LiveCodeBench
1.0.0
Repositório oficial do artigo "LivecodeBench: Avaliação Holística e Free de Contaminação de Modelos de Língua grandes para Código"
? Página inicial • Dados •? Tabela de classificação
O LiveCodeBench fornece uma avaliação holística e sem contaminação dos recursos de codificação do LLMS. Particularmente, o LivecodeBench coleta continuamente novos problemas ao longo do tempo de concursos em três plataformas de competição - LeetCode, Atcoder e Codeforces. Em seguida, o LivecodeBench também se concentra em uma gama mais ampla de recursos relacionados ao código, como auto-reparação, execução de código e previsão de saída de teste, além de apenas geração de código. Atualmente, o LivecodeBench hospeda quatrocentos problemas de codificação de alta qualidade que foram publicados entre maio de 2023 e março de 2024.
Você pode clonar o repositório usando o seguinte comando:
git clone https://github.com/LiveCodeBench/LiveCodeBench.git
cd LiveCodeBenchRecomendamos o uso de poesia para gerenciar dependências. Você pode instalar a poesia e as dependências usando os seguintes comandos:
pip install poetry
poetry install A configuração padrão não instala vllm . Para instalar vllm também, você pode usar:
poetry install --with with-gpuFornecemos uma referência para diferentes cenários de capacidade de código
Como o LivecodeBench é um benchmark continuamente atualizado, fornecemos versões diferentes do conjunto de dados. Particularmente, fornecemos as seguintes versões do conjunto de dados:
release_v1 : a versão inicial do conjunto de dados com problemas divulgados entre maio de 2023 e março de 2024, contendo 400 problemas.release_v2 : A versão atualizada do conjunto de dados com problemas divulgados entre maio de 2023 e maio de 2024 contendo 511 problemas.release_v3 : A versão atualizada do conjunto de dados com problemas divulgados entre maio de 2023 e julho de 2024 contendo 612 problemas.release_v4 : a versão atualizada do conjunto de dados com problemas divulgados entre maio de 2023 e setembro de 2024, contendo 713 problemas. Você pode usar o sinalizador --release_version para especificar a versão do conjunto de dados que deseja usar. Particularmente, você pode usar o seguinte comando para executar a avaliação no conjunto de dados release_v2 . Liberar a versão padrão para release_latest .
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration --evaluate --release_version release_v2 Usamos vllm para inferência usando modelos abertos. Por padrão, usamos tensor_parallel_size=${num_gpus} para paralelizar a inferência em todas as GPUs disponíveis. Ele pode ser configurado usando o sinalizador --tensor_parallel_size conforme necessário.
Para executar a inferência, forneça o model_name com base no arquivo ./lcb_runner/lm_styles.py. O cenário (aqui codegeneration ) pode ser usado para especificar o cenário para o modelo.
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration Além disso, o sinalizador --use_cache pode ser usado para armazenar em cache as saídas geradas e --continue_existing sinalizador pode ser usado para usar os resultados despejados existentes. Caso você queira usar o modelo de um caminho local, também pode fornecer --local_model_path com o caminho para o modelo. Usamos n=10 e temperature=0.2 para geração. Verifique o arquivo ./lcb_runner/runner/parser.py para obter mais detalhes sobre os sinalizadores.
Para os modelos de API fechados, --multiprocess sinalizador multiprocess pode ser usado para paralelalizar consultas aos servidores da API (ajustável de acordo com os limites da taxa).
Calculamos pass@1 e pass@5 métricas para avaliações de modelo. Utilizamos uma versão modificada do verificador lançado com a referência apps para calcular as métricas. Particularmente, identificamos alguns casos de borda não tratados no verificador original e os corrigimos e simplificamos o verificador com base em nosso conjunto de dados coletado. Para executar a avaliação, você pode adicionar a bandeira --evaluate :
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration --evaluate Observe que os limites de tempo podem causar pontos leves ( < 0.5 ) de variação no cálculo do pass@1 e pass@5 métricas. Se você observar uma variação significativa no desempenho, ajuste o sinalizador --num_process_evaluate a um valor mais baixo ou aumente o sinalizador --timeout . Por favor, relate questões específicas causadas por tempos inadequados aqui.
