Deep Learning Color for Manga
1.0.0
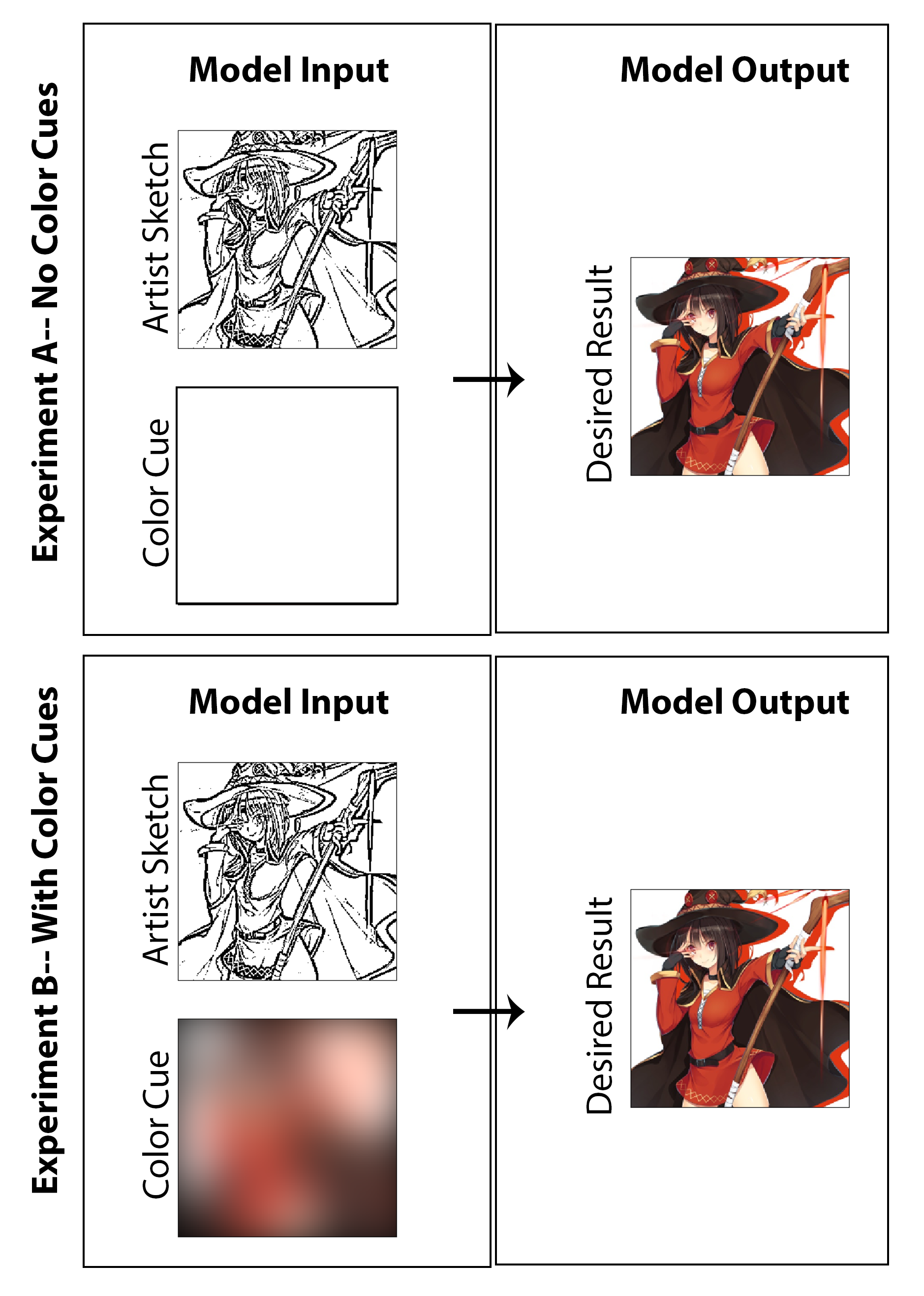

In dieser Arbeit bestand das Ziel darin, zu untersuchen, ob Deep Learning eingesetzt werden kann, damit Manga-Künstler farbige Manga-Drucke anstelle der traditionellen Schwarz-Weiß-Drucke erstellen können, ohne eine erhebliche Verlängerung oder Arbeit für den Schöpfer zu erfordern und einen Kompromiss zum Medienstil zu erfordern. Während ein Großteil der gezeigten Ergebnisse die Ergebnisse der Untersuchung der Maschinenfarbe deutlich zeigt, wird die Frage der Skizzenverbesserung auch subtil untersucht, da ich eine Architektur erstellen möchte, die nicht nur ein Bild foliert, sondern mit einer unpolierten Skizzierung der frühen Stufe ohne Qualitätsschattierung beginnt. Meiner Meinung nach wird es als Erfolg angesehen, wenn man mit einem weniger endgültigen Startbild beginnen kann (Reduzierung der Zeichenzeit für den Künstler) und dann sowohl die Erhaltung des Stils, die Abschlussarbeit und die vollständige Farbkolorisierung durch Implementierung unserer vorgeschlagenen Architektur erreichen. Hier hebe ich hervor, dass ich nicht glaube, dass ein nicht beträchtlicher Farbkolorisierungsansatz als reale Lösung für dieses spezielle Problem sinnvoll ist. Daher habe ich den Code entwickelt, der sich auf eine Proof-of-Concept-Lösung konzentriert, die es dem Künstler ermöglicht, Eingaben über das für das Gesamtbild verwendete „Farb-Highlight“ zu geben. Vor diesem Hintergrund habe ich auch Ergebnisse und eine Studie generiert, ohne die Künstlereingabe auszuschließen (Farbeingänge auf ein Nullmatrix zu setzen und das Modell umzuschicken), um in akademischer Natur zu untersuchen, was die Ergebnisse sein würden. Ich denke, beide sind ebenso interessante und amüsante Untersuchungen, die es wert sind, vorgelegt zu werden.
