LiveCodeBench
1.0.0
논문의 공식 저장소 "LiveCodebench : 전체 론적 및 오염 코드에 대한 대형 언어 모델의 무료 평가"
? 홈페이지 • 데이터 •? 리더 보드
LiveCodeBench는 LLM의 코딩 기능에 대한 전체 론적 및 오염이없는 평가를 제공합니다. 특히 LiveCodeBench는 Leetcode, Atcoder 및 Codeforces의 세 가지 경쟁 플랫폼에서 경쟁에서 시간이 지남에 따라 지속적으로 새로운 문제를 수집합니다. 다음으로 LiveCodeBench는 단지 코드 생성을 넘어서 자체 수리, 코드 실행 및 테스트 출력 예측과 같은 광범위한 코드 관련 기능에 중점을 둡니다. 현재 LiveCodeBench는 2023 년 5 월에서 2024 년 3 월 사이에 출판 된 400 개의 고품질 코딩 문제를 주최합니다.
다음 명령을 사용하여 저장소를 복제 할 수 있습니다.
git clone https://github.com/LiveCodeBench/LiveCodeBench.git
cd LiveCodeBench종속성 관리를 위해시를 사용하는 것이 좋습니다. 다음 명령을 사용하여시와 의존성을 설치할 수 있습니다.
pip install poetry
poetry install 기본 설정은 vllm 설치하지 않습니다. vllm 도 설치하려면 다음을 사용할 수 있습니다.
poetry install --with with-gpu다양한 코드 기능 시나리오에 대한 벤치 마크를 제공합니다
LiveCodeBench는 지속적으로 업데이트 된 벤치 마크이므로 다른 버전의 데이터 세트를 제공합니다. 특히, 우리는 다음 버전의 데이터 세트를 제공합니다.
release_v1 : 2023 년 5 월부터 2024 년 3 월 사이에 400 개의 문제가 포함 된 문제가있는 데이터 세트의 초기 릴리스.release_v2 : 2023 년 5 월에서 2024 년 5 월 사이에 511 개의 문제가 포함 된 문제가있는 데이터 세트의 업데이트 된 릴리스 릴리스.release_v3 : 2023 년 5 월과 2024 년 7 월 사이에 612 개의 문제가 포함 된 문제가있는 데이터 세트의 업데이트 된 릴리스.release_v4 : 2023 년 5 월에서 2024 년 9 월 사이에 713 개의 문제가 포함 된 문제가있는 데이터 세트의 업데이트 된 릴리스. --release_version 플래그를 사용하여 사용하려는 데이터 세트 버전을 지정할 수 있습니다. 특히 다음 명령을 사용하여 release_v2 데이터 세트에서 평가를 실행할 수 있습니다. 릴리스 버전 기본값은 release_latest 로 기본값을 제공합니다.
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration --evaluate --release_version release_v2 우리는 개방형 모델을 사용하여 추론에 vllm 사용합니다. 기본적으로 tensor_parallel_size=${num_gpus} 사용하여 사용 가능한 모든 GPU에서 추론을 병렬화합니다. 필요에 따라 --tensor_parallel_size 플래그를 사용하여 구성 할 수 있습니다.
추론을 실행하려면 ./lcb_runner/lm_styles.py 파일을 기반으로 model_name 을 제공하십시오. 시나리오 (여기서 codegeneration )를 사용하여 모델의 시나리오를 지정할 수 있습니다.
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration 또한 --use_cache 플래그를 사용하여 생성 된 출력을 캐시하고 --continue_existing 플래그를 사용하여 기존 덤프 결과를 사용 할 수 있습니다. 로컬 경로에서 모델을 사용하려는 경우, 모델의 경로에 --local_model_path 플래그를 추가로 제공 할 수 있습니다. 우리는 생성에 n=10 , temperature=0.2 사용합니다. 플래그에 대한 자세한 내용은 ./lcb_runner/runner/parser.py 파일을 확인하십시오.
폐쇄 된 API 모델의 경우 --multiprocess 플래그를 사용하여 API 서버에 쿼리를 병렬화 할 수 있습니다 (요율 제한에 따라 조정 가능).
모델 평가를 위해 pass@1 과 pass@5 메트릭을 계산합니다. 우리는 apps 벤치 마크와 함께 릴리스 된 수정 된 체커 버전을 사용하여 메트릭을 계산합니다. 특히, 우리는 원래 체커에서 처리되지 않은 모서리 케이스를 식별하고 수정하고 수집 된 데이터 세트를 기반으로 체커를 추가로 단순화했습니다. 평가를 실행하려면 --evaluate 플래그를 추가 할 수 있습니다.