Por fim, para obter pontuações em diferentes janelas do tempo, você pode usar ./lcb_runner/evaluation/compute_scores.py. Particularmente, você pode fornecer-sinalizadores --start_date e --end_date (usando o formato YYYY-MM-DD ) para obter pontuações na janela de tempo especificada. Em nosso artigo, para combater a contaminação nos modelos Deepseek, relatamos apenas resultados sobre os problemas divulgados após agosto de 2023. Você pode replicar essas avaliações usando:
python -m lcb_runner.evaluation.compute_scores --eval_all_file {saved_eval_all_file} --start_date 2023-09-01 NOTA: Agarravamos um grande número de casos de teste do benchmark original e criamos code_generation_lite , que é definido como o benchmark padrão, oferecendo uma estimativa de desempenho semelhante muito mais rápida. Se você deseja usar o benchmark original, use o sinalizador --not_fast . Estamos no processo de atualização das pontuações da placa de classificação com esta configuração atualizada.
NOTA: Atualização v2: Para executar a atualização LivecodeBench, use --release_version release_v2 . Além disso, se você tiver resultados existentes do release_v1 , poderá adicionar --continue_existing ou melhor --continue_existing_with_eval sinalizadores para reutilizar as conclusões ou avaliações antigas, respectivamente.
Para executar o reparo automático, você precisa fornecer um sinalizador adicional --codegen_n que mapeia o número de códigos que foram gerados durante a geração de código. Além disso, o sinalizador --temperature é usado para resolver o arquivo de avaliação antigo de geração de código que deve estar presente no diretório output .
python -m lcb_runner.runner.main --model {model_name --scenario selfrepair --codegen_n {num_codes_codegen} --n 1 # only n=1 supported Caso você tenha resultados em um subconjunto ou versão menor do benchmark, você pode usar --continue_existing e --continue_existing_with_eval sinalizadores para reutilizar os cálculos antigos. Particularmente, você pode executar o seguinte comando para continuar a partir de soluções geradas existentes.
python -m lcb_runner.runner.main --model {model_name} --scenario selfrepair --evaluate --continue_existing Observe que isso reutilizará apenas as amostras geradas e as avaliações executadas. Para reutilizar as avaliações antigas, você pode adicionar o sinalizador --continue_existing_with_eval .
Para executar o cenário de previsão de saída de teste, você pode simplesmente executar
python -m lcb_runner.runner.main --model {model_name} --scenario testoutputprediction --evaluatePara executar o cenário de previsão de saída de teste, você pode simplesmente executar
python -m lcb_runner.runner.main --model {model_name} --scenario codeexecution --evaluateAlém disso, apoiamos a configuração do COT com
python -m lcb_runner.runner.main --model {model_name} --scenario codeexecution --cot_code_execution --evaluate Como alternativa, você pode usar lcb_runner/runner/custom_evaluator.py para avaliar diretamente as gerações do modelo em um arquivo personalizado. O arquivo deve conter uma lista de saídas do modelo, formatada apropio para avaliação na ordem de problemas de referência.
python -m lcb_runner.runner.custom_evaluator --custom_output_file {path_to_custom_outputs}Particularmente, organize as saídas no seguinte formato
[
{ "question_id" : " id1 " , "code_list" : [ " code1 " , " code2 " ]},
{ "question_id" : " id2 " , "code_list" : [ " code1 " , " code2 " ]}
]Para adicionar suporte para novos modelos, implementamos uma estrutura extensível para adicionar novos modelos e personalizar os avisos apropriadamente.
Etapa 1: adicione um novo modelo ao arquivo ./lcb_runner/lm_styles.py. Particularmente, estenda a classe LMStyle para adicionar uma nova família modelo e estender o modelo à matriz LanguageModelList .
Etapa 2: Como usamos modelos sintonizados por instruções, permitimos configurar a instrução para cada modelo. Modifique o arquivo ./lcb_runner/prompts/generation.py para adicionar um novo prompt para o modelo na função format_prompt_generation . Por exemplo, o prompt para a família de modelos DeepSeekCodeInstruct parece seguinte
# ./lcb_runner/prompts/generation.py
if LanguageModelStyle == LMStyle . DeepSeekCodeInstruct :
prompt = f" { PromptConstants . SYSTEM_MESSAGE_DEEPSEEK } n n "
prompt += f" { get_deepseekcode_question_template_answer ( question ) } "
return prompt Para enviar modelos para a tabela de classificação, você pode preencher este formulário. Você precisará preencher os detalhes do modelo e fornecer o arquivo de avaliação gerado com gerações de modelos e passar@1 pontuações. Analisaremos o envio e adicionaremos o modelo à tabela de classificação de acordo.
