 , "doc1" : 0.0 , "doc2" : 0.1 }}Os julgamentos aqui variam entre 0 e 1. Algumas bibliotecas exigem que ele varie entre os números inteiros 0 e 4. Escolha uma transformação adequada neste caso que se adapte melhor aos seus dados.
Esta biblioteca ainda é alfa! Use -o com cautela. Ele tem sido totalmente desenvolvido, mas ainda parte dele usa C puro, cujas exceções podem não ter sido totalmente consideradas ainda. É recomendável, antes de usar esta biblioteca em elogios de produção, para testá -lo totalmente com diferentes conjuntos de dados e tamanhos para avaliar como ele se sai.
As contribuições são muito bem -vindas! Além disso, se você encontrar bugs, denuncie -os :).


