Deep Learning Color for Manga
1.0.0
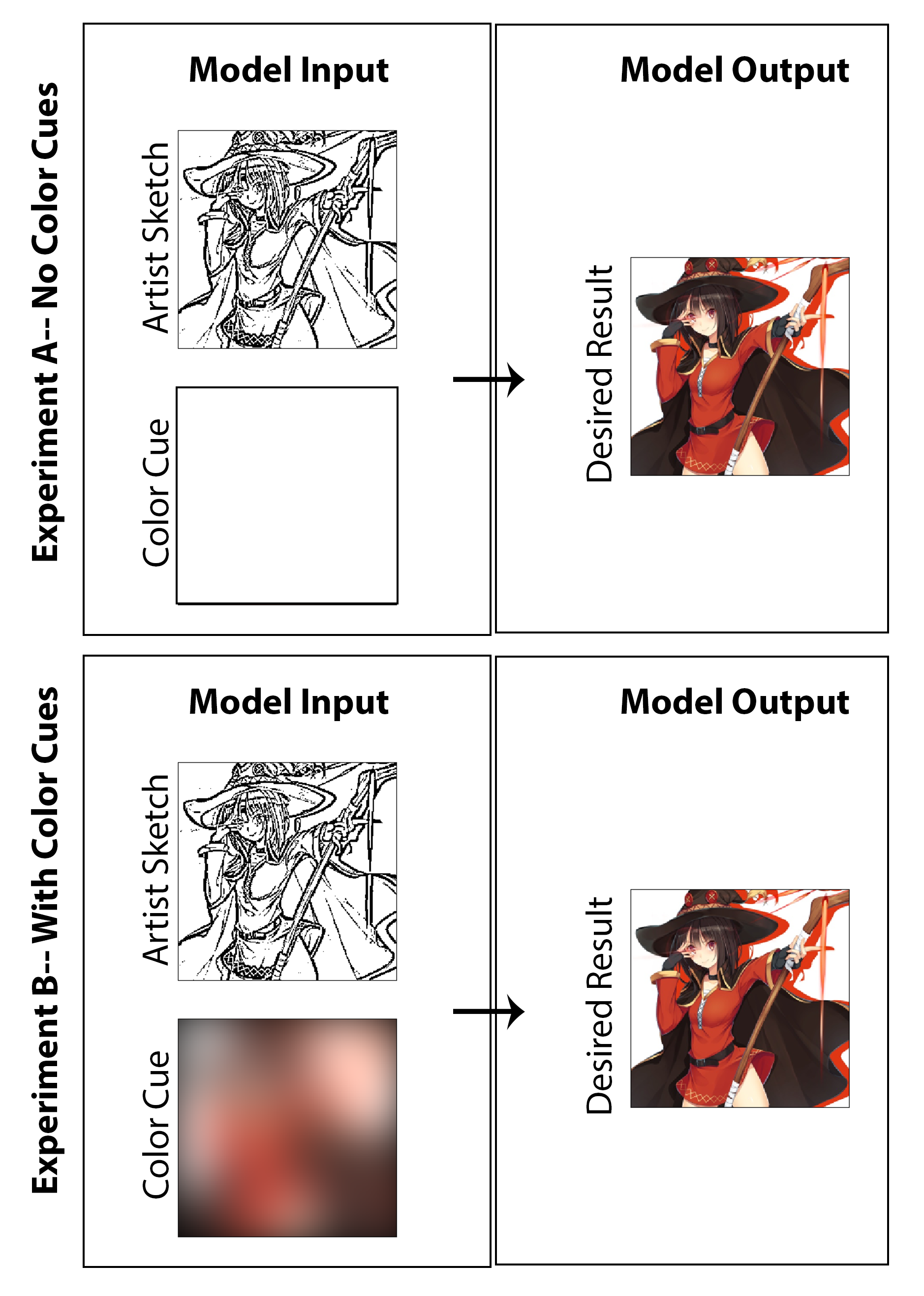

ในงานนี้เป้าหมายคือการสำรวจว่าการเรียนรู้อย่างลึกซึ้งสามารถใช้เพื่อให้ศิลปินมังงะสามารถสร้างภาพพิมพ์มังงะสีแทนภาพพิมพ์ขาวดำแบบดั้งเดิมโดยไม่ต้องใช้เวลาพิเศษหรือทำงานให้กับผู้สร้างและไม่ต้องประนีประนอมกับสไตล์สื่อ ในขณะที่ผลลัพธ์ส่วนใหญ่ที่แสดงอย่างชัดเจนแสดงผลลัพธ์ของการตรวจสอบเกี่ยวกับการทำสีของเครื่อง แต่คำถามของการปรับปรุงภาพร่างก็ถูกตรวจสอบอย่างละเอียดในขณะที่ฉันพยายามสร้างสถาปัตยกรรมซึ่งไม่เพียง แต่ระบายสีภาพ แต่เริ่มต้นด้วยภาพร่างระยะแรกที่ไม่ผ่านการขัด มันจะถือว่าเป็นความสำเร็จในความคิดของฉันถ้าใครสามารถเริ่มต้นด้วยภาพเริ่มต้นขั้นสุดท้ายน้อยลง (ลดเวลาการวาดภาพสำหรับศิลปิน) และยังคงได้รับการอนุรักษ์สไตล์ทั้งสองการสรุปคุณสมบัติและการทำสีเต็มรูปแบบโดยการใช้สถาปัตยกรรมที่เราเสนอ ที่นี่ฉันเน้นว่าฉันไม่เชื่อว่าวิธีการปรับแต่งสีที่ไม่ได้รับการดูแลนั้นสมเหตุสมผลเป็นวิธีแก้ปัญหาในโลกแห่งความเป็นจริงสำหรับปัญหานี้โดยเฉพาะและด้วยเหตุนี้ฉันได้ออกแบบรหัสที่มุ่งเน้นไปที่โซลูชันการพิสูจน์แนวคิดที่ช่วยให้ศิลปินสามารถป้อนผ่าน "ไฮไลท์สี" ที่ใช้สำหรับภาพรวม ด้วยการกล่าวว่าฉันได้สร้างผลลัพธ์และการศึกษาที่ไม่รวมอินพุตของศิลปินทั้งหมด (การตั้งค่าอินพุตสีเป็นศูนย์เมทริกซ์และการฝึกอบรมแบบจำลองใหม่) เพื่อตรวจสอบในลักษณะทางวิชาการว่าผลลัพธ์จะเป็นอย่างไร ฉันคิดว่าทั้งคู่น่าสนใจและน่าขบขันที่น่าสนใจก็คุ้มค่าที่จะนำเสนอ
ที่นี่ฉันพบว่าโซลูชัน/จุดเริ่มต้นที่ดีที่สุดสำหรับงานนี้คือการใช้เครือข่ายฝ่ายตรงข้ามแบบมีเงื่อนไขกับสถาปัตยกรรม CNN และมุ่งเน้นไปที่การกำหนดกรอบปัญหาเป็นงานแปลเป็นภาพเป็นภาพ แรงจูงใจและคำแนะนำที่การดำเนินการของเราถูกสร้างขึ้นอย่างใกล้ชิดคือสถาปัตยกรรม Pix2Pix ที่มีชื่อเสียงและมีชื่อเสียงที่เปิดตัวในปลายปี 2559 โดยทีมงานของ A. Efros ที่ห้องปฏิบัติการวิจัย Berkley AI
