Deep Learning Color for Manga
1.0.0
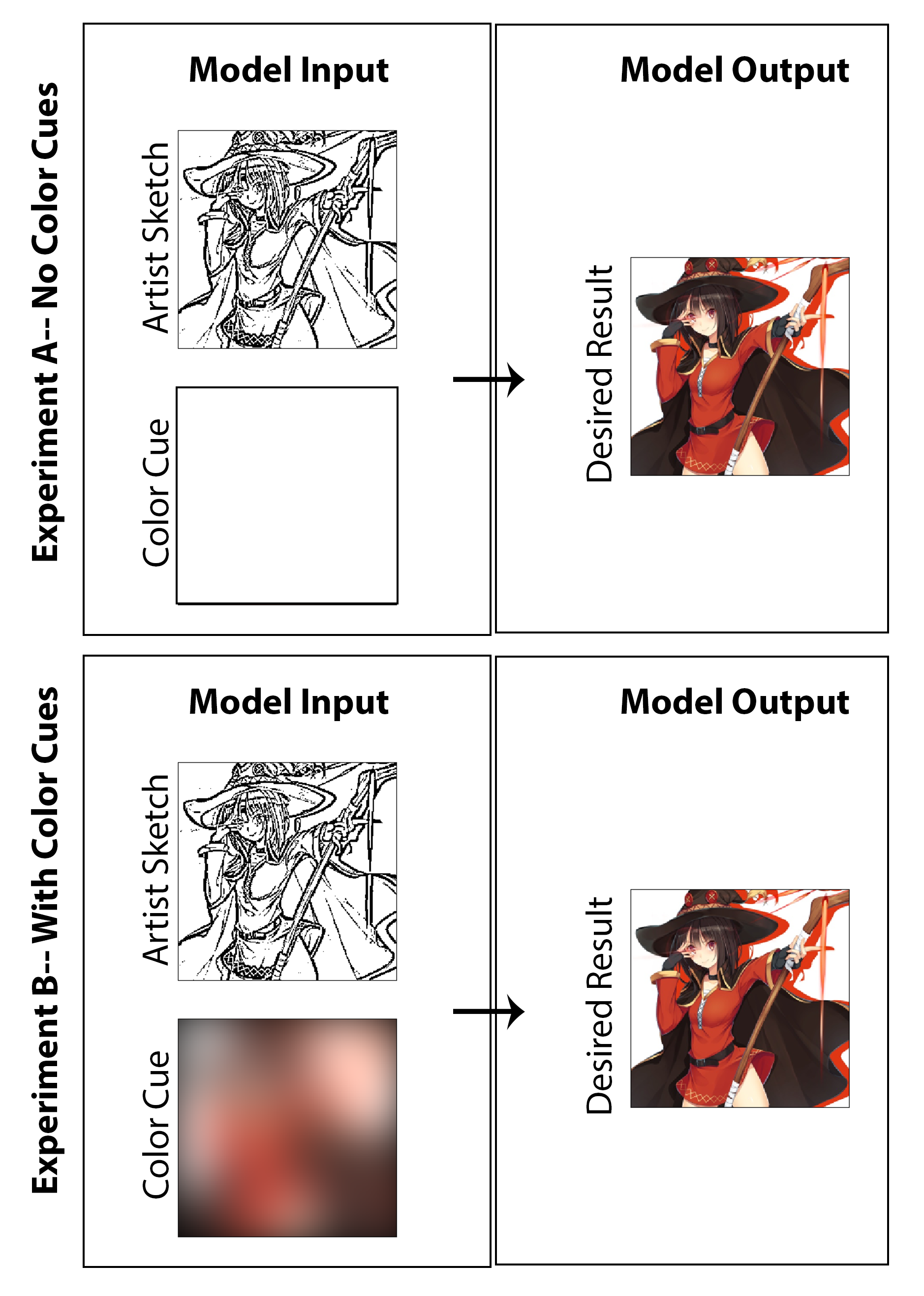

Neste trabalho, o objetivo era explorar se o aprendizado profundo puder ser empregado para permitir que os artistas de mangá criem impressões coloridas de mangá, em vez das impressões tradicionais em preto e branco, sem exigir um tempo ou trabalho extra significativo para o criador e sem exigir um compromisso ao estilo de meios. Embora muitos dos resultados mostrados mostrem claramente os resultados da investigação sobre a coloração da máquina, a questão do aprimoramento do esboço também é sutilmente sondada, pois procuro criar uma arquitetura que não apenas colorize uma imagem, mas também começa com um esboço não polido e em estágio inicial, desprovido de sombreamento de qualidade. Seria considerado um sucesso na minha opinião se pudesse começar com uma imagem inicial menos final (reduzindo o tempo de desenho para o artista) e ainda alcançar a preservação de estilos, a finalização dos recursos e a colorização total pela implementação de nossa arquitetura proposta. Aqui, destaquei que não acredito que uma abordagem de colorização não supervisionada faça sentido como uma solução do mundo real para esse problema em particular e, como resultado, projetei o código com foco em uma solução de prova de conceito que permite ao artista dar entrada através do "destaque da cor" usado para a imagem geral. Com isso dito, também gerei resultados e um estudo excluindo completamente a entrada do artista (definindo entradas de cores para uma matriz zero e reciclando o modelo) para investigar de natureza acadêmica quais seriam os resultados. Eu acho que ambos são investigações igualmente interessantes e divertidas que vale a pena apresentar.
