LiveCodeBench
1.0.0
該論文的官方存儲庫“ livecodebench:大型語言模型的整體和污染免費評估”
?主頁•數據•?排行榜
LiveCodeBench提供了LLMS的編碼功能的整體和無污染評估。特別是,LiveCodebench不斷從三個競爭平台(Leetcode,atcoder和codeforces)的比賽中不斷收集新問題。接下來,LiveCodeBench還專注於更廣泛的代碼相關功能,例如自我修復,代碼執行和測試輸出預測,而不是代碼生成。目前,LiveCodebench在2023年5月至2024年3月之間發表了四百個高質量的編碼問題。
您可以使用以下命令克隆存儲庫:
git clone https://github.com/LiveCodeBench/LiveCodeBench.git
cd LiveCodeBench我們建議使用詩歌來管理依賴關係。您可以使用以下命令安裝詩歌和依賴項:
pip install poetry
poetry install默認設置不安裝vllm 。要安裝vllm ,您可以使用:
poetry install --with with-gpu我們為不同的代碼功能方案提供基準
由於LiveCodeBench是一個不斷更新的基準,因此我們提供了數據集的不同版本。特別是,我們提供數據集的以下版本:
release_v1 :數據集的初始版本,其中包含400個問題的2023年5月至2024年3月之間發布的問題。release_v2 :數據集的更新版本,其中包含511個問題的2023年5月至2024年5月之間發布的問題。release_v3 :數據集的更新版本,其中包含612個問題的2023年5月至2024年7月之間發布的問題。release_v4 :數據集的更新版本,其中包含713個問題的2023年5月至2024年9月之間發布的問題。您可以使用--release_version標誌來指定要使用的數據集版本。特別是,您可以使用以下命令在release_v2數據集上運行評估。發行版本默認為release_latest 。
