Deep Learning Color for Manga
1.0.0
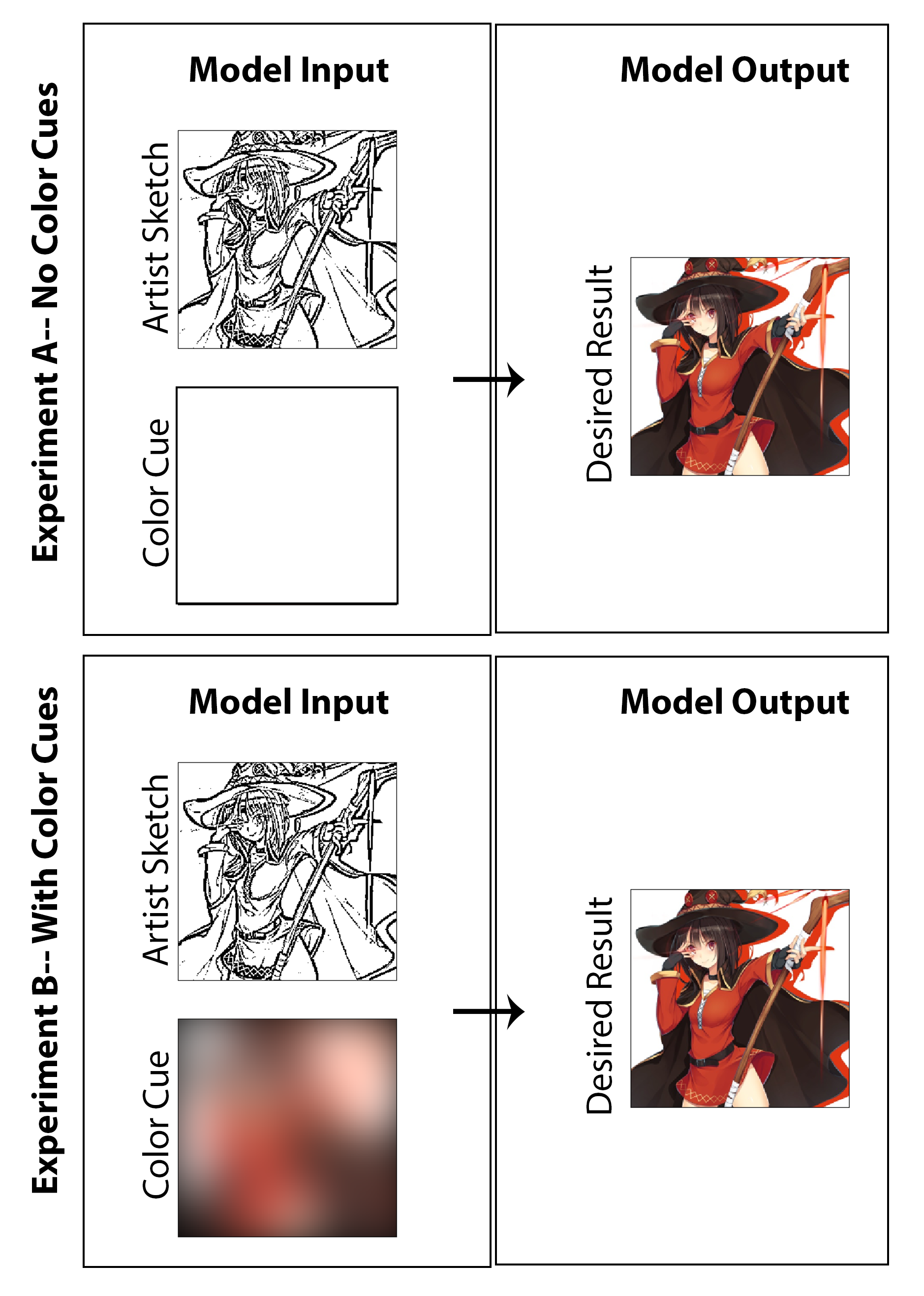

في هذا العمل ، كان الهدف هو استكشاف ما إذا كان يمكن توظيف التعلم العميق من أجل تمكين فنانين المانجا من إنشاء مطبوعات مانجا الملونة بدلاً من المطبوعات التقليدية بالأبيض والأسود دون الحاجة إلى وقت أو عمل إضافي كبير للمبدع ودون طلب حل وسط لأسلوب الوسائط. على الرغم من أن الكثير من النتائج المعروضة تعرض بوضوح نتائج التحقيق في تلوين الماكينة ، إلا أن مسألة تعزيز الرسم يتم التحقيق بها أيضًا بمهارة حيث أسعى إلى إنشاء بنية لا تُلوين الصورة فحسب ، بل تبدأ برسم مرحلة مبكرة غير مصقول خالية من تظليل الجودة. سيعتبر نجاحًا في رأيي ما إذا كان يمكن للمرء أن يبدأ بصورة البداية النهائية (تقليل وقت الرسم للفنان) وما زال يحقق كل من الحفاظ على الأسلوب ، والانتهاء الميزات واللون الكامل عن طريق تنفيذ بنيةنا المقترحة. هنا ، أنا أبرز أنني لا أعتقد أن نهج اللون غير الخاضع للإشراف أمر منطقي كحل حقيقي لهذه المشكلة بالذات ، ونتيجة لذلك ، قمت بتصميم الكود الذي يركز على حل إثبات المفهوم الذي يسمح للفنان بإعطاء الإدخال عبر "تسليط الضوء على اللون" المستخدم للصورة الإجمالية. مع ما يقال ، قمت أيضًا بإنشاء نتائج ودراسة باستثناء إدخال الفنان تمامًا (تعيين مدخلات اللون على مصفوفة صفرية وإعادة تدريب النموذج) من أجل التحقيق في الطبيعة الأكاديمية التي ستكون النتائج. أعتقد أن كلاهما مثيرة للاهتمام ومسلية على حد سواء تحقيقات تستحق تقديمها.
