Deep Learning Color for Manga
1.0.0
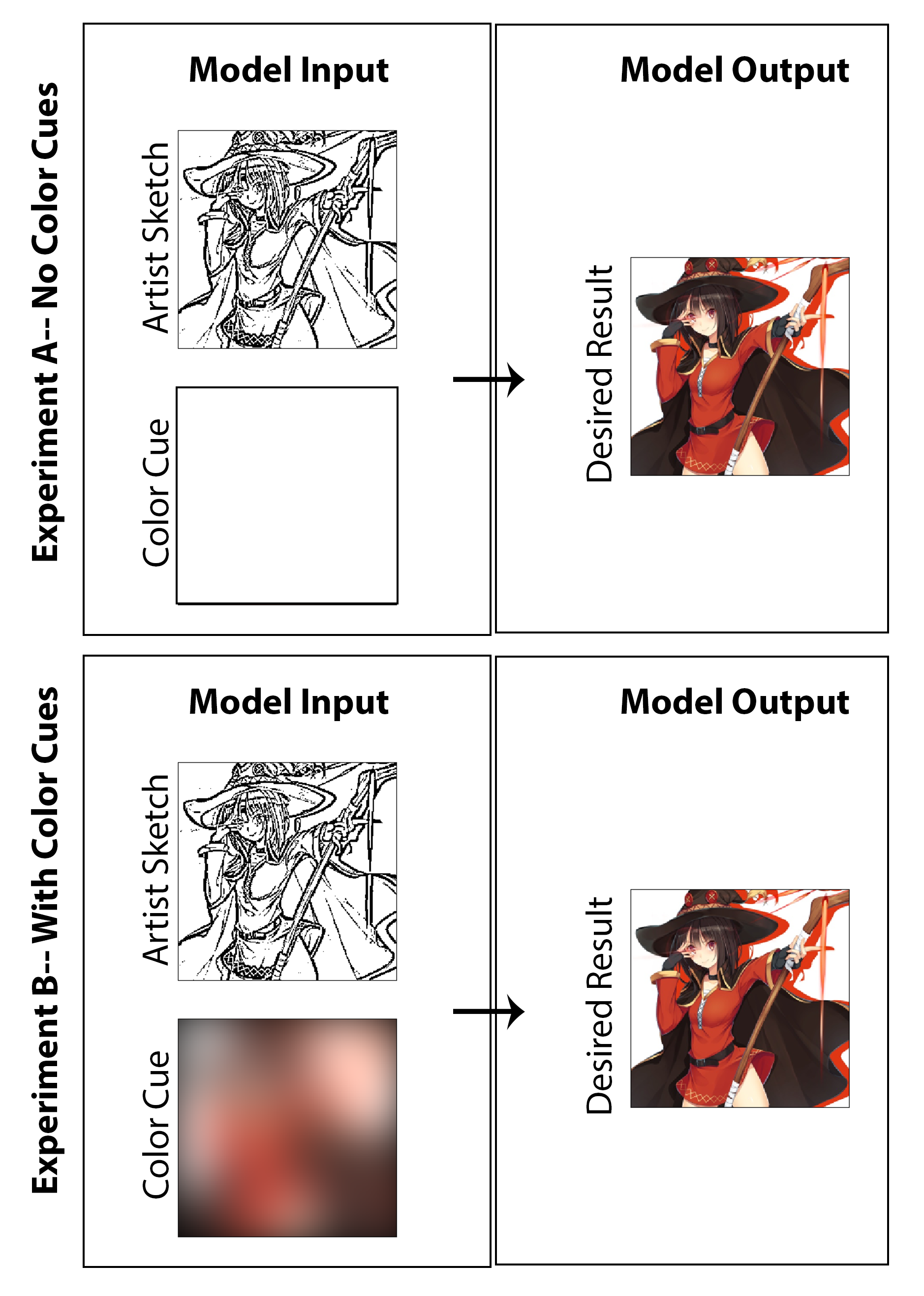

En este trabajo, el objetivo era explorar si se puede emplear un aprendizaje profundo para permitir a los artistas de manga crear impresiones de manga colorizadas en lugar de las impresiones tradicionales en blanco y negro sin requerir un tiempo o trabajo extra significativo para el creador y sin requerir un compromiso con el estilo de los medios. Si bien gran parte de los resultados que se muestran muestran claramente los resultados de la investigación sobre la colorización de la máquina, la cuestión de la mejora del boceto también se sondea sutilmente a medida que busco crear una arquitectura que no solo coloree una imagen, sino que comienza con un boceto no pulido y temprano sin sombreado de calidad. En mi opinión, se consideraría un éxito si uno puede comenzar con una imagen inicial menos final (reduciendo el tiempo de dibujo para el artista) y aún así lograr la preservación de estilo, finalización de características y colorización completa mediante la implementación de nuestra arquitectura propuesta. Aquí, destaco que no creo que un enfoque de colorización no supervisado tenga sentido como una solución del mundo real para este problema en particular, y como resultado, he diseñado el código centrado en una solución de prueba de concepto que permite al artista dar entrada a través de la "resaltada de color" utilizada para la imagen general. Dicho esto, también he generado resultados y un estudio que excluye por completo la entrada del artista (estableciendo entradas de color a una matriz cero y reentrenando el modelo) para investigar en naturaleza académica cuáles serían los resultados. Creo que ambos son investigaciones igualmente interesantes y divertidas que vale la pena presentar.