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration --evaluate --release_version release_v2我們使用vllm使用開放模型進行推斷。默認情況下,我們使用tensor_parallel_size=${num_gpus}在所有可用的GPU上並行推理。可以根據需要使用--tensor_parallel_size標誌進行配置。
要運行推理,請根據./lcb_runner/lm_styles.py文件提供model_name 。場景(此處codegeneration )可用於指定模型的方案。
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration此外,可以使用--use_cache標誌來緩存生成的輸出, --continue_existing標誌可用於使用現有的轉儲結果。如果您希望從本地路徑使用模型,則可以提供模型路徑的--local_model_path標誌。我們使用n=10 , temperature=0.2進行生成。請檢查./lcb_runner/runner/parser.py文件以獲取有關標誌的更多詳細信息。
對於封閉的API模型,可以使用--multiprocess Flag將查詢與API服務器並行化(可根據速率限制調節)。
我們計算pass@1 ,並pass@5指標進行模型評估。我們使用使用apps基準發布的Checker的修改版本來計算指標。特別是,我們確定了原始檢查器中的一些未經處理的邊緣案例,並根據收集的數據集修復了檢查器,並簡化了檢查器。要運行評估,您可以添加--evaluate標誌:
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration --evaluate請注意,時間限制可能會導致pass@1和pass@5指標的通行證計算中的輕微( < 0.5 )點。如果您觀察到性能的顯著差異,請將--num_process_evaluate標誌調整為較低的值或增加--timeout標誌。請在此處報告由於超時不當而引起的特定問題。
最後,要獲得不同時間窗口的分數,您可以使用./lcb_runner/evaluation/compute_scores.py文件。特別是,您可以提供--start_date和--end_date標誌(使用YYYY-MM-DD格式)以在指定的時間窗口上獲得分數。在我們的論文中,為了應對DeepSeek模型的污染,我們僅報告2023年8月以後發布的問題的結果。您可以使用以下方式複制這些評估。
python -m lcb_runner.evaluation.compute_scores --eval_all_file {saved_eval_all_file} --start_date 2023-09-01注意:我們已經從原始基準測試了大量測試用例,並創建了code_generation_lite ,該測試用例設置為默認基準標準,可更快地提供相似的性能估計。如果您想使用原始基準測試,請使用--not_fast標誌。我們正在使用此更新設置更新排行榜分數。
注意:V2更新:要運行更新LiveCodeBench,請使用--release_version release_v2 。此外,如果您具有release_v1的現有結果,則可以添加--continue_existing或更好--continue_existing_with_eval flags以分別重複使用舊的完成或評估。
為了進行自我維修,您需要提供一個額外的--codegen_n標誌,該標誌映射到代碼生成過程中生成的代碼數量。此外, --temperature標誌用於解決必須在output目錄中存在的舊代碼生成評估文件。
