Deep Learning Color for Manga
1.0.0
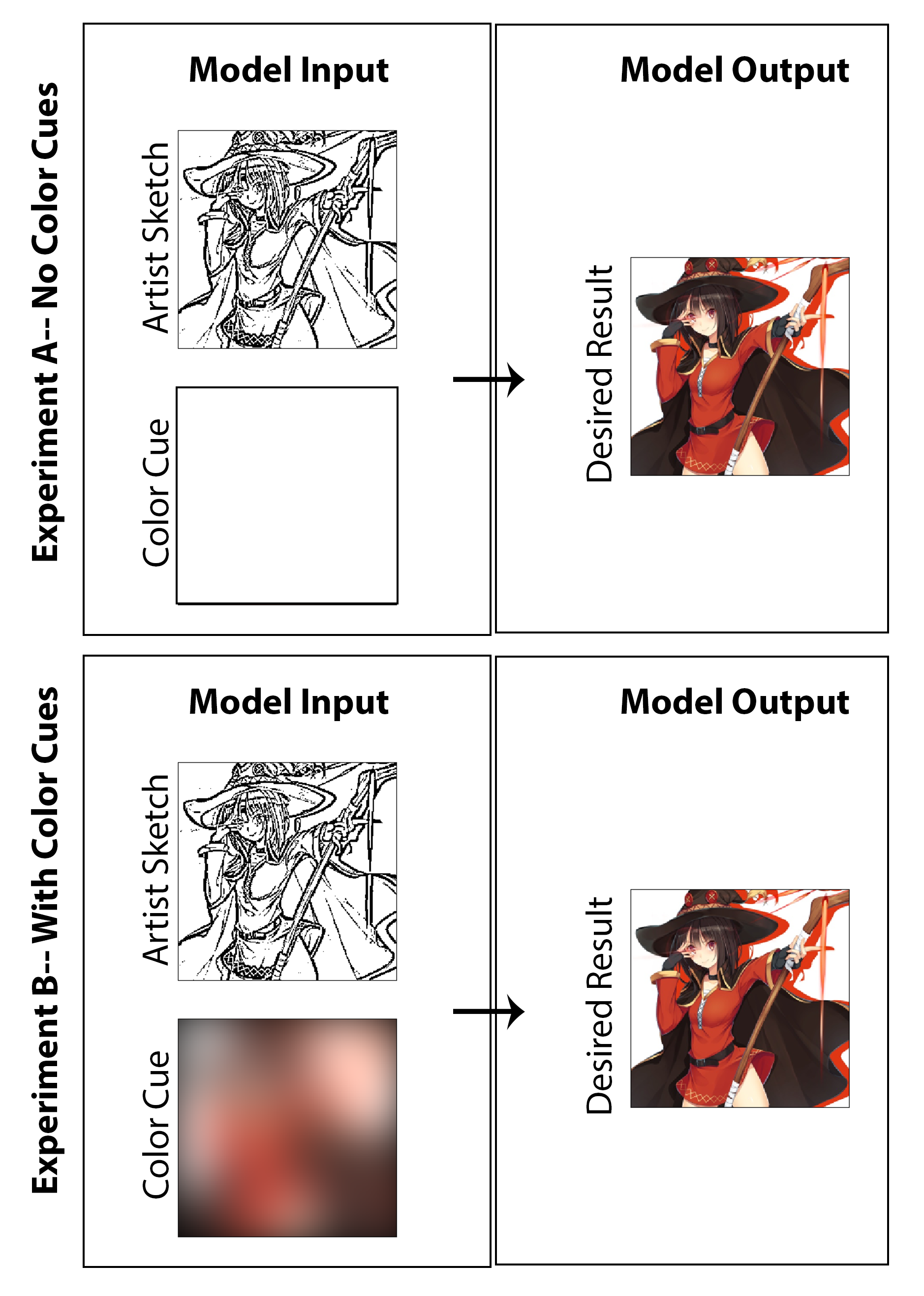

Dalam karya ini, tujuannya adalah untuk mengeksplorasi jika pembelajaran yang mendalam dapat digunakan untuk memungkinkan seniman manga untuk membuat cetakan manga berwarna alih-alih cetakan hitam-putih tradisional tanpa memerlukan waktu tambahan yang signifikan atau bekerja untuk pencipta dan tanpa memerlukan kompromi dengan gaya medium. Sementara banyak hasil yang ditampilkan dengan jelas menampilkan hasil penyelidikan ke pewarnaan mesin, pertanyaan tentang peningkatan sketsa juga diselidiki secara halus saat saya berusaha membuat arsitektur yang tidak hanya mengwolomer gambar tetapi dimulai dengan sketsa tahap awal yang tidak dipoles tanpa bayangan kualitas. Ini akan dianggap sukses menurut saya jika seseorang dapat memulai dengan gambar awal yang kurang akhir (mengurangi waktu menggambar untuk artis) dan masih mencapai pelestarian gaya, finalisasi fitur dan pewarnaan penuh dengan implementasi arsitektur yang kami usulkan. Di sini, saya menyoroti bahwa saya tidak percaya pendekatan pewarnaan yang tidak diawasi masuk akal sebagai solusi dunia nyata untuk masalah khusus ini, dan sebagai hasilnya, saya telah merancang kode yang berfokus pada solusi bukti konsep yang memungkinkan artis untuk memberikan input melalui "sorotan warna" yang digunakan untuk keseluruhan gambar. Dengan itu dikatakan, saya juga telah menghasilkan hasil dan studi tidak termasuk input artis sepenuhnya (mengatur input warna ke nol-matrix dan melatih kembali model) untuk menyelidiki secara akademik apa hasilnya. Saya pikir keduanya sama -sama menarik dan investigasi lucu yang layak disajikan.
