Deep Learning Color for Manga
1.0.0
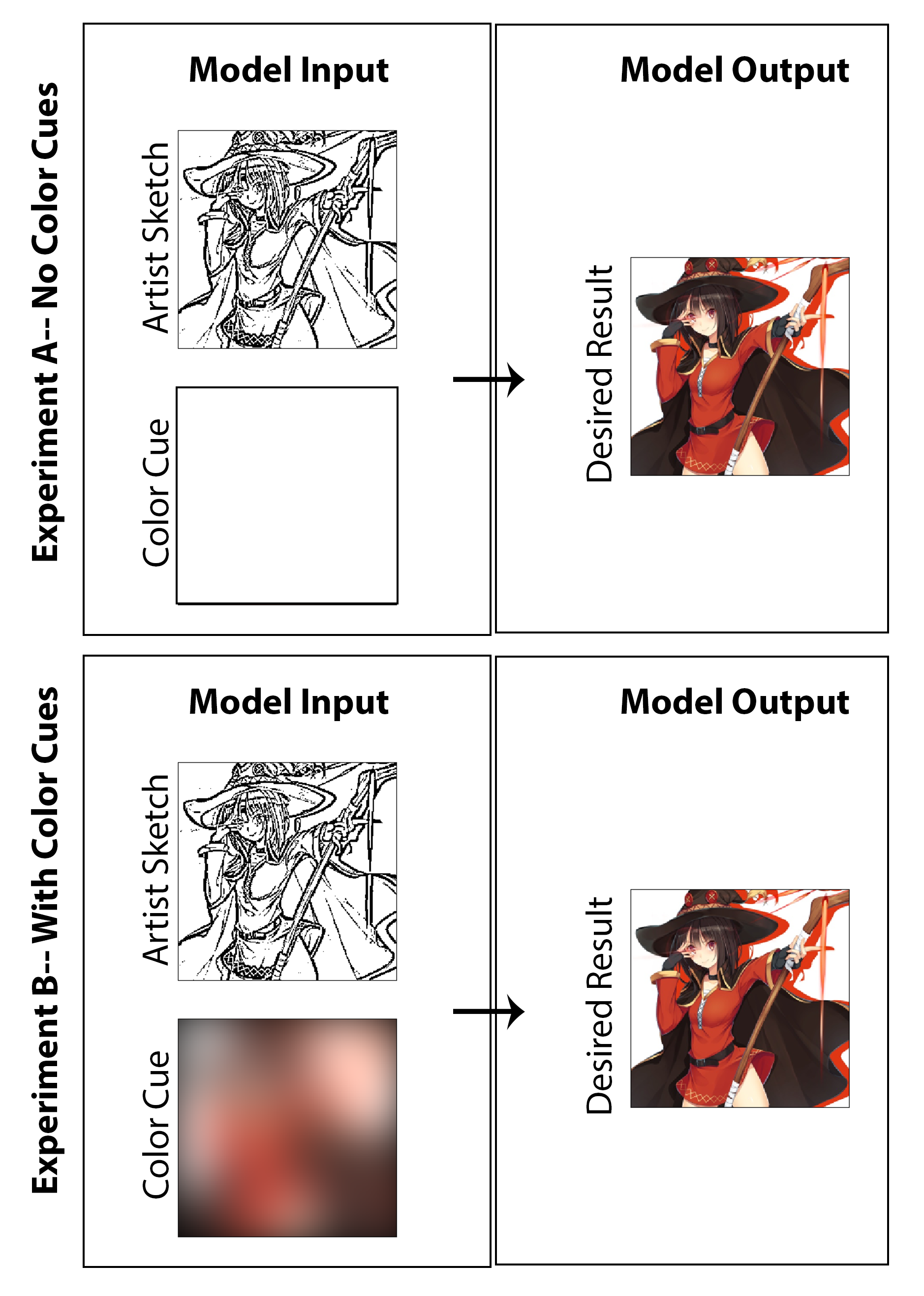

在这项工作中,目标是探索是否可以采用深度学习,以使漫画艺术家能够创建有色的漫画印刷品,而不是传统的黑白印刷品,而无需为创建者提供大量额外的时间或工作,而无需对媒介风格造成损害。虽然显示的许多结果清楚地显示了对机器着色的调查结果,但当我寻求创建一个不仅为图像上色的体系结构,而且从未经抛光的早期阶段素描没有优质阴影开始时,还概述了草图增强的问题。我认为,如果一个人可以从最终的启动图像开始(为艺术家减少绘图时间),那么这将被认为是成功的,然后通过实现我们所提出的架构来实现样式保存,功能最终确定和全面着色。在这里,我强调的是,我不认为一种无监督的着色方法是解决此特定问题的现实解决方案是有意义的,因此,我设计了专注于概念验证解决方案的代码,该解决方案允许艺术家通过用于整体图像的“色彩亮点”提供输入。话虽这么说,我还产生了结果和一项研究,不包括艺术家的输入(将颜色输入设置为零matrix并重新训练模型),以便在学术性质中调查结果。 I think both are equally interesting and amusing investigations worth presenting.