python -m lcb_runner.runner.main --model {model_name --scenario selfrepair --codegen_n {num_codes_codegen} --n 1 # only n=1 supported如果您在基準的較小子集或版本上具有結果,則可以使用--continue_existing和--continue_existing_with_eval flags重複使用舊計算。特別是,您可以運行以下命令以從現有生成的解決方案中繼續。
python -m lcb_runner.runner.main --model {model_name} --scenario selfrepair --evaluate --continue_existing請注意,這只會重複使用生成的樣本和重新評估。要重複使用舊評估,您可以添加--continue_existing_with_eval標誌。
對於運行測試輸出預測方案,您可以簡單地運行
python -m lcb_runner.runner.main --model {model_name} --scenario testoutputprediction --evaluate對於運行測試輸出預測方案,您可以簡單地運行
python -m lcb_runner.runner.main --model {model_name} --scenario codeexecution --evaluate此外,我們支持COT設置
python -m lcb_runner.runner.main --model {model_name} --scenario codeexecution --cot_code_execution --evaluate另外,您可以使用lcb_runner/runner/custom_evaluator.py直接評估自定義文件中的模型世代。該文件應包含一個模型輸出列表,該列表以基準問題的順序進行標準的格式進行評估。
python -m lcb_runner.runner.custom_evaluator --custom_output_file {path_to_custom_outputs}特別是以以下格式排列輸出
[
{ "question_id" : " id1 " , "code_list" : [ " code1 " , " code2 " ]},
{ "question_id" : " id2 " , "code_list" : [ " code1 " , " code2 " ]}
]為了增加對新模型的支持,我們已經實施了一個可擴展的框架來添加新模型並自定義提示。
步驟1:將新模型添加到./lcb_runner/lm_styles.py文件中。特別是,擴展LMStyle類以添加新的模型家族並將模型擴展到LanguageModelList陣列。
步驟2:由於我們使用指令調整模型,因此我們允許為每個模型配置指令。修改./lcb_runner/prompts/generation.py文件以在format_prompt_generation函數中為模型添加新提示。例如, DeepSeekCodeInstruct模型系列的提示如下
# ./lcb_runner/prompts/generation.py
if LanguageModelStyle == LMStyle . DeepSeekCodeInstruct :
prompt = f" { PromptConstants . SYSTEM_MESSAGE_DEEPSEEK } n n "
prompt += f" { get_deepseekcode_question_template_answer ( question ) } "
return prompt 要將模型提交給排行榜,您可以填寫此表格。您將需要填寫模型詳細信息,並為生成的評估文件提供模型世代,並通過@1分。我們將審查提交並相應地將模型添加到排行榜中。
