pyClickModels
v0.0.2
확률 론적 그래픽 모델을 사용하여 검색 페이지 결과 (순위)와 상호 작용할 때 사용자 동작을 유추하는 Cython 구현.
ClickModels는 확률 론적 그래픽 모델의 개념을 사용하여 사용자 간의 상호 작용과 일련의 검색 규칙에 따라 순위가 매겨진 항목 목록을 설명하는 구성 요소를 모델링합니다.
이 모델은 주어진 문서가 주어진 검색 쿼리와 잘 일치 하는지 여부를 이해하는 것이 좋을 때 유용한 경향이있는 경향이 있습니다. 이는 과거의 관찰 된 클릭과 문서가 각 쿼리의 결과 페이지에 나타난 위치를 평가함으로써 가능합니다.
이 문제를 처리하기위한 몇 가지 제안 된 접근법이 있습니다. 이 저장소는 Python에서 수행 된 이전 작품과 유사한 동적 베이지안 네트워크를 구현합니다.
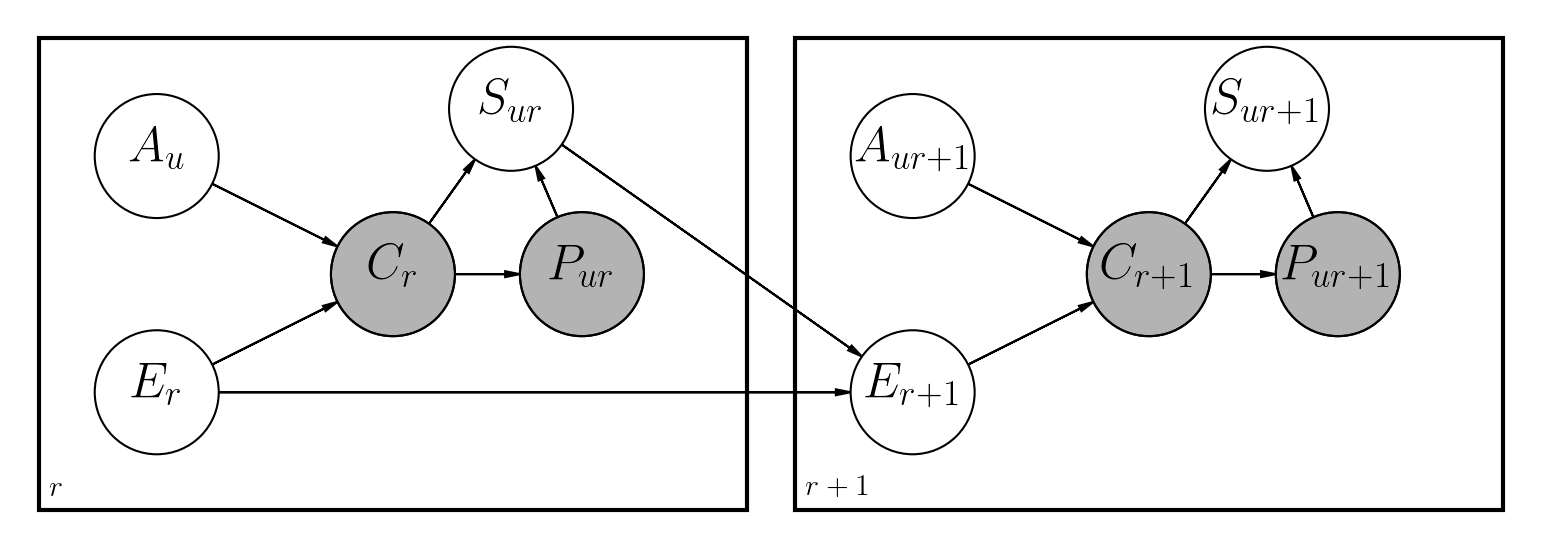
주요 차이점은 다음과 같습니다.
파일 노트북/dbn.ipynb에는 관련된 모든 수학과 함께 모델이 구현 된 방법에 대한 자세한 설명이 있습니다.
