Deep Learning Color for Manga
1.0.0

В этой работе цель состояла в том, чтобы изучить, можно ли использовать глубокое обучение, чтобы дать возможность артистам манги создавать цветные принты манги вместо традиционных черно-белых принтов, не требуя значительного дополнительного времени или работы для создателя и не требуя компромисса стиля средств. Хотя большая часть показанных результатов четко отображает результаты исследования по раскраске машины, вопрос об улучшении эскизов также тонко исследуется, поскольку я стремлюсь создать архитектуру, которая не только окрашивает изображение, но и начинается с неполированного, раннего эскиза, лишенного качественного затенения. На мой взгляд, это будет считаться успешным, если можно начать с менее окончательного стартового изображения (сокращение времени рисования для художника) и при этом достичь как сохранение стиля, завершения функций и полную окрашивание путем реализации предлагаемой нашей архитектуры. Здесь я подчеркиваю, что я не верю, что подход к раскраске, не связанный с неэффективным, имеет смысл в качестве реального решения для этой конкретной проблемы, и в результате я разработал код, фокусирующийся на решении подтверждения концепции, которое позволяет художнику давать ввод с помощью «цветовой модели», используемого для общего изображения. С учетом вышесказанного я также сгенерировал результаты и исследование, исключая ввод художника, полностью (установление входов цвета в нулевую матрицу и переподготовка модели), чтобы исследовать в академическом характере, какими будут результаты. Я думаю, что оба одинаково интересные и забавные исследования, которые стоит провести.
Здесь я считаю, что лучшим решением/отправной точкой для этой задачи является реализация условной состязательной сети с архитектурой CNN и в основном сосредоточиться на создании проблемы в качестве задачи перевода с изображения на изображение. Мотивация и руководство, для которых наша реализация тесно создана,-это знаменитая, так называемая архитектура Pix2pix, выпущенная в конце 2016 года командой А. Эфроса в исследовательской лаборатории Berkley AI.
Модель для генератора и дискриминатора, используемой в этой работе, такая же, как и в документе Pix2PIX с обзором технических деталей, обобщенных в PDF. Как генератор, так и дискриминатор используют модули формы-свертываемости Batchnorm-Relu. Для сбора связанного кода, собирающего генератор и дискриминатор, см. Сценарии «mainv3.py».
Первым шагом в процессе генерации данных обучающих данных является получение большого набора изображений с цифровой окрашкой, которые соответствуют стилю японской манги и аниме. Это на самом деле легко сделано, написав сценарий Python, который автоматически ищет и загружает теги-изображения с веб-сайта хостинга Imaging, Danbooru. Этот сайт идеально подходит для этой задачи, так как это, по сути, крупномасштабный краудсорсин и помеченный набор данных аниме с почти 4 миллионами аниме-изображений (и, как сообщается, более 108 миллионов тегов изображений, что позволяет быстрая фильтрация и поиск). Справедливое оборудование: многие из изображений на этом сайте, возможно, не являются «безопасным для работы». Используя код, выпущенный на моем GitHub, я загрузил приблизительно 9000 изображений (примерно на 1 секунду на изображение) с фантастическими тегами, такими как «Holding Mast» и «Magic Solo». После того, как эти изображения дополнительно обрабатываются в Python с помощью изменения размера и обрезки, так что все изображения преобразуются в площадь 256 x 256. Затем это удовлетворяет компоненту 1, составляющему высококачественное, цифровое раскрашенное манговое искусство.