Hier finde ich, dass die beste Lösung/der beste Ausgangspunkt für diese Aufgabe darin besteht, ein bedingtes kontroverses Netzwerk mit einer CNN-Architektur zu implementieren und sich überwiegend auf die Rahmung des Problems als Image-zu-Image-Übersetzungsaufgabe zu konzentrieren. Die Motivation und Anleitung, aus der unsere Implementierung eng aufgebaut ist, ist die berühmte, sogenannte Pix2Pix-Architektur, die Ende 2016 vom Team von A. EFROS im Berkley AI Research Lab veröffentlicht wurde.
Das Modell für Generator und Diskriminator, das in dieser Arbeit verwendet wird, ist das gleiche wie das im PIX2PIX -Papier angegebenen technischen Details, die im PDF zusammengefasst sind. Sowohl der Generator als auch der Diskriminator verwenden Module der Form FIRCULTY-BATCHNORM-RELU. Für den zugehörigen Code, der den Generator und Diskriminator zusammenstellt, finden Sie in den Skripten „MainV3.Py“.
Der erste Schritt im Prozess der Trainingsdatengenerierung besteht darin, einen großen Satz digital farbiger Bilder zu erhalten, die zum Stil japanischer Manga und Anime passen. Dies ist tatsächlich einfach durch das Schreiben eines Web-Scraping-Python-Skripts zu erfolgen, das automatisch mit dem Taging-Hosting-Website Danbooru mit dem Taging-Markierungen sucht und heruntergeladen wird. Diese Site ist ideal für diese Aufgabe, da es sich im Wesentlichen um ein großes Crowdsource und ein markiertes Anime-Datensatz mit fast 4 Millionen Anime-Bildern handelt (und Berichten zufolge über 108 Millionen Image-Tags insgesamt eine schnelle Filterung und Suche ermöglicht). Fair Waring: Viele der Bilder auf dieser Website sind wohl nicht „sicher für die Arbeit“. Mit dem in meinem GitHub veröffentlichten Code habe ich ungefähr 9000 Bilder (bei etwa 1 Sekunde pro Bild) mit Fantasy -thematischen Tags wie „Holding Staff“ und „Magic Solo“ heruntergeladen. Danach werden diese Bilder in Python weiter verarbeitet, indem sie die Größenänderung und das Schneiden so beschneiden, dass alle Bilder auf ein 256 x 256 Quadrat konvertiert werden. Dies erfüllt die Komponente 1 dann die hochwertige, digital farbige Manga-ähnliche Kunst.