Mantemos uma lista de problemas e atualizações conhecidos no arquivo errata.md. Particularmente, documentamos questões sobre testes errôneos e problemas não passíveis de autogradar. Estamos constantemente usando esse feedback para melhorar nossas heurísticas de seleção de problemas à medida que atualizamos o LivecodeBench.
O LiveCodeBench pode ser usado para avaliar o desempenho do LLMS em diferentes janelas do tempo (usando a data de liberação do problema para filtrar os modelos). Assim, podemos detectar e impedir a contaminação potencial no processo de avaliação e avaliar o LLMS em novos problemas.
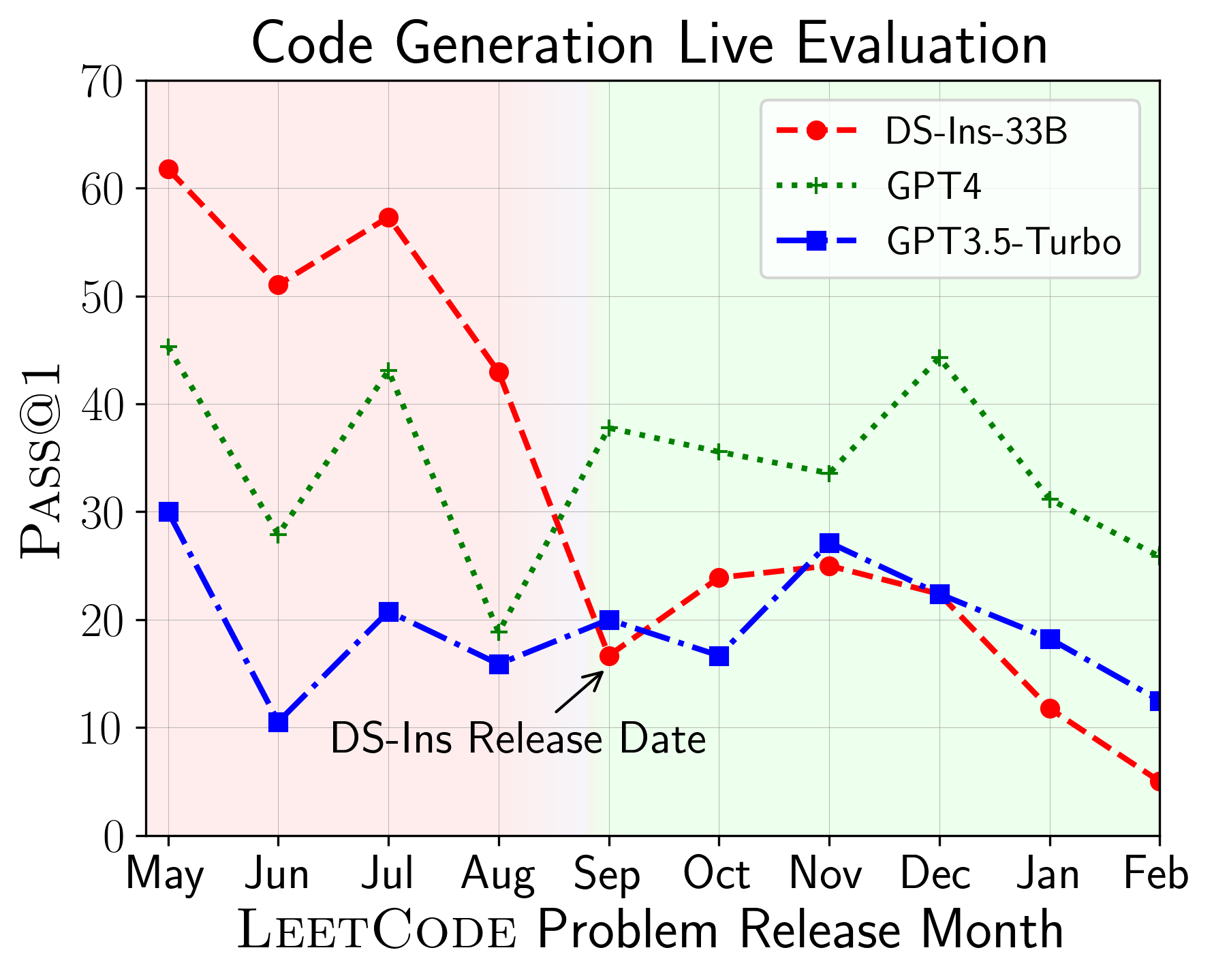