Di sini, saya menemukan bahwa solusi/titik awal terbaik untuk tugas ini adalah mengimplementasikan jaringan permusuhan bersyarat dengan arsitektur CNN dan untuk fokus terutama pada membingkai masalah sebagai tugas penerjemahan gambar-ke-gambar. Motivasi dan bimbingan tempat implementasi kami dibangun dengan ketat adalah arsitektur PIX2PIX yang terkenal dan disebut yang dirilis pada akhir 2016 oleh tim A. Efros di Berkley AI Research Lab.
Model untuk generator dan diskriminator yang digunakan dalam karya ini sama dengan yang dilaporkan dalam makalah PIX2PIX dengan ulasan detail teknis yang dirangkum dalam PDF. Baik generator maupun diskriminator menggunakan modul bentuk convolution-batchnorm-relu. Untuk kode terkait yang merakit generator dan diskriminator, lihat skrip “Mainv3.py”.
Langkah pertama dalam proses pembuatan data pelatihan adalah mendapatkan serangkaian besar gambar berwarna digital yang sesuai dengan gaya manga dan anime Jepang. Ini sebenarnya mudah dilakukan dengan menulis skrip Python yang menggerakkan web yang secara otomatis mencari dan mengunduh gambar yang ditandai dari situs web hosting pencitraan, Danbooru. Situs ini sangat ideal untuk tugas ini karena pada dasarnya adalah dataset crowdsource skala besar dan menandai dataset anime dengan hampir 4 juta gambar anime (dan dilaporkan lebih dari 108 juta tag gambar total yang memungkinkan penyaringan dan pencarian cepat). WARINING FAIR: Banyak gambar di situs ini bukan konten "aman-untuk-bekerja". Menggunakan kode yang dirilis pada github saya, saya mengunduh sekitar 9000 gambar (sekitar 1 detik per gambar) dengan tag bertema fantasi seperti "staf holding" dan "solo solo". Setelah itu, gambar -gambar ini diproses lebih lanjut dalam Python melalui pengubah ukuran dan pemangkasan sehingga semua gambar dikonversi menjadi 256 x 256 persegi. Ini kemudian memenuhi komponen 1 yang membentuk seni manga-esque berkualitas tinggi dan berkualitas tinggi.