Aqui, acho que a melhor solução/ponto de partida para esta tarefa é implementar uma rede adversária condicional com uma arquitetura da CNN e se concentrar predominantemente em enquadrar o problema como uma tarefa de tradução de imagem para imagem. A motivação e a orientação para a qual nossa implementação é de perto é a famosa e chamada arquitetura PIX2PIX lançada no final de 2016 pela equipe de A. Efros no Berkley AI Research Lab.
O modelo para o gerador e discriminador usado neste trabalho é o mesmo que o relatado no artigo PIX2PIX com uma revisão dos detalhes técnicos resumidos no PDF. Tanto o gerador quanto o discriminador utilizam módulos do formulário Convolução-Batchnorm-Relu. Para o código relacionado montando o gerador e o discriminador, consulte os scripts "Mainv3.py".
O primeiro passo no processo de geração de dados de treinamento é obter um grande conjunto de imagens coloridas digitalmente que se encaixam no estilo de mangá e anime japonês. Na verdade, isso é feito com facilidade escrevendo um script Python que pesquisa e baixa automaticamente imagens marcadas no site de hospedagem de imagens, Danbooru. Este site é ideal para esta tarefa, pois é essencialmente um conjunto de dados de anime de crowdsource em larga escala e tag com quase 4 milhões de imagens de anime (e supostamente mais de 108 milhões de tags de imagem, permitindo filtragem e pesquisa rápidas). Fair Warining: Muitas das imagens deste site não são indiscutivelmente conteúdo "seguro para o trabalho". Usando o código lançado no meu github, baixei aproximadamente 9000 imagens (a cerca de 1 segundo por imagem) com tags temáticas de fantasia como "Holding Staff" e "Magic Solo". Depois, essas imagens são processadas em Python por meio de redimensionamento e corte, de modo que todas as imagens sejam convertidas em um quadrado de 256 x 256. Isso então satisfaz o componente 1 que compõe a arte de mangá de alta qualidade e colorida digitalmente.
Para a última etapa do processo de geração de dados de treinamento, estabeleço um método para derivar automaticamente dicas de cores correspondentes às imagens coloridas. Eu imagino que um sistema eficaz seria que um artista criasse muito rapidamente dicas de cores, desenhando o esboço com grandes marcadores de cores diferentes. No processo imaginado, eles também não precisariam se preocupar em colorir nas linhas ou especificar variações de cor ou sombra. Para aproximar isso de uma maneira que possa ser suficiente para uma implementação de prova de conceito e, sem exigir nenhuma rotulagem manual de conjunto de dados, eu crio as dicas de cores para cada imagem desfocando espacialmente as imagens coloridas com um grande kernel gaussiano. A partir dos testes, descobri que um filtro gaussiano com um desvio padrão de 20 pixels produz qualitativamente o efeito desejado. Para referência, isso corresponde a um FWHM de aproximadamente 50 pixels, que é quase 1/5 da largura da imagem. Três exemplos das pistas de cores derivadas deste método e suas imagens coloridas correspondentes são mostradas abaixo:

Para avaliar os recursos dos modelos treinados para ambos os experimentos de maneira justa e perspicaz, reviso o desempenho de cada um no mesmo conjunto cuidadosamente selecionado de imagens de teste. Seis dessas imagens podem ser vistas nas figuras seguintes. Essas seis imagens foram escolhidas, pois apresentam coletivamente três níveis diferentes de dificuldade. Como tal, classifiquei os seis em três grupos mencionados neste trabalho como "tarefas" de avaliação. Um resumo do desafio previsto que cada tarefa apresenta é revisada seguindo, listada em uma ordem crescente de dificuldade:
A tarefa de cor:
Para imagens nesta classe, o modelo treinou em várias outras imagens que contêm diretamente esses personagens, embora apresentados em uma pose diferente ou desenhados por um artista diferente. Isso testará o desempenho dos casos em que o modelo é bem condicionado para formular o problema como uma tarefa de classificação e colorizar com o auxílio do reconhecimento de objeto/caractere.
A tarefa de transferência:
Nenhuma variação direta dos caracteres presentes nessas imagens de teste foi mostrada anteriormente ao modelo durante o treinamento; No entanto, o tema geral e o nível de complexidade das imagens nesta tarefa correspondem de perto ao do conjunto de treinamento. Este teste avaliará o quão bem o modelo pode executar a verdadeira tradução da imagem com dependência limitada da memorização do personagem.
A tarefa de interpolação:
Essas imagens têm valores de complexidade bem mais de 20% mais altos que o limite de corte definido para o conjunto de dados de treinamento. O modelo também nunca viu nenhuma variação desses caracteres, esse tipo de estilo de desenho (não possui mais recursos semelhantes ao conjunto de anime Danbooru baixado) ou imagens com uma densidade semelhante de arestas.
Os resultados das três tarefas de avaliação acima mencionados são aqui exibidos na Figura [Fig: NocolorcuesResults] para o experimento de colorização, onde nenhuma dica de cor de artista é fornecida ao gerador e na figura [Fig: WithcolorcuesResults] para o experimento de colorização onde são fornecidas cores de cor. Para ênfase, o primeiro pode ser classificado como a abordagem de aprendizado profundo sem supervisão, enquanto o último é o supervisionado.