แบบจำลองสำหรับเครื่องกำเนิดและ discriminator ที่ใช้ในงานนี้เหมือนกับที่รายงานในกระดาษ Pix2Pix พร้อมการตรวจสอบรายละเอียดทางเทคนิคที่สรุปไว้ใน PDF ทั้งเครื่องกำเนิดไฟฟ้าและ discriminator ใช้โมดูลของแบบฟอร์ม convolution-batchnorm-relu สำหรับรหัสที่เกี่ยวข้องที่รวบรวมเครื่องกำเนิดและ discriminator ดูสคริปต์“ mainv3.py”
ขั้นตอนแรกในกระบวนการสร้างข้อมูลการฝึกอบรมคือการได้รับภาพสีดิจิตอลขนาดใหญ่ที่เหมาะสมกับรูปแบบของมังงะญี่ปุ่นและอนิเมะ จริง ๆ แล้วทำได้ง่ายๆโดยการเขียนสคริปต์ Python ที่สกรูเว็บที่ค้นหาและดาวน์โหลดภาพที่ติดแท็กจากเว็บไซต์โฮสติ้งภาพโดยอัตโนมัติ Danbooru ไซต์นี้เหมาะสำหรับงานนี้เนื่องจากเป็น crowdsource ขนาดใหญ่และติดแท็กชุดข้อมูลอนิเมะที่มีภาพอะนิเมะเกือบ 4 ล้านภาพ (และมีรายงานว่ามีแท็กรูปภาพมากกว่า 108 ล้านแท็กรวมการกรองและการค้นหาอย่างรวดเร็ว) Warining Fair: ภาพจำนวนมากในเว็บไซต์นี้ไม่ได้เป็นเนื้อหาที่“ ปลอดภัยสำหรับการทำงาน” ด้วยการใช้รหัสที่เปิดตัวใน GitHub ของฉันฉันดาวน์โหลดภาพประมาณ 9000 ภาพ (ประมาณ 1 วินาทีต่อภาพ) ด้วยแท็กธีมแฟนตาซีเช่น“ Holding Staff” และ“ Magic Solo” หลังจากนั้นภาพเหล่านี้จะถูกประมวลผลเพิ่มเติมใน Python ผ่านการปรับขนาดและการครอบตัดเพื่อให้ภาพทั้งหมดถูกแปลงเป็น 256 x 256 ตาราง สิ่งนี้จะเป็นไปตามส่วนประกอบที่ 1 ซึ่งประกอบไปด้วยศิลปะมังงะที่มีคุณภาพสูงและเป็นดิจิทัล
สำหรับขั้นตอนสุดท้ายในกระบวนการสร้างข้อมูลการฝึกอบรมฉันสร้างวิธีการที่จะได้รับสัญญาณสีที่สอดคล้องกับภาพสีโดยอัตโนมัติ ฉันจินตนาการว่าระบบที่มีประสิทธิภาพสำหรับศิลปินในการสร้างตัวชี้นำสีอย่างรวดเร็วโดยวาดภาพร่างด้วยปากกาเน้นข้อความขนาดใหญ่ที่มีสีต่างกัน ในกระบวนการที่จินตนาการพวกเขายังไม่จำเป็นต้องกังวลเกี่ยวกับการระบายสีภายในเส้นหรือระบุความแปรปรวนของสีหรือร่มเงา เพื่อประมาณสิ่งนี้ในลักษณะที่เพียงพอสำหรับการพิสูจน์แนวคิดของแนวคิดและไม่ต้องใช้การติดฉลากชุดข้อมูลด้วยตนเองใด ๆ ฉันสร้างตัวชี้นำสีสำหรับแต่ละภาพโดยการเบลอภาพสีด้วยเคอร์เนลเกาส์ขนาดใหญ่ จากการทดสอบฉันพบว่าตัวกรองเกาส์เซียนที่มีค่าเบี่ยงเบนมาตรฐาน 20 พิกเซลในเชิงคุณภาพสร้างผลที่ต้องการ สำหรับการอ้างอิงสิ่งนี้สอดคล้องกับ FWHM ประมาณ 50 พิกเซลซึ่งเกือบ 1/5 ความกว้างของภาพ สามตัวอย่างของตัวชี้นำสีที่ได้จากวิธีนี้และภาพสีที่สอดคล้องกันของพวกเขาจะแสดงในด้านล่าง:

