Deep Learning Color for Manga
1.0.0
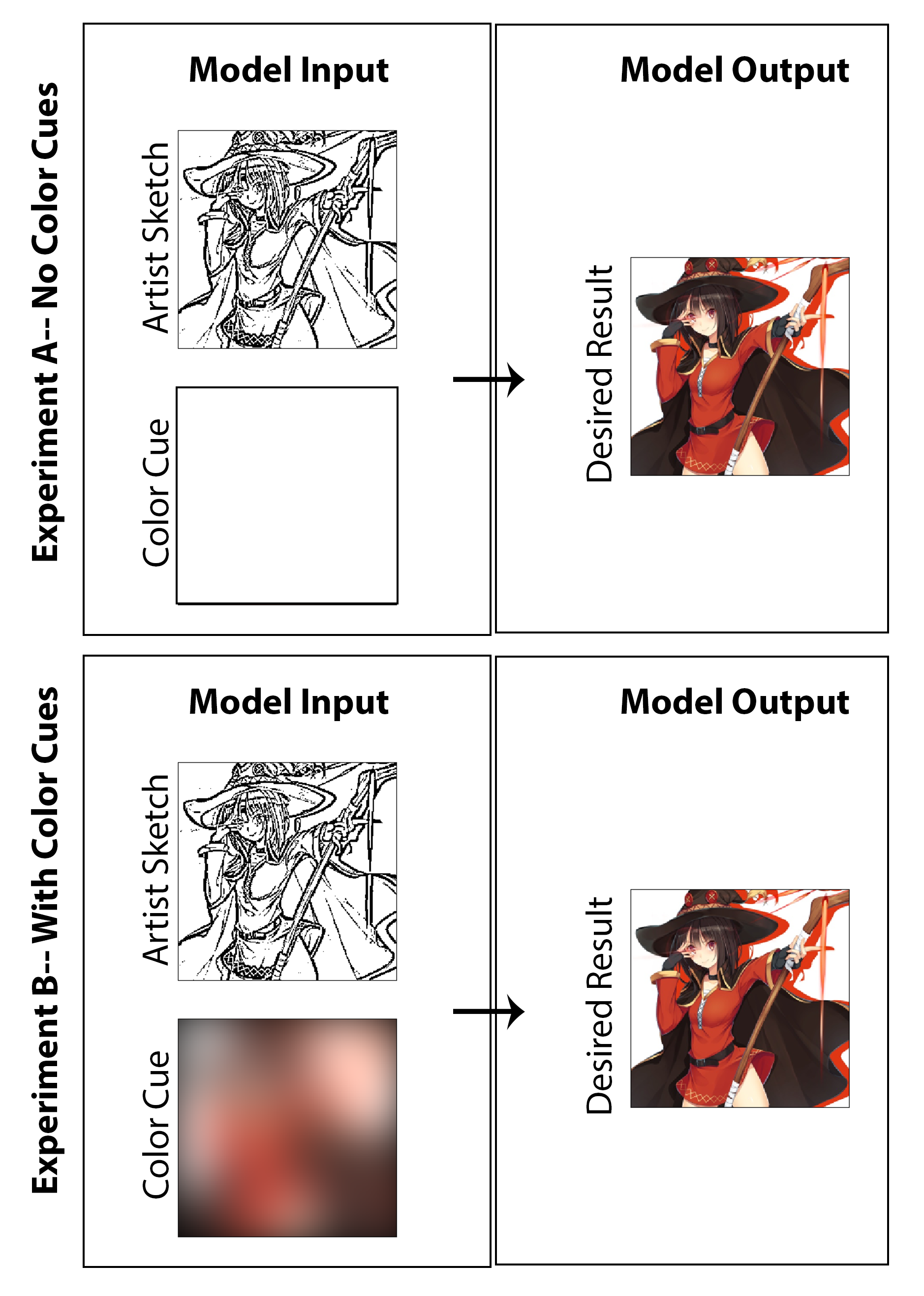

在這項工作中,目標是探索是否可以採用深度學習,以使漫畫藝術家能夠創建有色的漫畫印刷品,而不是傳統的黑白印刷品,而無需為創建者提供大量額外的時間或工作,而無需對媒介風格造成損害。雖然顯示的許多結果清楚地顯示了對機器著色的調查結果,但當我尋求創建一個不僅為圖像上色的體系結構,而且從未經拋光的早期階段素描沒有優質陰影開始時,還概述了草圖增強的問題。我認為,如果一個人可以從最終的啟動圖像開始(為藝術家減少繪圖時間),那麼這將被認為是成功的,然後通過實現我們所提出的架構來實現樣式保存,功能最終確定和全面著色。在這裡,我強調的是,我不認為一種無監督的著色方法是解決此特定問題的現實解決方案是有意義的,因此,我設計了專注於概念驗證解決方案的代碼,該解決方案允許藝術家通過用於整體圖像的“色彩亮點”提供輸入。話雖這麼說,我還產生了結果和一項研究,不包括藝術家的輸入(將顏色輸入設置為零matrix並重新訓練模型),以便在學術性質中調查結果。我認為兩者都很有趣,而且值得展示的調查。
在這裡,我發現此任務的最佳解決方案/起點是實現具有CNN體系結構的條件對抗網絡,並主要集中於將問題作為圖像到圖像的翻譯任務。我們的實施構建的動機和指導是A. Efros團隊在Berkley AI研究實驗室於2016年底發布的著名的,所謂的Pix2Pix架構。
這項工作中使用的生成器和歧視器的模型與PIX2PIX論文中報導的模型相同,並回顧了PDF中總結的技術細節。發電機和鑑別器都使用形式捲積式束縛 - RELU的模塊。有關組裝發電機和鑑別器的相關代碼,請參見腳本“ mainv3.py”。
培訓數據生成過程的第一步是獲得一套適合日本漫畫和動漫風格的數字色彩圖像。實際上,通過編寫一個網絡搭配的Python腳本可以輕鬆完成,該腳本自動從成像託管網站Danbooru中自動搜索和下載帶標記的圖像。該站點是此任務的理想選擇,因為它本質上是一個大規模的眾包,並標記了具有近400萬本動漫圖像的動漫數據集(據報導,總計超過1.08億個圖像標籤,可以快速過濾和搜索)。公平的戰爭:本網站上的許多圖像可以說不是“安全工作”的內容。使用GitHub上發布的代碼,我下載了大約9000張圖像(每張圖像約1秒),並使用幻想主題標籤(例如“ Holding Weaster”和“ Magic Solo”)下載。之後,通過調整和裁剪將這些圖像進一步在Python中進行處理,以便將所有圖像轉換為256 x 256平方。然後,這滿足了組件1構成高質量的數字色彩漫畫風格的藝術品。