이 프로젝트는 Cython이 컴파일 한 Binaries에 의존하기 때문에 현재 Linux (Manyux) 플랫폼 만 지원됩니다. 다음과 같이 설치할 수 있습니다.
pip install pyClickModels
PyclickModels는 입력 데이터가 동일한 폴더에있는 압축 gz 파일 세트에 저장 될 것으로 기대합니다. 예를 들어 judgments0.gz 와 같은 문자열 "판단"으로 시작해야합니다. 각 파일에는 라인 분리 된 JSON이 포함되어야합니다. 다음은 각 JSON 라인의 예입니다.
{
"search_keys" : {
"search_term" : " blue shoes " ,
"region" : " south " ,
"favorite_brand" : " super brand " ,
"user_size" : " L " ,
"avg_ticket" : 10
},
"judgment_keys" : [
{
"session" : [
{ "click" : 0 , "purchase" : 0 , "doc" : " doc0 " }
{ "click" : 1 , "purchase" : 0 , "doc" : " doc1 " }
{ "click" : 1 , "purchase" : 1 , "doc" : " doc2 " }
]
},
{
"session" : [
{ "click" : 1 , "purchase" : 0 , "doc" : " doc0 " }
{ "click" : 0 , "purchase" : 0 , "doc" : " doc1 " }
{ "click" : 0 , "purchase" : 0 , "doc" : " doc2 " }
]
}
]
} 주요 search_keys 검색 컨텍스트를 설정합니다. 위의 예에서는 주어진 고객 (또는 동일한 상황을 가진 고객 클러스터)이 blue shoes 를 검색했습니다. 그들의 지역은 south (선택한 가치 일 수 있음), 좋아하는 브랜드는 super brand 등입니다.
이 키는 검색이 발생한 컨텍스트를 설정합니다. PyclickModels가 최적화를 실행하면 모든 컨텍스트를 한 번에 고려합니다. 이는 얻은 판단이 전체 상황 설정에도 있음을 의미합니다.
컨텍스트가 원하지 않으면 {"search_keys": {"search_term": "user search"}} 사용하십시오.
여기에는 필요한 스키마가 없으므로 search_keys 에서 사용 가능한 모든 키를 통해 라이브러리가 루프하고 전체 컨텍스트를 단일 쿼리로 고려하여 최적화 프로세스를 구축 함을 의미합니다.
judgment_keys 의 경우, 이것은 세션 목록입니다. 핵심 session 필수입니다. 각 세션에는 사용자의 클릭 스트림이 포함되어 있습니다 (변수 구매가 필요하지 않은 경우 0으로 설정).
PyclickModels에서 DBN을 실행하려면 간단한 예가 있습니다.
from pyClickModels . DBN import DBN
model = DBN ()
model . fit ( input_folder = "/tmp/clicks_data/" , iters = 10 )
model . export_judgments ( "/tmp/output.gz" )출력 파일에는 각 쿼리에 대한 판단과 해당 쿼리에 대해 관찰 된 각 문서가있는 Newline JSON 분리 파일이 포함됩니다.
{ "search_term:blue shoes|region:south|brand:super brand" : { "doc0" : 0.2 , "doc1" : 0.3 , "doc2" : 0.4 }}
{ "search_term:query|region:north|brand:other_brand" : { "doc0" : 0.0 , "doc1" : 0.0 , "doc2" : 0.1 }}여기서 판단은 0과 1 사이의 다릅니다. 일부 라이브러리는 정수 0과 4 사이의 범위를 요구합니다.이 경우 데이터에 더 적합한 적절한 변환을 선택하십시오.
이 라이브러리는 여전히 알파입니다! 주의해서 사용하십시오. 그것은 완전히 단위 테스트되었지만 여전히 예외는 아직 완전히 고려되지 않은 순수한 C를 사용합니다. 이 라이브러리를 생산 기반에 사용하기 전에 다양한 데이터 세트와 크기로 완전히 테스트하여 성능을 평가하는 것이 좋습니다.
기부금은 매우 환영합니다! 또한 버그를 찾으면 버그를보고하십시오 :).