Aquí, encuentro que la mejor solución/punto de partida para esta tarea es implementar una red adversaria condicional con una arquitectura CNN y centrarse predominantemente en enmarcar el problema como una tarea de traducción de imagen a imagen. La motivación y la orientación para la cual nuestra implementación se construye estrechamente es la famosa arquitectura PIX2PIX publicada a fines de 2016 por el equipo de A. Efros en el Berkley AI Research Lab.
El modelo para el generador y el discriminador utilizado en este trabajo es el mismo que el informado en el documento PIX2PIX con una revisión de los detalles técnicos resumidos en el PDF. Tanto el generador como el discriminador utiliza módulos de la formulario de convolución-batchnorm-relu. Para el código relacionado que ensambla el generador y el discriminador, consulte los scripts "mainv3.py".
El primer paso en el proceso de generación de datos de entrenamiento es obtener un gran conjunto de imágenes colorizadas digitalmente que se ajusten al estilo de manga y anime japoneses. En realidad, esto se hace fácilmente escribiendo un script de python que raspan la web que busca y descarga automáticamente imágenes etiquetadas desde el sitio web de alojamiento de imágenes, Danbooru. Este sitio es ideal para esta tarea, ya que es esencialmente un crowdsource a gran escala y un conjunto de datos de anime etiquetado con casi 4 millones de imágenes de anime (y, según los informes, más de 108 millones de etiquetas de imagen en total permiten un filtrado y búsqueda rápida). Wary Waring: muchas de las imágenes en este sitio posiblemente no son contenido de "seguro para el trabajo". Usando el código publicado en mi github, descargué aproximadamente 9000 imágenes (en aproximadamente 1 segundo por imagen) con etiquetas con temas de fantasía como "Holding Staff" y "Magic Solo". Después, estas imágenes se procesan en Python a través del cambio de tamaño y el recorte de tal manera que todas las imágenes se convierten en un cuadrado de 256 x 256. Esto luego satisface el componente 1 que constituye el arte manga-manga de alta calidad y colorizado digitalmente.
Para el último paso en el proceso de generación de datos de capacitación, establezco un método para derivar automáticamente las señales de color correspondientes a las imágenes coloreadas. Me imagino que un sistema efectivo sería que un artista cree rápidamente señales de color dibujando sobre el boceto con grandes marcadores de diferentes colores. En el proceso imaginado, tampoco deberían preocuparse por colorear dentro de las líneas o especificar variaciones en color o sombra. Para aproximar esto de una manera que podría ser suficiente para una implementación de prueba de concepto y sin requerir ningún etiquetado de conjunto de datos manual, creo las señales de color para cada imagen borrando espacialmente las imágenes de color con un gran núcleo gaussiano. De las pruebas, descubrí que un filtro gaussiano con una desviación estándar de 20 píxeles produce cualitativamente el efecto deseado. Como referencia, esto corresponde a un FWHM de aproximadamente 50 píxeles, que es casi 1/5 del ancho de la imagen. Tres ejemplos de las señales de color derivadas de este método y sus imágenes de color correspondientes se muestran a continuación:

Para evaluar las capacidades de los modelos capacitados para ambos experimentos de una manera justa y perspicaz, reviso el rendimiento de cada uno en el mismo conjunto de imágenes de prueba cuidadosamente seleccionados. Seis de estas imágenes se pueden ver en las figuras siguientes. Estas seis imágenes fueron elegidas ya que colectivamente presentan tres niveles diferentes de dificultad. Como tal, he clasificado los seis en tres grupos mencionados en este trabajo como "tareas" de evaluación. Se revisa un resumen del desafío anticipado que presenta cada tarea a continuación, enumerada en un orden creciente de dificultad:
La tarea de color:
Para las imágenes en esta clase, el modelo ha entrenado en varias otras imágenes que contienen directamente estos personajes aunque se presentan en una pose diferente o dibujada por un artista diferente. Esto probará el rendimiento para los casos en que el modelo está bien acondicionado para formular el problema como una tarea de clasificación y colorear con la ayuda del reconocimiento de objetos/caracteres.
La tarea de transferencia:
No se han mostrado previamente la variación directa de los caracteres presentes en estas imágenes de prueba al modelo durante el entrenamiento; Sin embargo, el tema general y el nivel de complejidad de las imágenes en esta tarea coinciden estrechamente con el del conjunto de entrenamiento. Esta prueba evaluará qué tan bien el modelo puede realizar la traducción de la imagen verdadera con una dependencia limitada de la memorización del carácter.
La tarea de interpolación:
Estas imágenes tienen valores de complejidad más del 20% más altos que el umbral de corte definido para el conjunto de datos de entrenamiento. El modelo tampoco ha visto ninguna variación de estos caracteres, este tipo de estilo de dibujo (ya no tiene características similares al conjunto de anime Danbooru descargado), o imágenes con una densidad similar de bordes.
Los resultados de las tres tareas de evaluación antes mencionadas se muestran aquí en la Figura [Fig: NocolorcuesResults] para el experimento de colorización donde no se proporcionan señales de color del artista al generador y en la figura [Fig: With ColorcuesSults] para el experimento de colorización donde se proporcionan señales de color. Para enfatizar, el primero puede clasificarse como el enfoque de aprendizaje profundo no supervisado, mientras que el segundo es el supervisado.