เพื่อประเมินความสามารถของโมเดลที่ผ่านการฝึกอบรมสำหรับการทดลองทั้งสองอย่างยุติธรรมและลึกซึ้งฉันจะตรวจสอบประสิทธิภาพของแต่ละชุดในชุดทดสอบที่เลือกอย่างระมัดระวัง หกภาพเหล่านี้สามารถเห็นได้ในตัวเลขดังต่อไปนี้ ภาพทั้งหกนี้ได้รับการคัดเลือกเนื่องจากมีความยากลำบากสามระดับที่แตกต่างกัน เช่นนี้ฉันได้จำแนกกลุ่มหกเป็นสามกลุ่มที่อ้างถึงในงานนี้ว่าเป็นการประเมินผล“ งาน” บทสรุปของความท้าทายที่คาดการณ์ไว้แต่ละงานนำเสนอจะได้รับการตรวจสอบดังต่อไปนี้โดยระบุไว้ในการเพิ่มลำดับความยาก:
งานสี:
สำหรับภาพในคลาสนี้โมเดลได้ฝึกฝนภาพอื่น ๆ อีกหลายภาพที่มีตัวละครเหล่านี้โดยตรงแม้ว่าจะนำเสนอในรูปแบบที่แตกต่างกันหรือวาดโดยศิลปินที่แตกต่างกัน สิ่งนี้จะทดสอบประสิทธิภาพสำหรับกรณีที่แบบจำลองได้รับการปรับสภาพอย่างดีเพื่อกำหนดปัญหาเป็นงานการจำแนกประเภทและสีด้วยความช่วยเหลือของการจดจำวัตถุ/ตัวละคร
งานถ่ายโอน:
ไม่มีการเปลี่ยนแปลงโดยตรงของอักขระที่มีอยู่ในภาพทดสอบเหล่านี้ก่อนหน้านี้แสดงให้เห็นถึงโมเดลในระหว่างการฝึกอบรม อย่างไรก็ตามธีมโดยรวมและระดับความซับซ้อนของภาพในงานนี้ตรงกับชุดการฝึกอบรม การทดสอบนี้จะประเมินว่าโมเดลสามารถทำการแปลภาพที่แท้จริงได้ดีเพียงใดด้วยการพึ่งพาการจดจำอักขระที่ จำกัด
งานการแก้ไข:
ภาพเหล่านี้มีค่าความซับซ้อนสูงกว่าเกณฑ์การตัดที่กำหนดไว้สำหรับชุดข้อมูลการฝึกอบรมมากกว่า 20% รุ่นนี้ไม่เคยเห็นการเปลี่ยนแปลงใด ๆ ของตัวละครเหล่านี้สไตล์การวาดรูปแบบนี้ (มันไม่มีคุณสมบัติคล้ายกับชุดอะนิเมะ Danbooru ที่ดาวน์โหลดมาอีกต่อไป) หรือรูปภาพที่มีความหนาแน่นของขอบที่คล้ายกัน
ผลลัพธ์ของงานประเมินผลทั้งสามดังกล่าวแสดงอยู่ที่นี่ในรูปที่ [รูปที่: nocolorcuesresults] สำหรับการทดลองทำสีที่ไม่มีตัวชี้นำสีของศิลปินให้กับเครื่องกำเนิดไฟฟ้าและในรูปที่ [รูป: กับ Colorcuesresults] สำหรับการเน้นอดีตสามารถจำแนกได้ว่าเป็นวิธีการเรียนรู้ที่ลึกล้ำที่ไม่ได้รับการดูแลในขณะที่หลังเป็นผู้ดูแล