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration --evaluate 시간 제한은 pass@1 및 pass@5 메트릭의 계산에서 약간 ( < 0.5 ) 변동 점을 유발할 수 있습니다. 성능의 상당한 변화를 관찰하면 --num_process_evaluate 플래그를 낮은 값으로 조정하거나 --timeout 플래그를 늘리십시오. 부적절한 시간 초과로 인한 특정 문제를 여기에서보고하십시오.
마지막으로, 다른 시간 Windows에서 점수를 얻으려면 ./lcb_runner/evaluation/compute_scores.py 파일을 사용할 수 있습니다. 특히, 당신은 --start_date 및 --end_date 플래그 ( YYYY-MM-DD 형식 사용)를 제공하여 지정된 시간 창을 통해 점수를 얻을 수 있습니다. 우리 논문에서, DeepSeek 모델의 오염에 대응하기 위해, 우리는 2023 년 8 월 이후에 발표 된 문제에 대한 결과 만보고합니다. 다음을 사용하여 해당 평가를 복제 할 수 있습니다.
python -m lcb_runner.evaluation.compute_scores --eval_all_file {saved_eval_all_file} --start_date 2023-09-01 참고 : 원래 벤치 마크에서 많은 수의 테스트 케이스를 잘라 내고 code_generation_lite 만들었습니다. Code_Generation_lite는 비슷한 성능 추정을 훨씬 더 빨리 제공하는 기본 벤치 마크로 설정되었습니다. 원래 벤치 마크를 사용하려면 --not_fast 플래그를 사용하십시오. 우리는이 업데이트 된 설정으로 리더 보드 점수를 업데이트하는 중입니다.
참고 : v2 업데이트 : LiveCodeBench 업데이트를 실행하려면 --release_version release_v2 사용하십시오. 또한 release_v1 의 기존 결과가있는 경우 --continue_existing 또는 더 나은 --continue_existing_with_eval 플래그를 추가하여 이전 완료 또는 평가를 각각 재사용 할 수 있습니다.
자체 수리를 실행하려면 코드 생성 중에 생성 된 코드 수에 매핑되는 추가 --codegen_n 플래그를 제공해야합니다. 또한 --temperature 플래그는 output 디렉토리에 존재 해야하는 이전 코드 생성 평가 파일을 해결하는 데 사용됩니다.
python -m lcb_runner.runner.main --model {model_name --scenario selfrepair --codegen_n {num_codes_codegen} --n 1 # only n=1 supported 더 작은 서브 세트 또는 벤치 마크 버전에 결과가있는 경우 --continue_existing 및 --continue_existing_with_eval 플래그를 사용하여 이전 계산을 재사용 할 수 있습니다. 특히 기존 생성 된 솔루션에서 계속하기 위해 다음 명령을 실행할 수 있습니다.
python -m lcb_runner.runner.main --model {model_name} --scenario selfrepair --evaluate --continue_existing 이것은 생성 된 샘플과 평가를 재사용 할 것입니다. 기존 평가를 재사용하려면 --continue_existing_with_eval 플래그를 추가 할 수 있습니다.
테스트 출력 예측 시나리오를 실행하려면 간단히 실행할 수 있습니다.
python -m lcb_runner.runner.main --model {model_name} --scenario testoutputprediction --evaluate테스트 출력 예측 시나리오를 실행하려면 간단히 실행할 수 있습니다.
python -m lcb_runner.runner.main --model {model_name} --scenario codeexecution --evaluate또한 COT 설정을 지원합니다
python -m lcb_runner.runner.main --model {model_name} --scenario codeexecution --cot_code_execution --evaluate 또는 lcb_runner/runner/custom_evaluator.py 사용하여 사용자 정의 파일에서 직접 평가 된 모델 세대를 사용하여 직접 평가할 수 있습니다. 파일에는 벤치 마크 문제의 순서대로 평가를 위해 적절하게 형식화 된 모델 출력 목록이 포함되어야합니다.
python -m lcb_runner.runner.custom_evaluator --custom_output_file {path_to_custom_outputs}특히 출력을 다음 형식으로 배열하십시오
[
{ "question_id" : " id1 " , "code_list" : [ " code1 " , " code2 " ]},
{ "question_id" : " id2 " , "code_list" : [ " code1 " , " code2 " ]}
]새로운 모델에 대한 지원을 추가하기 위해 새로운 모델을 추가하고 프롬프트를 적절하게 사용자 정의하기위한 확장 가능한 프레임 워크를 구현했습니다.