Untuk langkah terakhir dalam proses pembuatan data pelatihan, saya membuat metode untuk secara otomatis memperoleh isyarat warna yang sesuai dengan gambar berwarna. Saya membayangkan sistem yang efektif adalah bagi seorang seniman untuk dengan sangat cepat membuat isyarat warna dengan menggambar sketsa dengan sorotan besar dengan warna yang berbeda. Dalam proses yang dibayangkan, mereka juga tidak perlu khawatir tentang pewarnaan di dalam garis atau menentukan variasi warna atau naungan. Untuk memperkirakan ini dengan cara yang bisa cukup untuk implementasi bukti konsep dan tanpa memerlukan pelabelan dataset manual apa pun, saya membuat isyarat warna untuk setiap gambar dengan secara spasial mengaburkan gambar berwarna dengan kernel Gaussian besar. Dari pengujian, saya menemukan bahwa filter Gaussian dengan standar deviasi 20 piksel secara kualitatif menghasilkan efek yang diinginkan. Untuk referensi, ini sesuai dengan FWHM sekitar 50 piksel yang hampir 1/5 lebar gambar. Tiga contoh isyarat warna yang berasal dari metode ini dan gambar berwarna yang sesuai ditampilkan di bawah ini:

Untuk mengevaluasi kemampuan model yang terlatih untuk kedua percobaan dengan cara yang adil dan berwawasan luas, saya meninjau kinerja masing -masing pada set pengujian yang sama, dipilih dengan cermat. Enam dari gambar -gambar ini dapat dilihat pada gambar berikut. Keenam gambar ini dipilih karena mereka secara kolektif menghadirkan tiga tingkat kesulitan yang berbeda. Dengan demikian, saya telah mengklasifikasikan enam menjadi tiga kelompok yang disebut dalam pekerjaan ini sebagai evaluasi "tugas". Ringkasan tantangan yang diantisipasi setiap tugas disajikan diikuti, terdaftar dalam meningkatkan urutan kesulitan:
Tugas Warna:
Untuk gambar di kelas ini, model ini telah dilatih pada beberapa gambar lain yang secara langsung berisi karakter -karakter ini meskipun disajikan dalam pose yang berbeda atau digambar oleh artis yang berbeda. Ini akan menguji kinerja untuk kasus-kasus di mana model dikondisikan dengan baik untuk merumuskan masalah sebagai tugas klasifikasi dan mewarnai dengan bantuan pengenalan objek/karakter.
Tugas transfer:
Tidak ada variasi langsung dari karakter yang ada dalam gambar uji ini sebelumnya telah ditunjukkan pada model selama pelatihan; Namun, tingkat keseluruhan tema dan kompleksitas gambar dalam tugas ini sangat cocok dengan set pelatihan. Tes ini akan mengevaluasi seberapa baik model dapat melakukan terjemahan gambar sejati dengan ketergantungan terbatas pada menghafal karakter.
Tugas interpolasi:
Gambar -gambar ini memiliki nilai kompleksitas lebih dari 20% lebih tinggi dari ambang batas cutoff yang ditentukan untuk set data pelatihan. Model ini juga belum pernah melihat variasi karakter ini, jenis gaya menggambar ini (tidak lagi memiliki fitur yang mirip dengan set anime Danbooru yang diunduh), atau gambar dengan kepadatan tepi yang serupa.
Hasil dari tiga tugas evaluasi yang disebutkan di sini ditampilkan pada gambar [Gambar: NocolorcuesResults] untuk percobaan pewarnaan di mana tidak ada isyarat warna artis yang disediakan untuk generator dan pada gambar [Gambar: dengan WithColorCuesResults] untuk percobaan pewarnaan di mana isyarat warna disediakan. Untuk penekanan, yang pertama dapat diklasifikasikan sebagai pendekatan pembelajaran dalam yang tidak diawasi sementara yang terakhir diawasi.