هنا ، أجد أن أفضل حلول/نقطة انطلاق لهذه المهمة هي تنفيذ شبكة عدوانية مشروطة مع بنية CNN والتركيز في الغالب على تأطير المشكلة كمهمة ترجمة صورة إلى صورة. الدافع والإرشادات التي تم تصميمها من أجل تنفيذنا عن كثب هي بنية PIX2PIX الشهيرة التي تم إصدارها في أواخر عام 2016 من قبل فريق A. Efros في مختبر Berkley AI Research Lab.
نموذج المولد والتمييز المستخدم في هذا العمل هو نفسه الذي تم الإبلاغ عنه في ورقة PIX2PIX مع مراجعة للتفاصيل الفنية الملخصة في PDF. يستخدم كل من المولد والتمييز وحدات النموذج من النموذج الالتصاق بالمدرس. للاطلاع على الكود ذي الصلة تجميع المولد والتمييز ، راجع البرامج النصية "mainv3.py".
تتمثل الخطوة الأولى في عملية توليد بيانات التدريب في الحصول على مجموعة كبيرة من الصور الملونة رقميًا تتناسب مع نمط المانجا الياباني والأنيمي. يتم القيام بذلك بسهولة بسهولة عن طريق كتابة برنامج نصي Python الذي يقوم بتنسيق ويب يبحث تلقائيًا وتنزيل الصور الموسومة من موقع استضافة التصوير ، Danbooru. يعد هذا الموقع مثاليًا لهذه المهمة نظرًا لأنه في الأساس مجموعة بيانات أنيمي على نطاق واسع وموسومة مع ما يقرب من 4 ملايين صورة أنيمي (ويقال إن أكثر من 108 مليون صورة صورة تسمح بالتصفية السريعة والبحث). Fair Warining: يمكن القول إن العديد من الصور الموجودة على هذا الموقع ليست محتوى "آمنًا مقابل العمل". باستخدام الرمز الذي تم إصداره على GitHub ، قمت بتنزيل ما يقرب من 9000 صورة (في حوالي ثانية واحدة لكل صورة) مع علامات خيالية مثل "Holding Smooth" و "Magic Solo". بعد ذلك ، تتم معالجة هذه الصور في بيثون من خلال تغيير حجمها وزراعة المحاصيل بحيث يتم تحويل جميع الصور إلى 256 × 256 مربعًا. هذا بعد ذلك يرضي المكون 1 يشكل فن المانجا ذو الجودة العالية والملونة رقميًا.