對於訓練數據生成過程的最後一步,我建立了一種自動得出與彩色圖像相對應的顏色提示的方法。我想一個有效的系統將使藝術家通過用大量不同顏色的熒光筆在草圖上繪製草圖來快速創建顏色提示。在想像的過程中,他們也不必擔心在線條內著色或指定顏色或陰影的變化。為了以一種可能足以實現概念驗證實現且不需要任何手動數據集標籤的方式進行近似,我通過用大型高斯內核使彩色圖像模糊彩色圖像來為每個圖像創建顏色提示。從測試中,我發現具有20像素標準偏差的高斯濾波器定性地產生了所需效果。作為參考,這對應於大約50像素的FWHM,這是圖像寬度的近1/5。從此方法得出的顏色提示的三個示例及其相應的彩色圖像如下所示:

為了以公平而有見地的方式評估兩個實驗的訓練模型的功能,我在相同的,精心選擇的測試圖像集上回顧了每個實驗的性能。這些圖像中的六個可以在以下數字中看到。選擇這六個圖像是因為它們共同提出了三個不同級別的難度。因此,我將這六組分為三組,稱為評估“任務”。審查每個任務提出的預期挑戰的摘要,以越來越多的困難順序列出:
顏色任務:
對於此類的圖像,該模型已經對其他幾個直接包含這些字符的圖像進行了訓練,儘管以不同的姿勢或由其他藝術家繪製。這將測試對模型有充分條件以將問題作為分類任務提出問題的情況的性能,並藉助對象/角色識別。
轉移任務:
在訓練期間,這些測試圖像中存在的字符沒有直接變化;但是,此任務中圖像的總體主題和復雜性水平與培訓集的相匹配。該測試將評估模型能夠對角色記憶的依賴有限地執行真實的圖像翻譯。
插值任務:
這些圖像的複雜性值遠遠超過20%以上,比訓練數據集定義的截止閾值。該模型也從未見過這些字符的任何變化,這種類型的繪圖樣式(它不再具有類似於下載的Danbooru動漫集的功能),或具有相似邊緣密度的圖像。
上述三個評估任務的結果顯示在圖[圖:nocolorcuesresults]中,用於著色實驗,其中為發電機和圖[圖:withColorcuesResults]提供了為色彩提示提供的色彩學實驗。為了強調,前者可以被歸類為無監督的深入學習方法,而後者是受監督的。