Für den letzten Schritt im Prozess der Trainingsdatengenerierung stelle ich eine Methode fest, um automatisch Farbpunkte abzuleiten, die den farbigen Bildern entsprechen. Ich kann mir vorstellen, dass ein effektives System es sein würde, dass ein Künstler sehr schnell Farbstoffe erzeugt, indem er die Skizze mit großen Highlightern verschiedener Farben zeichnet. Im imaginären Prozess müssten sie sich auch keine Sorgen machen, sich innerhalb der Linien zu färben oder Variationen in Farbe oder Schatten anzugeben. Um dies auf eine Weise zu approximieren, die für eine Implementierung von Proof-of-Concept-Implementierungen ausreicht, und ohne eine manuelle Datensatzkennzeichnung zu benötigen, erstelle ich die Farbzeichen für jedes Bild, indem ich die farbigen Bilder mit einem großen Gaußschen Kernel räumlich verwischte. Aus Tests stellte ich fest, dass ein Gaußscher Filter mit einer Standardabweichung von 20 Pixel qualitativ den gewünschten Effekt erzeugt. Als Referenz entspricht dies einem FWHM von ungefähr 50 Pixel, was fast 1/5 die Breite des Bildes entspricht. Drei Beispiele für die aus dieser Methode abgeleiteten Farbhinweise und deren entsprechenden farbigen Bilder sind unten angezeigt:

Um die Fähigkeiten der geschulten Modelle für beide Experimente auf faire und aufschlussreiche Weise zu bewerten, überprüfe ich die Leistung jeder auf demselben, sorgfältig ausgewählten Satz von Testbildern. Sechs dieser Bilder sind in den folgenden Abbildungen zu sehen. Diese sechs Bilder wurden ausgewählt, als sie gemeinsam drei verschiedene Schwierigkeitsstufen aufwiesen. Daher habe ich die sechs in drei Gruppen eingeteilt, die in dieser Arbeit als Bewertung „Aufgaben“ genannt werden. Eine Zusammenfassung der erwarteten Herausforderung, die jede Aufgabe vorlegt, wird folgt, die in zunehmender Reihenfolge der Schwierigkeit aufgeführt sind:
Die Farbaufgabe:
Für Bilder in dieser Klasse hat das Modell auf mehreren anderen Bildern trainiert, die diese Zeichen direkt enthalten, obwohl sie in einer anderen Pose dargestellt oder von einem anderen Künstler gezeichnet wurden. Dadurch wird die Leistung für Fälle getestet, in denen das Modell gut konditioniert ist, um das Problem als Klassifizierungsaufgabe zu formulieren und mit Hilfe der Objekt-/Zeichenerkennung zu fördern.
Die Übertragungsaufgabe:
Während des Trainings wurde dem Modell keine direkte Variation der in diesen Testbildern vorhandenen Zeichen gezeigt. Das Gesamtthema- und Komplexitätsniveau der Bilder in dieser Aufgabe entspricht jedoch genau dem des Trainingssatzes. In diesem Test wird bewertet, wie gut das Modell eine echte Bildübersetzung mit begrenztem Abhängigkeit von Charakterauswendungen durchführen kann.
Die Interpolationsaufgabe:
Diese Bilder haben Komplexitätswerte weit über 20% höher als der für den Trainingsdatensatz definierte Grenzschwellenwert. Das Modell hat auch noch nie eine Variation dieser Zeichen, diese Art des Zeichenstils (es gibt keine Funktionen mehr wie das heruntergeladene Danbooru -Anime -Set) oder Bilder mit einer ähnlichen Dichte von Kanten.
Die Ergebnisse der drei oben genannten Bewertungsaufgaben sind hier in Abbildung [Abb.: NocolorcuesResults] für das Farbpolizeiversuche angezeigt, bei dem dem Generator keine Farbausweise für Künstler zur Verfügung gestellt werden, und in Abbildung [Abb.: With ColorcuesResults] für das Farbversuche, bei dem Farbscues bereitgestellt werden. Zur Betonung kann ersterer als der unbeaufsichtigte tiefgreifende Ansatz eingestuft werden, während der letztere der überwachte ist.




