Deep Learning Color for Manga
1.0.0
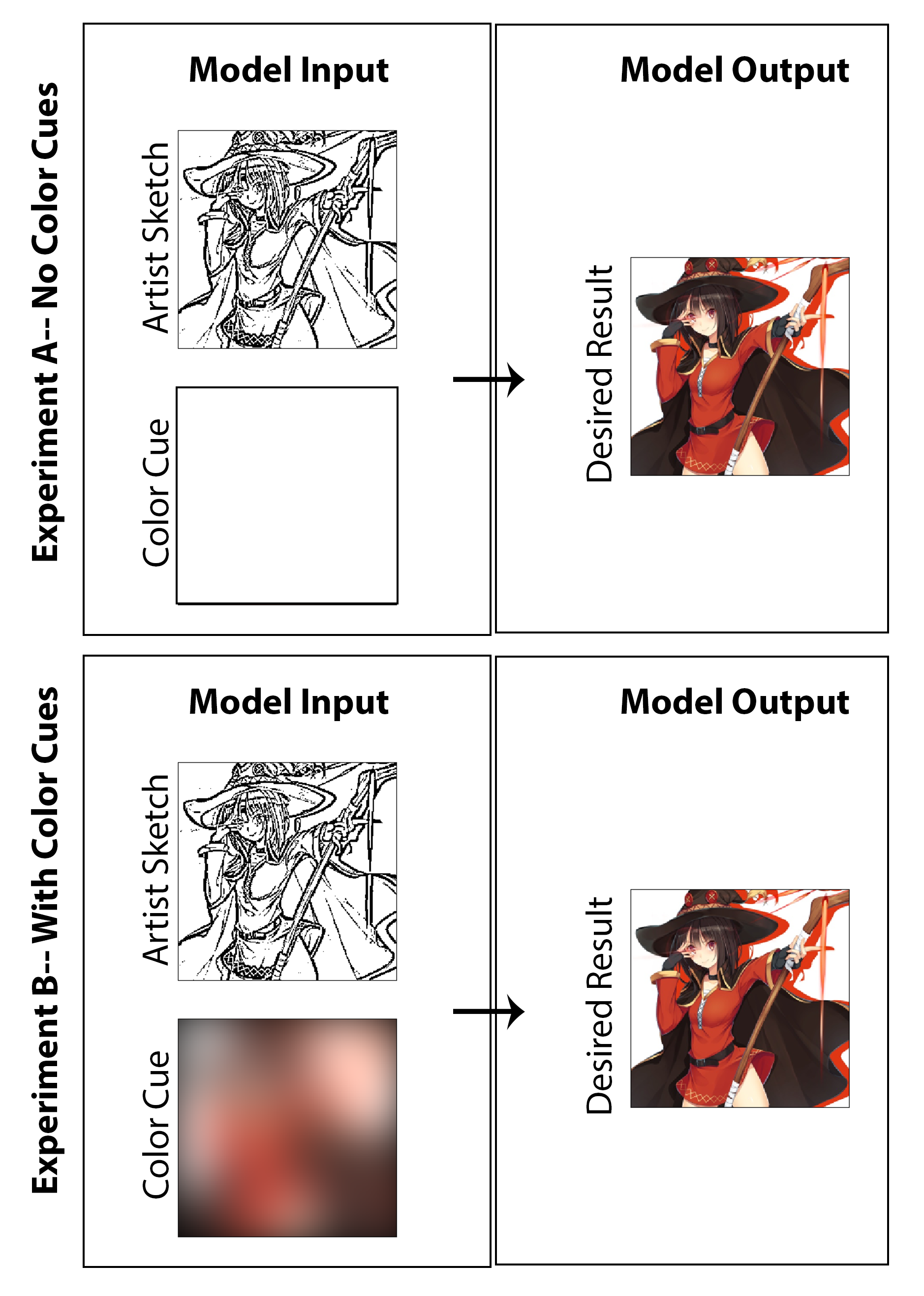

Dans ce travail, l'objectif était d'explorer si l'apprentissage en profondeur peut être utilisé afin de permettre aux artistes de mangas de créer des impressions de mangas colorisées au lieu des impressions traditionnelles en noir et blanc sans nécessiter de temps supplémentaire ou de travail significatif pour le créateur et sans nécessiter de compromis au style moyen. Alors que la plupart des résultats présentés affichent clairement les résultats de l'étude sur la colorisation de la machine, la question de l'amélioration des croquis est également subtilement sondée alors que je cherche à créer une architecture qui colorise non seulement une image mais commence par un croquis non poli et à un stade précoce dépourvu d'ombrage de qualité. Ce serait considéré comme un succès à mon avis si l'on peut commencer par une image de départ moins finale (réduisant le temps de dessin pour l'artiste) et ensuite réaliser à la fois la préservation du style, la finalisation des fonctionnalités et la colorisation complète par la mise en œuvre de notre architecture proposée. Ici, je souligne que je ne crois pas qu'une approche de colorisation non supévrieure a du sens en tant que solution du monde réel pour ce problème particulier, et en conséquence, j'ai conçu le code se concentrant sur une solution de preuve de concept qui permet à l'artiste de donner la contribution via le «reflet de couleur» utilisé pour l'image globale. Cela étant dit, j'ai également généré des résultats et une étude excluant entièrement l'entrée de l'artiste (définir les entrées de couleur à une matrice zéro et recycler le modèle) afin d'étudier dans une nature académique quels seraient les résultats. Je pense que les deux sont des enquêtes tout aussi intéressantes et amusantes qui méritent d'être présentées.