بالنسبة للخطوة الأخيرة في عملية توليد بيانات التدريب ، أقوم بإنشاء طريقة لاستخلاص إشارات الألوان تلقائيًا المقابلة للصور الملونة. أتصور أن نظامًا فعالًا سيكون للفنان أن يخلق إشارات ملونة بسرعة كبيرة عن طريق الرسم على الرسم مع أبراج كبيرة من ألوان مختلفة. في العملية المتخيلة ، لن تحتاج أيضًا إلى القلق بشأن التلوين داخل الخطوط أو تحديد الاختلافات في اللون أو الظل. لتقريب هذا بطريقة يمكن أن تكون كافية لتنفيذ إثبات المفهوم ودون طلب أي علامات على مجموعة بيانات يدوي ، أقوم بإنشاء إشارات الألوان لكل صورة عن طريق وضوح الصور الملونة مكانيًا مع نواة غوسية كبيرة. من الاختبار ، وجدت أن مرشح غاوسي مع انحراف معياري يبلغ 20 بكسل ينتج نوعيًا التأثير المطلوب. للإشارة ، هذا يتوافق مع FWHM حوالي 50 بكسل وهو ما يقرب من 1/5 عرض الصورة. ثلاثة أمثلة على إشارات الألوان المستمدة من هذه الطريقة وترد صورها الملونة المقابلة في أدناه:

من أجل تقييم قدرات النماذج المدربة لكلتا التجربتين بطريقة عادلة ورائعة ، أقوم بمراجعة أداء كل منها على نفس مجموعة صور الاختبار المختارة بعناية. ستة من هذه الصور يمكن رؤية في الأرقام التالية. تم اختيار هذه الصور الست لأنها تقدم مجتمعة ثلاثة مستويات مختلفة من الصعوبة. على هذا النحو ، قمت بتصنيف الستة إلى ثلاث مجموعات المشار إليها في هذا العمل على أنه "المهام". تتم مراجعة ملخص للتحدي المتوقع الذي تقدمه كل مهمة متابعة ، مدرجة بترتيب متزايد من الصعوبة:
مهمة اللون:
بالنسبة للصور في هذا الفصل ، تدرب النموذج على العديد من الصور الأخرى التي تحتوي مباشرة على هذه الأحرف على الرغم من أنها تم تقديمها في شكل مختلف أو رسمها فنان مختلف. سيؤدي ذلك إلى اختبار الأداء للحالات التي يكون فيها النموذج مكيفًا جيدًا لصياغة المشكلة كمهمة تصنيف وتلوين مع مساعدة من التعرف على الكائن/الأحرف.
مهمة النقل:
لم يتم عرض أي تباين مباشر للأحرف الموجودة في صور الاختبار هذه سابقًا للنموذج أثناء التدريب ؛ ومع ذلك ، فإن الموضوع العام ومستوى التعقيد للصور في هذه المهمة يتطابق بشكل وثيق مع مجموعة التدريب. سيقوم هذا الاختبار بتقييم مدى جودة أداء النموذج إلى ترجمة الصورة الحقيقية مع الاعتماد المحدود على حفظ الأحرف.
مهمة الاستيفاء:
هذه الصور لها قيم تعقيد أعلى بكثير من 20 ٪ من عتبة القطع المحددة لمجموعة بيانات التدريب. لم ير النموذج أبدًا أي اختلاف في هذه الأحرف ، هذا النوع من نمط الرسم (لم يعد يحتوي على ميزات مشابهة لمجموعة أنيمي Danbooru التي تم تنزيلها) ، أو الصور بكثافة مماثلة من الحواف.
يتم عرض نتائج مهام التقييم الثلاث المذكورة أعلاه في الشكل [الشكل: NocolorCuesResults] لتجربة تلوين حيث لا يتم توفير إشارات ملونة فنان إلى المولد وفي الشكل [الشكل: withColorCuesResults] لتجربة تلوين حيث يتم توفير العظة الملونة. من أجل التركيز ، يمكن تصنيف الأول على أنه نهج التعلم العميق غير الخاضع للإشراف بينما يكون الأخير هو الخاضع للإشراف.