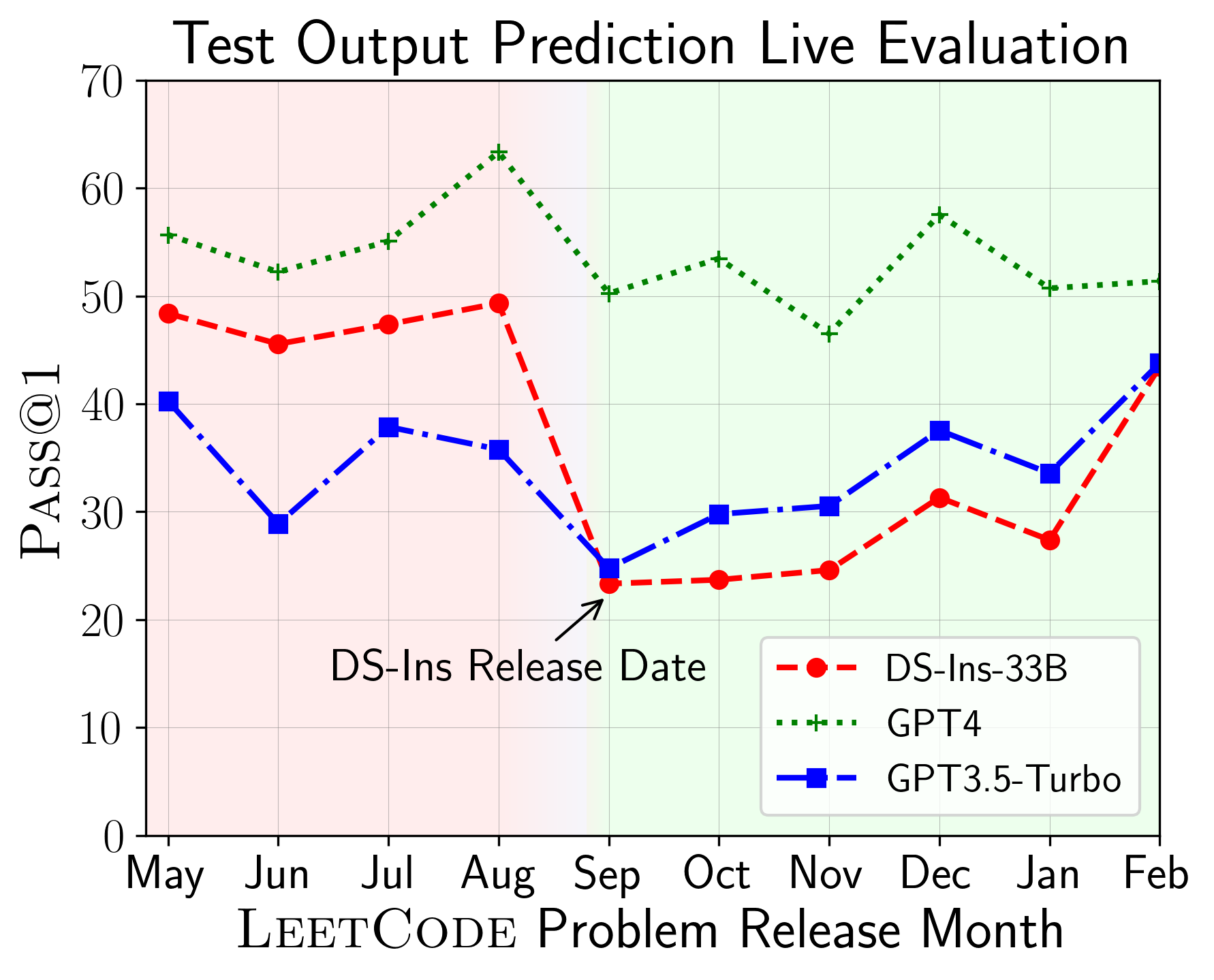
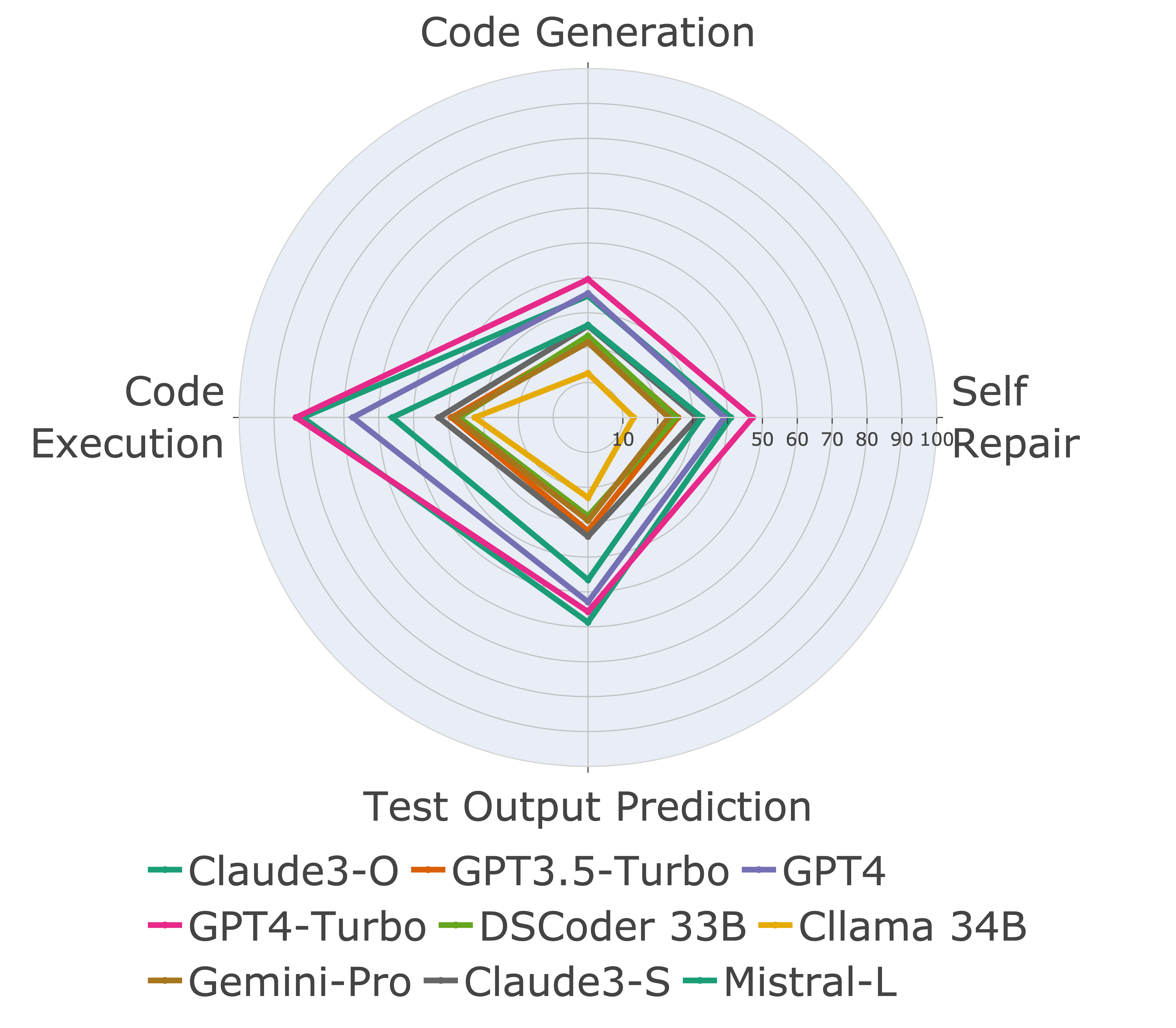
Em seguida, avaliamos modelos em diferentes recursos de código e descobrimos que o desempenho relativo dos modelos muda em relação às tarefas (à esquerda). Assim, destaca a necessidade de avaliação holística do LLMS para código.