我們在errata.md文件中維護已知問題和更新的列表。特別是,我們記錄了有關錯誤測試和不適合自動化的問題的問題。當我們更新LiveCodeBench時,我們一直在使用此反饋來改善問題選擇啟發式方法。
LiveCodeBench可用於評估不同時間播放的LLM的性能(使用問題發布日期來過濾模型)。因此,我們可以在評估過程中檢測和防止潛在的污染,並在新問題上評估LLM。
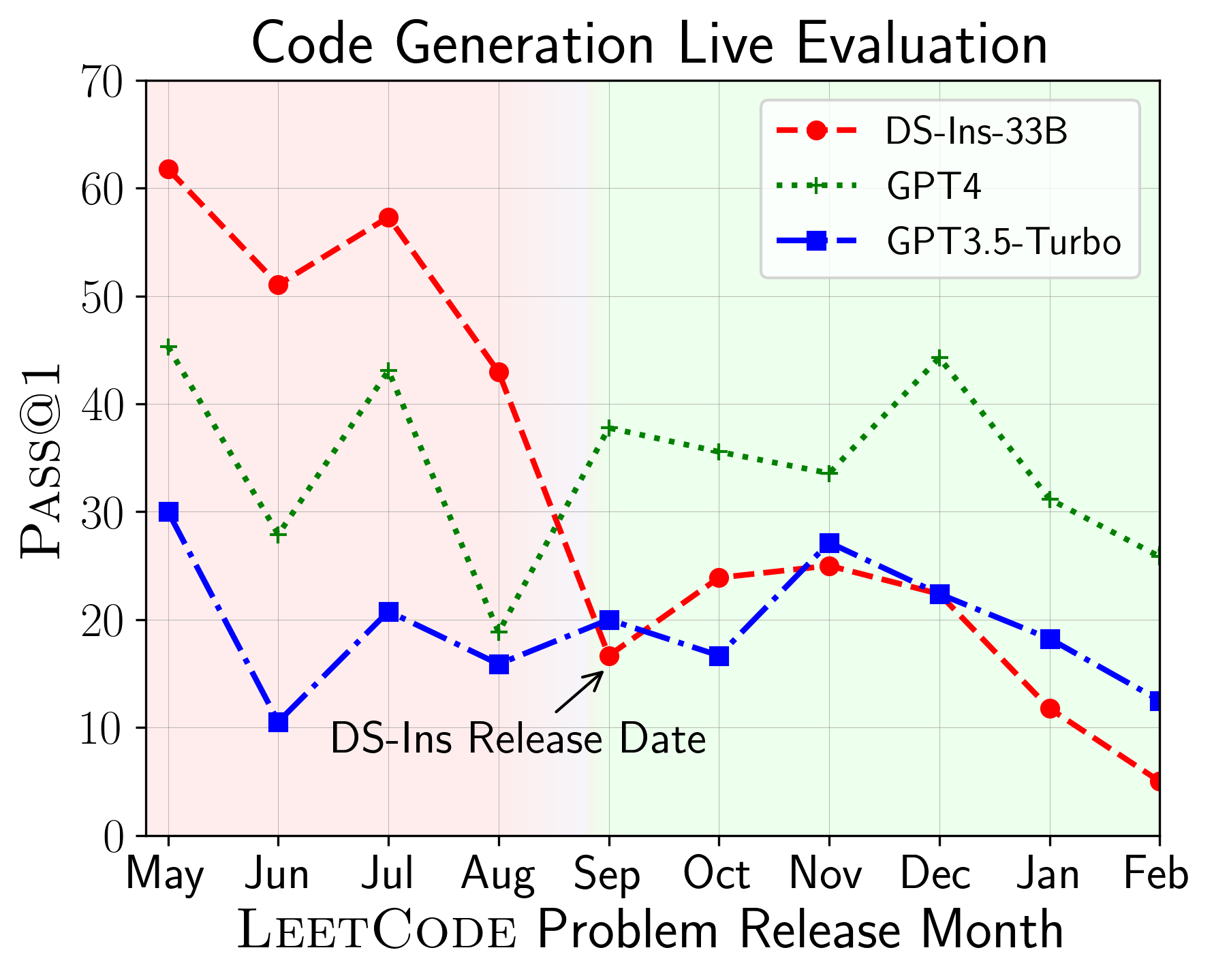
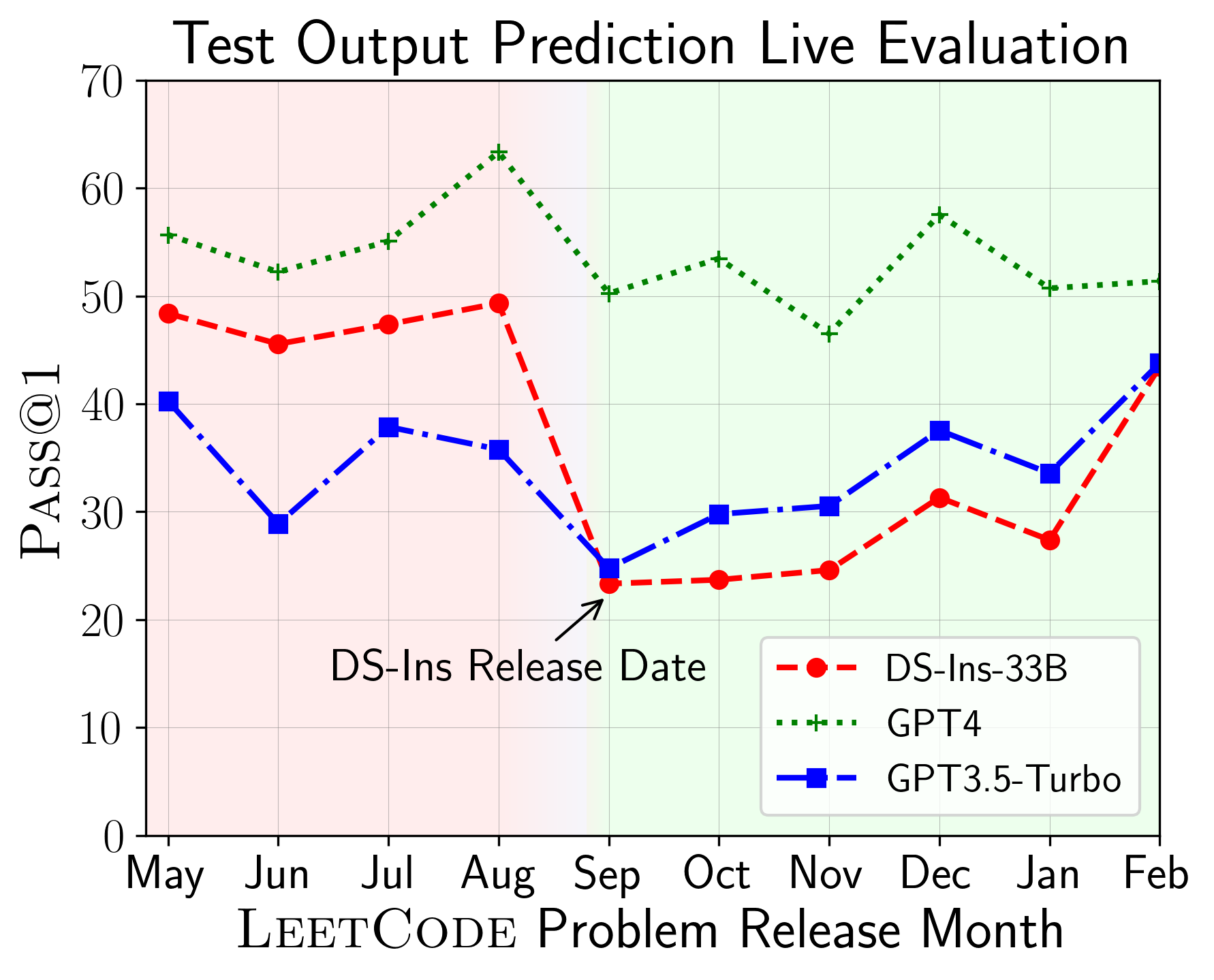
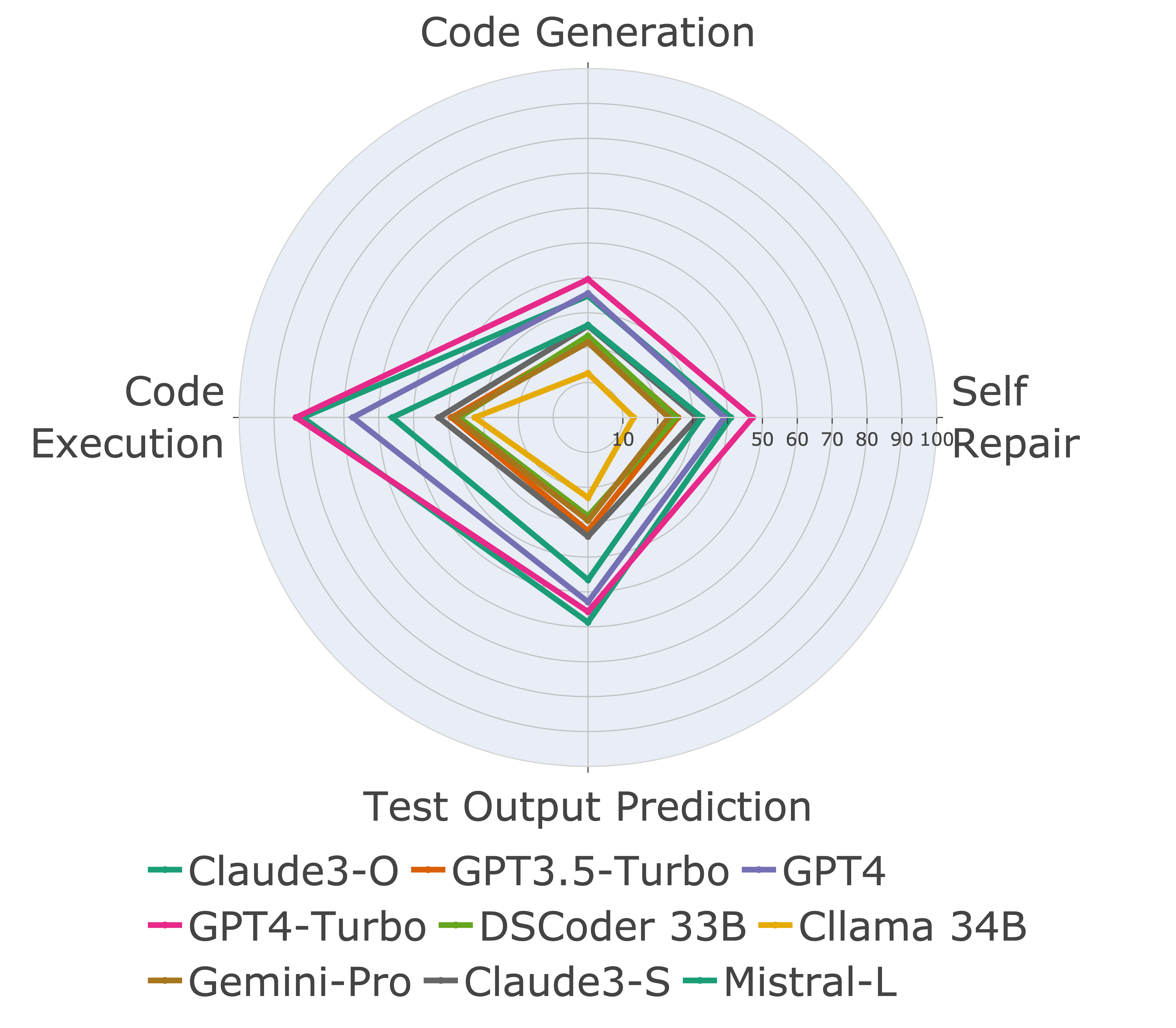
接下來,我們對不同代碼功能進行評估模型,並發現模型的相對性能確實在任務上發生了變化(左)。因此,它強調了對代碼LLM的整體評估的需求。
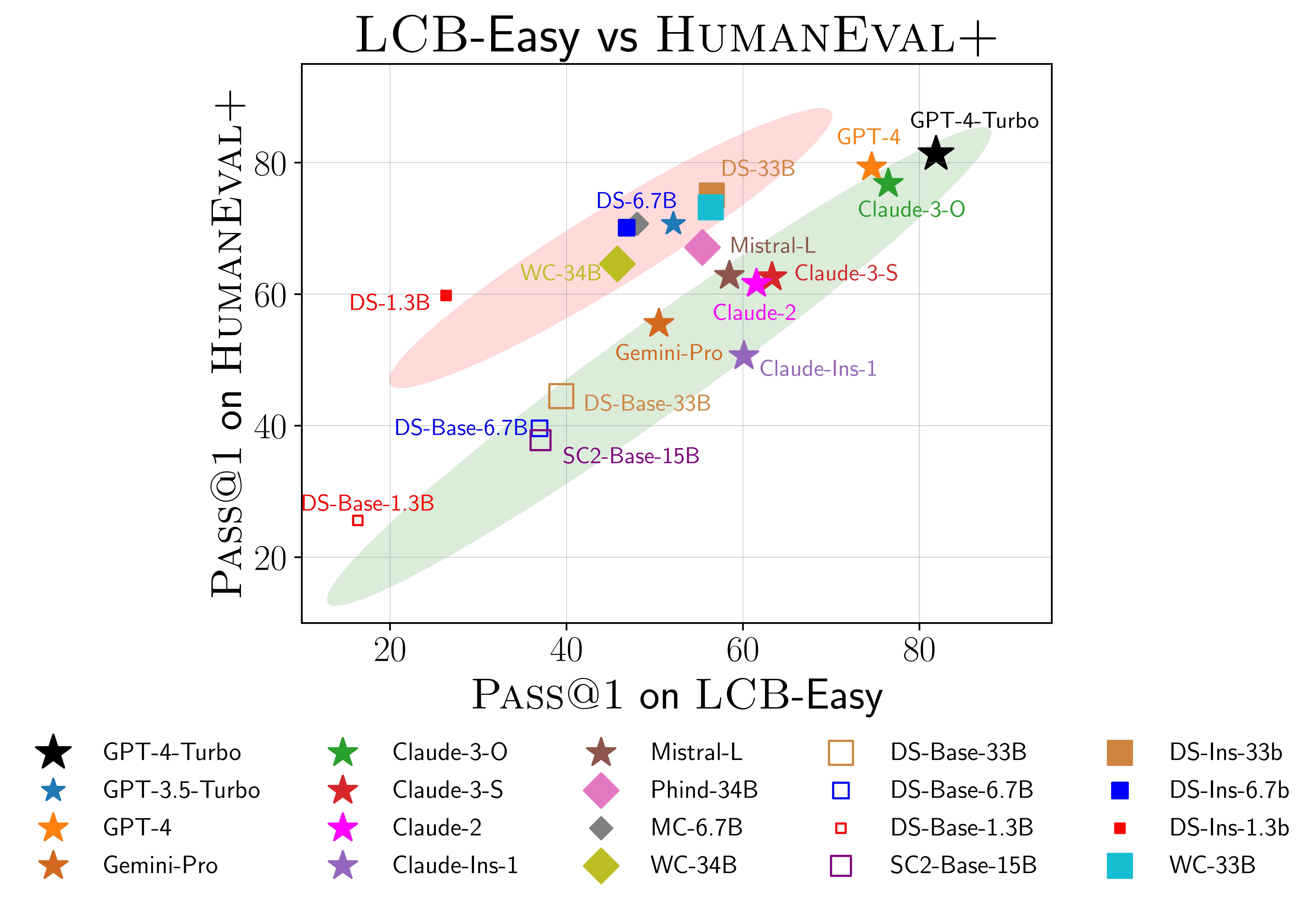
我們還發現證據表明人類事件(Righaneval)可能過度擬合(右)。特別是,在人類事件上表現良好的模型不一定在livecodebench上表現良好。在上面的散點圖中,我們發現模型被聚集成兩組,以紅色和綠色為陰影。紅色組包含在人類事件上表現良好但在livecodebench上表現不佳的模型,而綠色組則包含在兩者效果良好的模型。
有關更多詳細信息,請參閱我們的網站livecodebench.github.io。
@article { jain2024livecodebench ,
author = { Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, Ion Stoica } ,
title = { LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code } ,
year = { 2024 } ,
journal = { arXiv preprint } ,
}

