Deep Learning Color for Manga
1.0.0
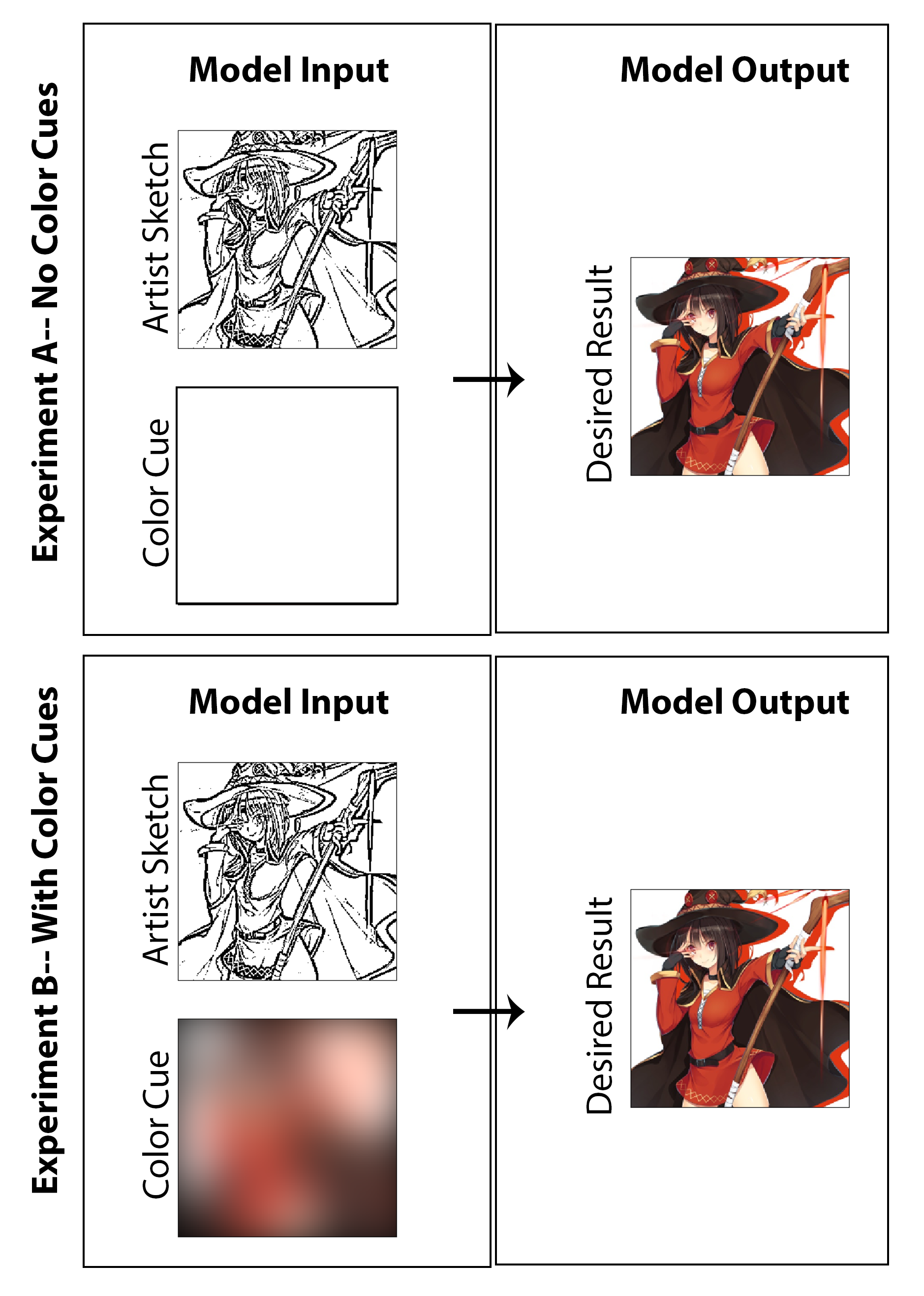

この作業では、目標は、マンガのアーティストが、クリエイターのためにかなりの余分な時間を必要とせず、メディアスタイルに妥協することなく、伝統的な白黒のプリントの代わりに色付けされた漫画プリントを作成できるようにするために、深い学習を採用できるかどうかを探ることでした。示されている結果の多くは、マシンの色彩化の調査結果を明確に示していますが、スケッチの強化の問題は、画像を色付けするだけでなく、質の高いシェーディングのない未磨きの初期段階のスケッチから始まるアーキテクチャを作成しようとするため、微妙に調査されます。私の意見では、最終的な開始イメージ(アーティストの描画時間を短縮)から始めて、提案されたアーキテクチャの実装によりスタイルの保存、機能の最終化、フルカラー化の両方を達成できれば、それは私の意見では成功と見なされます。ここでは、この特定の問題の現実世界のソリューションとしては、監視されていない色素化アプローチが理にかなっているとは思わないことを強調します。その結果、画像全体に使用される「カラーハイライト」を介してアーティストが入力を与えることができる概念実証ソリューションに焦点を当てたコードを設計しました。そうは言っても、私は結果と、アーティストの入力を完全に完全に除外する研究(ゼロマトリックスに色の入力を設定し、モデルを再訓練する)を生成しました。どちらも同様に興味深く、提示する価値のある調査を楽しみにしていると思います。
ここでは、このタスクの最良の解決策/出発点は、CNNアーキテクチャを使用して条件付き敵対的ネットワークを実装し、イメージからイメージへの翻訳タスクとして問題をフレーミングすることに主に焦点を合わせることであることがわかります。私たちの実装が密接に構築されている動機とガイダンスは、2016年後半にバークレーAIリサーチラボでA. EFROSのチームによってリリースされた有名でいわゆるPIX2PIXアーキテクチャです。
この作業で使用されているジェネレーターと判別器のモデルは、PDFに要約された技術的詳細のレビューを使用して、PIX2PIXペーパーで報告されているモデルと同じです。ジェネレーターと識別子の両方が、フォームConvolution-BatchNorm-Reluのモジュールを使用します。ジェネレーターと差別器を組み立てる関連コードについては、スクリプト「mainv3.py」を参照してください。
トレーニングデータ生成プロセスの最初のステップは、日本の漫画とアニメのスタイルに合ったデジタルカラー化された画像の大規模なセットを取得することです。これは、イメージングホスティングWebサイトDanbooruからタグ付き画像を自動的に検索およびダウンロードするWebスクリプトを作成することで、実際に簡単に実行できます。このサイトは、本質的に大規模なクラウドソースであり、400万件近くのアニメ画像を備えたアニメデータセットにタグ付けされているため、このタスクに最適です(伝えられるところによると、合計1億800万を超える画像タグを超えて、クイックフィルタリングと検索が可能です)。公正なワーニング:このサイトの画像の多くは、間違いなく「安全な」コンテンツではありません。 GitHubでリリースされたコードを使用して、「Holding Staff」や「Magic Solo」などのファンタジーをテーマにしたタグを使用して、約9000枚の画像(画像ごとに約1秒で)をダウンロードしました。その後、これらの画像は、すべての画像が256 x 256平方に変換されるように、サイズ変更とトリミングを介してPythonでさらに処理されます。これにより、高品質のデジタル色のマンガ風のアートを構成するコンポーネント1が満たされます。