1 단계 : ./lcb_runner/lm_styles.py 파일에 새 모델을 추가합니다. 특히 LMStyle 클래스를 확장하여 새로운 모델 패밀리를 추가하고 모델을 LanguageModelList 배열로 확장하십시오.
2 단계 : 명령어 튜닝 모델을 사용하므로 각 모델의 명령을 구성 할 수 있습니다. ./lcb_runner/prompts/generation.py 파일을 수정하여 format_prompt_generation 함수의 모델에 대한 새로운 프롬프트를 추가하십시오. 예를 들어, DeepSeekCodeInstruct 모델의 프롬프트는 다음과 같이 보입니다.
# ./lcb_runner/prompts/generation.py
if LanguageModelStyle == LMStyle . DeepSeekCodeInstruct :
prompt = f" { PromptConstants . SYSTEM_MESSAGE_DEEPSEEK } n n "
prompt += f" { get_deepseekcode_question_template_answer ( question ) } "
return prompt 리더 보드에 모델을 제출하려면이 양식을 작성할 수 있습니다. 모델 세부 정보를 작성하고 생성 된 평가 파일에 모델 세대를 제공하고@1 점수를 전달해야합니다. 제출물을 검토하고 그에 따라 리더 보드에 모델을 추가합니다.
우리는 errata.md 파일에서 알려진 문제와 업데이트 목록을 유지합니다. 특히, 우리는 잘못된 테스트 및자가 활동에 적합하지 않은 문제에 관한 문제를 문서화합니다. LiveCodeBench를 업데이트 할 때 문제 선택 휴리스틱을 개선하기 위해이 피드백을 지속적으로 사용하고 있습니다.