在这里,我发现此任务的最佳解决方案/起点是实现具有CNN体系结构的条件对抗网络,并主要集中于将问题作为图像到图像的翻译任务。我们的实施构建的动机和指导是A. Efros团队在Berkley AI研究实验室于2016年底发布的著名的,所谓的Pix2Pix架构。
这项工作中使用的生成器和歧视器的模型与PIX2PIX论文中报道的模型相同,并回顾了PDF中总结的技术细节。 Both the generator and discriminator utilizes modules of the form convolution-BatchNorm-ReLu. For the related code assembling the generator and discriminator, see the scripts “mainv3.py".
培训数据生成过程的第一步是获得一套适合日本漫画和动漫风格的数字色彩图像。实际上,通过编写一个网络搭配的Python脚本可以轻松完成,该脚本自动从成像托管网站Danbooru中自动搜索和下载带标记的图像。该站点是此任务的理想选择,因为它本质上是一个大规模的众包,并标记了具有近400万本动漫图像的动漫数据集(据报道,总计超过1.08亿个图像标签,可以快速过滤和搜索)。 Fair Warining: many of the images on this site are arguably not “safe-for-work” content.使用GitHub上发布的代码,我下载了大约9000张图像(每张图像约1秒),并使用幻想主题标签(例如“ Holding Weaster”和“ Magic Solo”)下载。 After, these images are further processed in python via resizing and cropping such that all images are converted to a 256 x 256 square. This then satisfies component 1 making up the high-quality, digitally colorized manga-esque art.
对于训练数据生成过程的最后一步,我建立了一种自动得出与彩色图像相对应的颜色提示的方法。我想一个有效的系统将使艺术家通过用大量不同颜色的荧光笔在草图上绘制草图来快速创建颜色提示。 In the imagined process, they would also need not worry about coloring within the lines or specifying variations in color or shade.为了以一种可能足以实现概念验证实现且不需要任何手动数据集标签的方式进行近似,我通过用大型高斯内核使彩色图像模糊彩色图像来为每个图像创建颜色提示。 From testing, I found that a Gaussian filter with a standard deviation of 20 pixels qualitatively produces the desired effect. For reference, this corresponds to a FWHM of approximately 50 pixels which is nearly 1/5 the width of the image. Three examples of the color cues derived from this method and their corresponding colored images are shown in below:

为了以公平而有见地的方式评估两个实验的训练模型的功能,我在相同的,精心选择的测试图像集上回顾了每个实验的性能。 Six of these images can be seen in the figures following. These six images were chosen as they collectively present three different levels of difficulty. As such, I have classified the six into three groups referred to in this work as evaluation “tasks”. A summary of the anticipated challenge each task presents is reviewed following, listed in increasing order of difficulty:
The Color Task:
对于此类的图像,该模型已经对其他几个直接包含这些字符的图像进行了训练,尽管以不同的姿势或由其他艺术家绘制。这将测试对模型有充分条件以将问题作为分类任务提出问题的情况的性能,并借助对象/角色识别。
The Transfer Task:
No direct variation of the characters present in these test images have been previously shown to the model during training; however, the overall theme and complexity level of images in this task closely match that of the training set. This test will evaluate how well the model can perform true image translation with limited reliance on character memorization.
The Interpolation Task:
These images have complexity values well over 20% higher than the cutoff threshold defined for the training data set.该模型也从未见过这些字符的任何变化,这种类型的绘图样式(它不再具有类似于下载的Danbooru动漫集的功能),或具有相似边缘密度的图像。
上述三个评估任务的结果显示在图[图:nocolorcuesresults]中,用于着色实验,其中为发电机和图[图:withColorcuesResults]提供了为色彩提示提供的色彩学实验。 For emphasis, the former can be classified as the unsupervised deep-learning approach while the latter is the supervised.