トレーニングデータ生成プロセスの最後のステップでは、色付きの画像に対応するカラーキューを自動的に導出する方法を確立します。効果的なシステムは、アーティストが異なる色の大きな蛍光ペンでスケッチを描くことで、非常に迅速に色の合図を作成することだと思います。想像上のプロセスでは、彼らはまた、線の中で着色したり、色や日陰のバリエーションを指定することを心配する必要はありません。これを概念実証の実装に十分であり、手動のデータセットラベルを必要とせずに概説するために、大きなガウスカーネルで色付きの画像を空間的にぼやけすることにより、各画像の色キューを作成します。テストから、20ピクセルの標準偏差を持つガウスフィルターは、希望する効果を定性的に生成することがわかりました。参照のために、これは約50ピクセルのFWHMに対応し、画像の幅のほぼ1/5です。この方法とそれらの対応する色の画像から導き出されたカラーキューの3つの例を以下に示します。

両方の実験の訓練されたモデルの機能を公正かつ洞察に満ちた方法で評価するために、同じように慎重に選択されたテスト画像のセットでそれぞれのパフォーマンスをレビューします。これらの画像のうち6つは、以下の図で見ることができます。これらの6つの画像は、3つの異なるレベルの難易度をまとめて提示するため、選択されました。そのため、この作業で言及されている3つのグループに、評価「タスク」と呼ばれる3つのグループに分類しました。各タスクが提示する予想される課題の要約は、難易度の増加にリストされているとレビューされます。
色のタスク:
このクラスの画像の場合、このモデルは、これらのキャラクターを直接含む他のいくつかの画像でトレーニングしていますが、別のアーティストによって提示されたり、描かれたりします。これにより、モデルが分類タスクとして問題を策定し、オブジェクト/キャラクター認識を使用して色付けする場合のパフォーマンスをテストします。
転送タスク:
これらのテスト画像に存在する文字の直接的な変動は、トレーニング中にモデルに以前に示されていません。ただし、このタスクの画像の全体的なテーマと複雑さレベルは、トレーニングセットの画像と密接に一致しています。このテストでは、モデルがキャラクターの記憶に依存して真の画像翻訳をどれだけうまく実行できるかを評価します。
補間タスク:
これらの画像は、トレーニングデータセットで定義されたカットオフしきい値よりも20%をはるかに高く複雑さを持っています。このモデルは、これらのキャラクターのバリエーションも見たことがありません。このタイプの描画スタイル(ダウンロードされたダンブールアニメセットに似た機能がなくなりました)、または同様のエッジの密度のある画像。
ここでは、前述の3つの評価タスクの結果を図[図:nocolorcuesResults]に、発電機にカラーキューが提供されていない色素化実験の場合、図[図:ColorcuesResults]に色キューが提供される色素化実験のために表示されます。強調するために、前者は教師なしの深い学習アプローチとして分類でき、後者は監督されています。