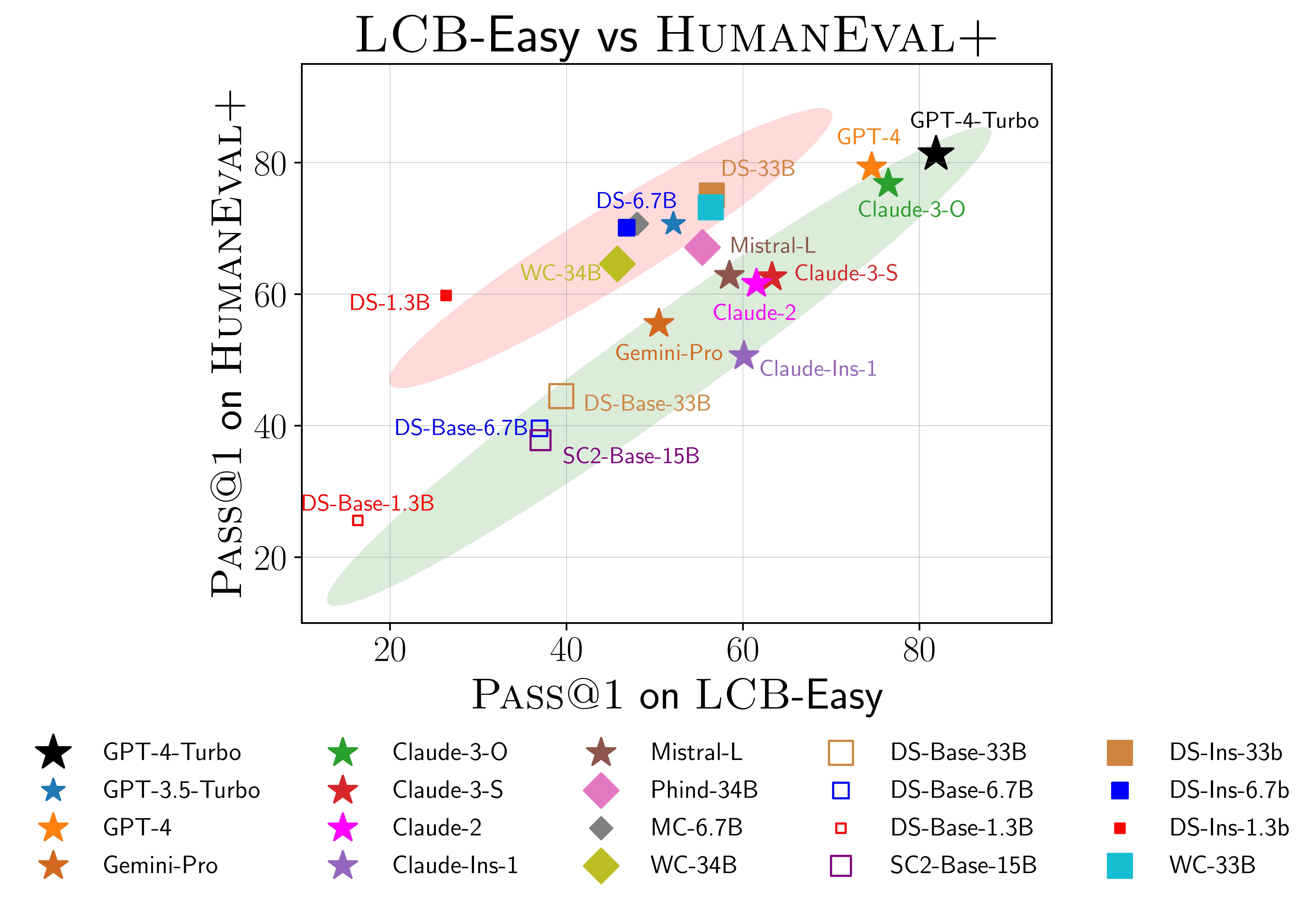
Também encontramos evidências de possíveis ajustes sobre o Humaneval (à direita). Particularmente, os modelos que têm um bom desempenho no Humaneval não têm um bom desempenho no LivecodeBench. No gráfico de dispersão acima, descobrimos que os modelos são agrupados em dois grupos, sombreados em vermelho e verde. O grupo vermelho contém modelos que têm um bom desempenho no Humaneval, mas mal no LivecodeBench, enquanto o grupo verde contém modelos que têm um bom desempenho em ambos.
Para mais detalhes, consulte o nosso site em livecodebench.github.io.
@article { jain2024livecodebench ,
author = { Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, Ion Stoica } ,
title = { LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code } ,
year = { 2024 } ,
journal = { arXiv preprint } ,
}