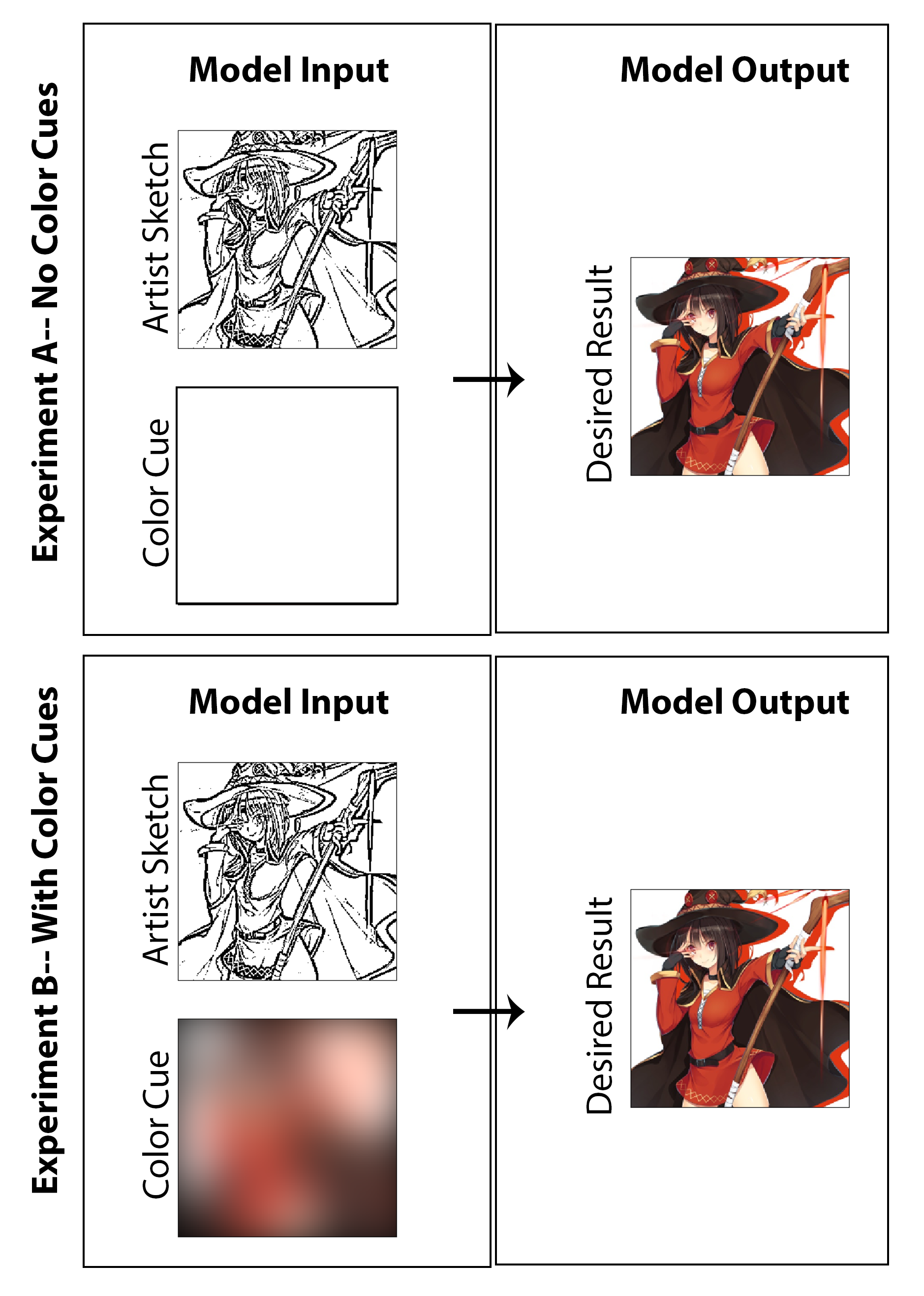
Для последнего шага в процессе создания обучающих данных я устанавливаю метод для автоматического вывода цветных сигналов, соответствующих цветным изображениям. Я полагаю, что эффективная система была бы для художника, чтобы очень быстро создать цветные сигналы, нарисовав набросок с большими маркерами разных цветов. В воображаемом процессе им также не нужно беспокоиться о раскраске внутри линий или указании вариаций цвета или оттенка. Чтобы приблизиться к этому таким образом, что это может быть достаточным для реализации подтверждения концепции и, не требуя каких-либо ручных маркировки наборов данных, я создаю цветные сигналы для каждого изображения, пространственно размывая цветные изображения с большим гауссовым ядром. Из тестирования я обнаружил, что гауссовый фильтр со стандартным отклонением в 20 пикселей качественно дает желаемый эффект. Для справки, это соответствует FWHM приблизительно 50 пикселей, что составляет почти 1/5 ширины изображения. Три примера цветовых сигналов, полученных из этого метода, и их соответствующие цветные изображения показаны ниже:

Чтобы оценить возможности обученных моделей для обоих экспериментов справедливым и проницательным способом, я рассматриваю производительность каждого на одном и том же, тщательно выбранном наборе испытательных изображений. Шесть из этих изображений можно увидеть на следующих фигурах. Эти шесть изображений были выбраны, поскольку они коллективно представляют три разных уровня сложности. Таким образом, я классифицировал шесть на три группы, упомянутые в этой работе как оценку «задачи». Резюме ожидаемой задачи, представленной каждой задачей, рассматривается следующим образом, перечислено в растущем порядке сложности:
Цветовое задание:
Для изображений в этом классе модель обучалась на нескольких других изображениях, непосредственно содержащих эти символы, хотя и представленные в другой позе или нарисованной другим художником. Это проверит производительность для случаев, когда модель хорошо подготовлена, чтобы сформулировать проблему в качестве задачи классификации и раскрашивать с помощью объекта/распознавания символов.
Задача передачи:
Прямой вариант символов, присутствующих в этих тестовых изображениях, ранее не показан модели во время обучения; Тем не менее, общая тема и уровень сложности изображений в этой задаче тесно соответствует уровню обучения. Этот тест оценит, насколько хорошо модель может выполнить истинный перевод изображения с ограниченной зависимостью от запоминания персонажа.
Задача интерполяции:
Эти изображения имеют значения сложности на 20% выше, чем порог отсечения, определенный для набора учебных данных. Модель также никогда не видела никаких вариаций этих символов, такого типа стиля рисования (у нее больше нет функций, похожих на загруженный набор аниме Danbooru), или изображения с одинаковой плотностью краев.
Результаты трех вышеупомянутых задач оценки здесь отображаются на рисунке [Рис.: Nocolorcuesresults] для эксперимента по раскраске, где не предоставляются цветовые сигналы художника для генератора и на рисунке [Рис.: Обеспечивает корпус -зернистых, для эксперимента по распределению, где предоставляются цветные сигналы. Для акцента, первое может быть классифицировано как неконтролируемый подход глубокого обучения, в то время как последний является контролируемым.