Ici, je trouve que le meilleur point de solution / point de départ pour cette tâche consiste à implémenter un réseau contradictoire conditionnel avec une architecture CNN et à se concentrer principalement sur le cadre du problème en tant que tâche de traduction d'image à image. La motivation et les conseils pour lesquels notre mise en œuvre est étroitement construite est la célèbre et appelée architecture PIX2PIX publiée fin 2016 par l'équipe d'A. EFROS au Berkley AI Research Lab.
Le modèle pour le générateur et le discriminateur utilisé dans ce travail est le même que celui rapporté dans le document PIX2PIX avec un examen des détails techniques résumés dans le PDF. Le générateur et le discriminateur utilisent des modules de la forme Convolution-Batchnorm-Relu. Pour le code connexe assemblant le générateur et le discriminateur, consultez les scripts «mainv3.py».
La première étape du processus de génération de données d'entraînement consiste à obtenir un grand ensemble d'images colorisées numériquement qui correspondent au style des mangas et de l'anime japonais. Cela se fait en fait facilement en écrivant un script Python de crampons Web qui recherche automatiquement et télécharge des images marquées du site Web d'hébergement d'imagerie, Danbooru. Ce site est idéal pour cette tâche, car il s'agit essentiellement d'un ensemble de données d'anime à grande échelle et tagué avec près de 4 millions d'images d'anime (et aurait plus de 108 millions de balises d'image, permettant un filtrage et une recherche rapides). Warring équitable: de nombreuses images de ce site ne sont sans doute pas du contenu «sûr pour le travail». En utilisant le code publié sur mon github, j'ai téléchargé environ 9000 images (à environ 1 seconde par image) avec des balises sur le thème fantastique comme «Holding Staff» et «Magic Solo». Après, ces images sont traitées en outre en python via le redimensionnement et le recadrage de telle sorte que toutes les images sont converties en 256 x 256 carrés. Cela satisfait alors la composante 1 constituant l'art manga-esque colorisé numérique de haute qualité.
Pour la dernière étape du processus de génération de données de formation, j'établit une méthode pour dériver automatiquement des indices de couleur correspondant aux images colorées. J'imagine qu'un système efficace serait pour un artiste de créer très rapidement des indices de couleur en dessinant le croquis avec de grands surligneurs de différentes couleurs. Dans le processus imaginé, ils n'auraient pas non plus besoin de se soucier de la coloration dans les lignes ou de spécifier des variations de couleur ou d'ombre. Pour approximer cela d'une manière qui pourrait être suffisante pour une implémentation de preuve de concept et sans nécessiter d'étiquetage manuel de données, je crée les indices de couleur pour chaque image en brouillant spatialement les images colorées avec un grand noyau gaussien. D'après les tests, j'ai constaté qu'un filtre gaussien avec un écart-type de 20 pixels produit qualitativement l'effet souhaité. Pour référence, cela correspond à un FWHM d'environ 50 pixels, ce qui est près de 1/5 la largeur de l'image. Trois exemples des indices de couleur dérivés de cette méthode et de leurs images colorées correspondants sont indiqués ci-dessous:

Afin d'évaluer les capacités des modèles formés pour les deux expériences de manière équitable et perspicace, je passe en revue les performances de chacune sur l'ensemble d'images de test soigneusement sélectionné. Six de ces images peuvent être vues dans les figures suivantes. Ces six images ont été choisies car elles présentent collectivement trois niveaux de difficulté différents. En tant que tel, j'ai classé les six en trois groupes appelés dans ce travail comme des «tâches» d'évaluation. Un résumé du défi prévu que chaque tâche présente est examiné après, énuméré par ordre de difficulté croissant:
La tâche de couleur:
Pour les images de cette classe, le modèle s'est entraîné sur plusieurs autres images contenant directement ces personnages bien que présentés dans une pose différente ou dessinée par un artiste différent. Cela testera les performances des cas où le modèle est bien conditionné pour formuler le problème en tant que tâche de classification et coloriser à l'aide de la reconnaissance des objets / caractères.
La tâche de transfert:
Aucune variation directe des caractères présents dans ces images de test n'a été précédemment montrée au modèle pendant la formation; Cependant, le thème global et le niveau de complexité des images dans cette tâche correspondent étroitement à celui de l'ensemble de formation. Ce test évaluera la façon dont le modèle peut effectuer une vraie traduction d'image avec une dépendance limitée à la mémorisation des caractères.
La tâche d'interpolation:
Ces images ont des valeurs de complexité bien supérieures à 20% plus élevées que le seuil de coupure défini pour l'ensemble de données de formation. Le modèle n'a également jamais vu de variation de ces caractères, ce type de style de dessin (il n'a plus de fonctionnalités similaires à l'ensemble d'anime Danbooru téléchargé), ou des images avec une densité similaire d'arêtes.
Les résultats des trois tâches d'évaluation susmentionnés sont ici affichés sur la figure [Fig: NocolorCuesResults] pour l'expérience de colorisation où aucun indice de couleur d'artiste n'est fourni au générateur et sur la figure [Fig: WithcolorCuesResults] pour l'expérience de colorisation où les indices de couleur sont fournis. Pour accentuer, le premier peut être classé comme l'approche d'apprentissage profond non surveillé tandis que le second est le supervisé.