LiveCodeBench를 사용하여 다른 시간 창에서 LLM의 성능을 평가할 수 있습니다 (문제 릴리스 날짜를 사용하여 모델을 필터링). 따라서 우리는 평가 프로세스에서 잠재적 오염을 감지하고 방지 할 수 있으며 새로운 문제에 대한 LLM을 평가할 수 있습니다.
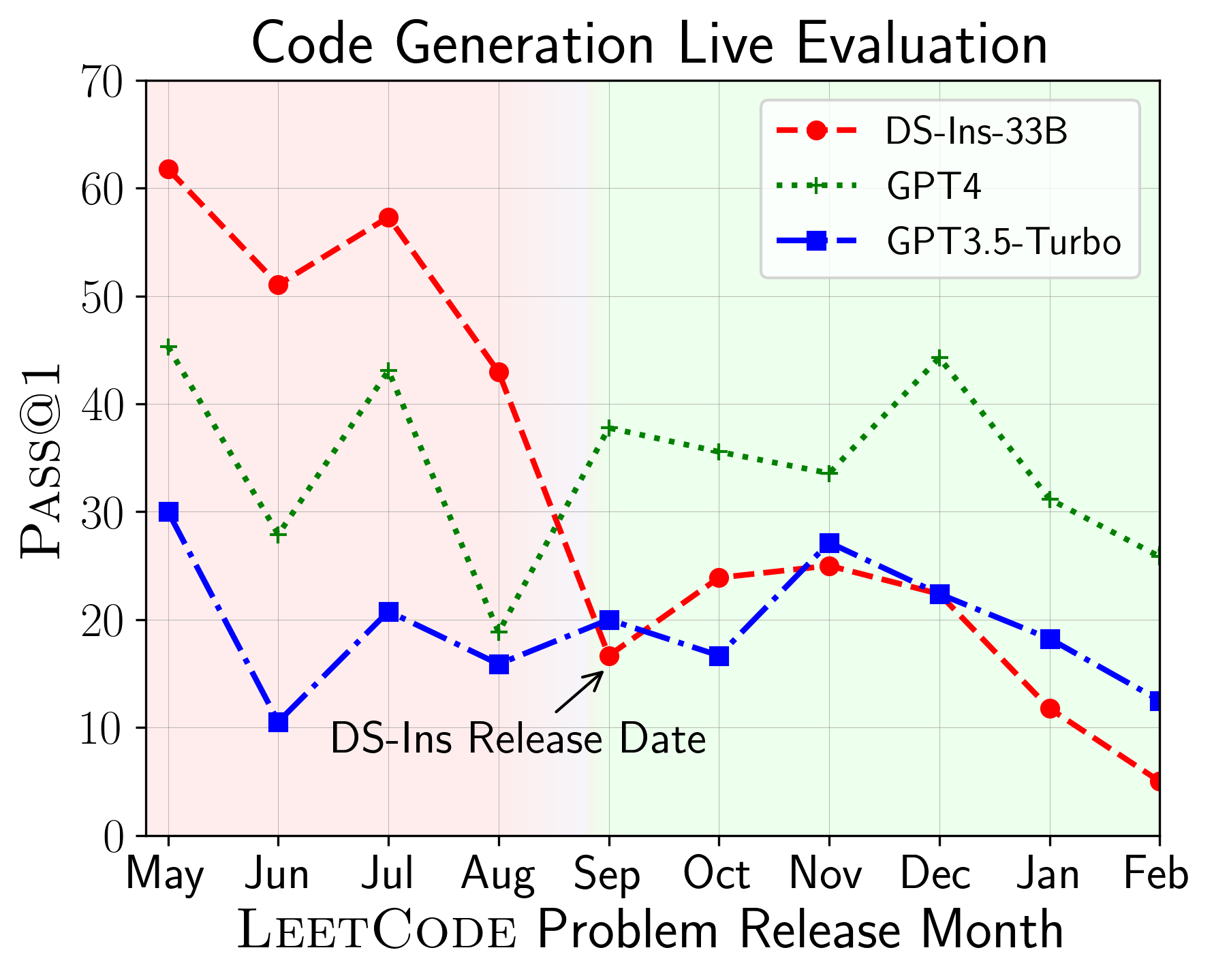
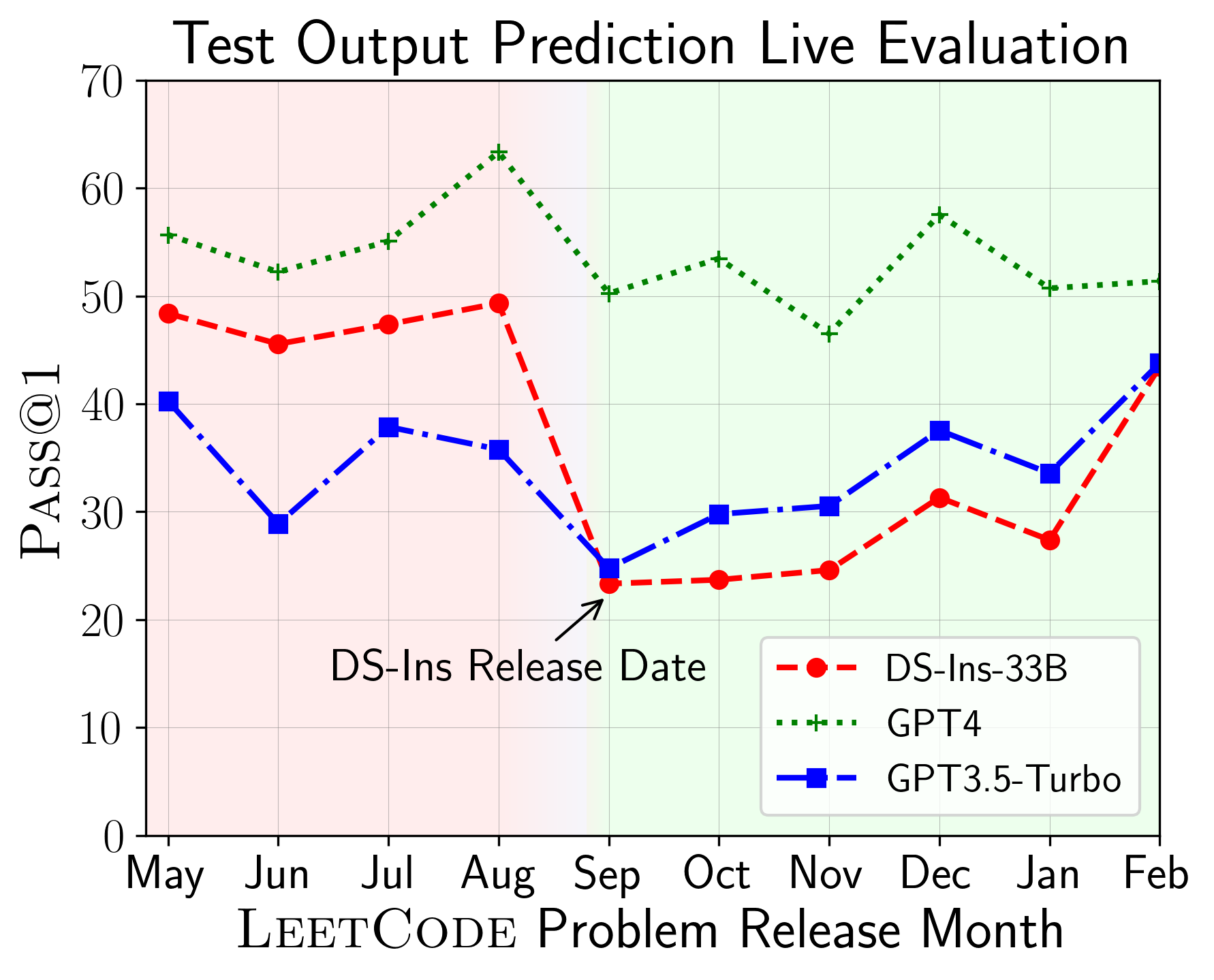
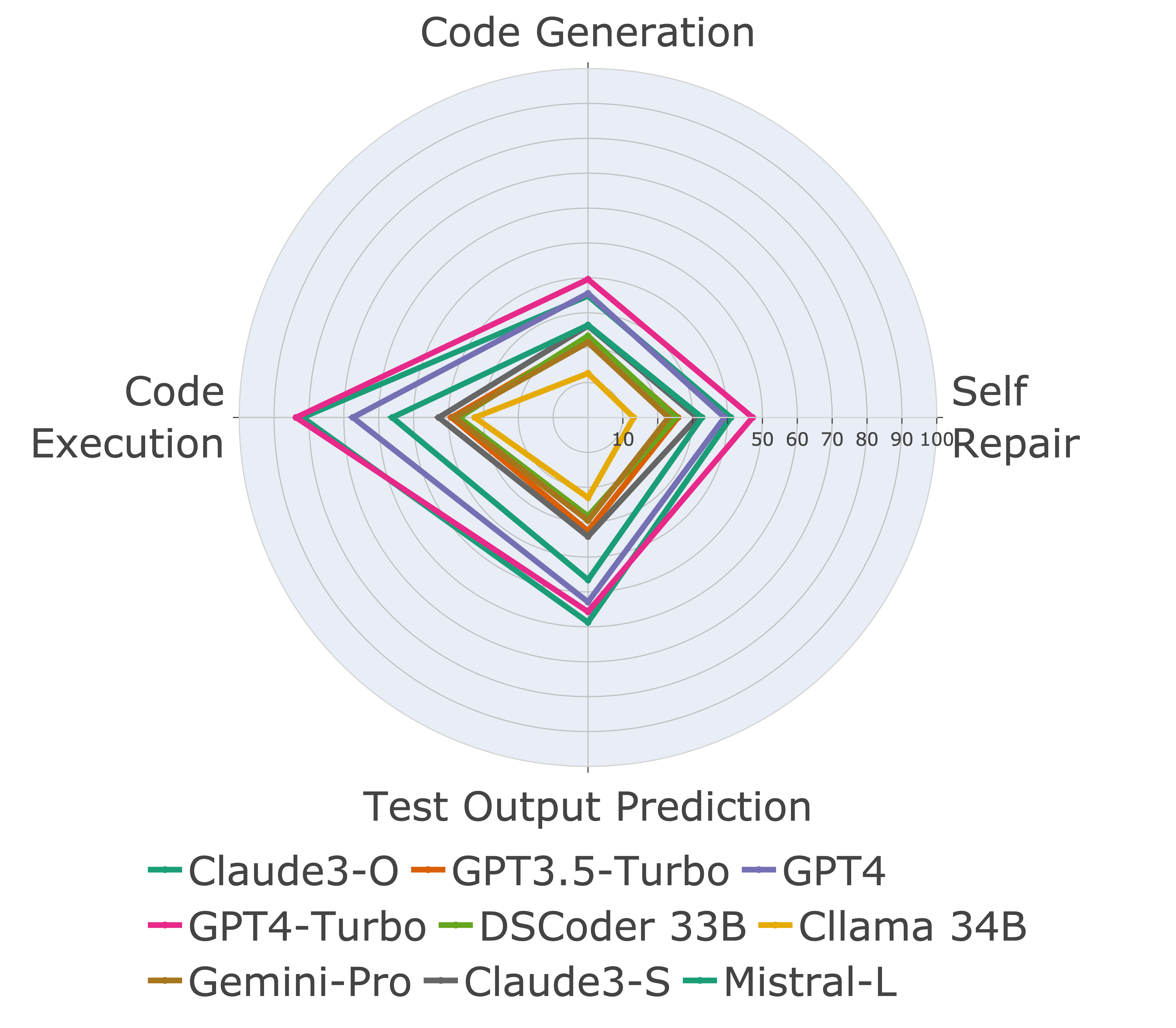
다음으로, 다른 코드 기능에 대한 모델을 평가하고 모델의 상대적인 성능이 작업을 통해 변경되는 것을 발견합니다 (왼쪽). 따라서 코드에 대한 LLM의 전체적인 평가가 필요하다는 것을 강조합니다.
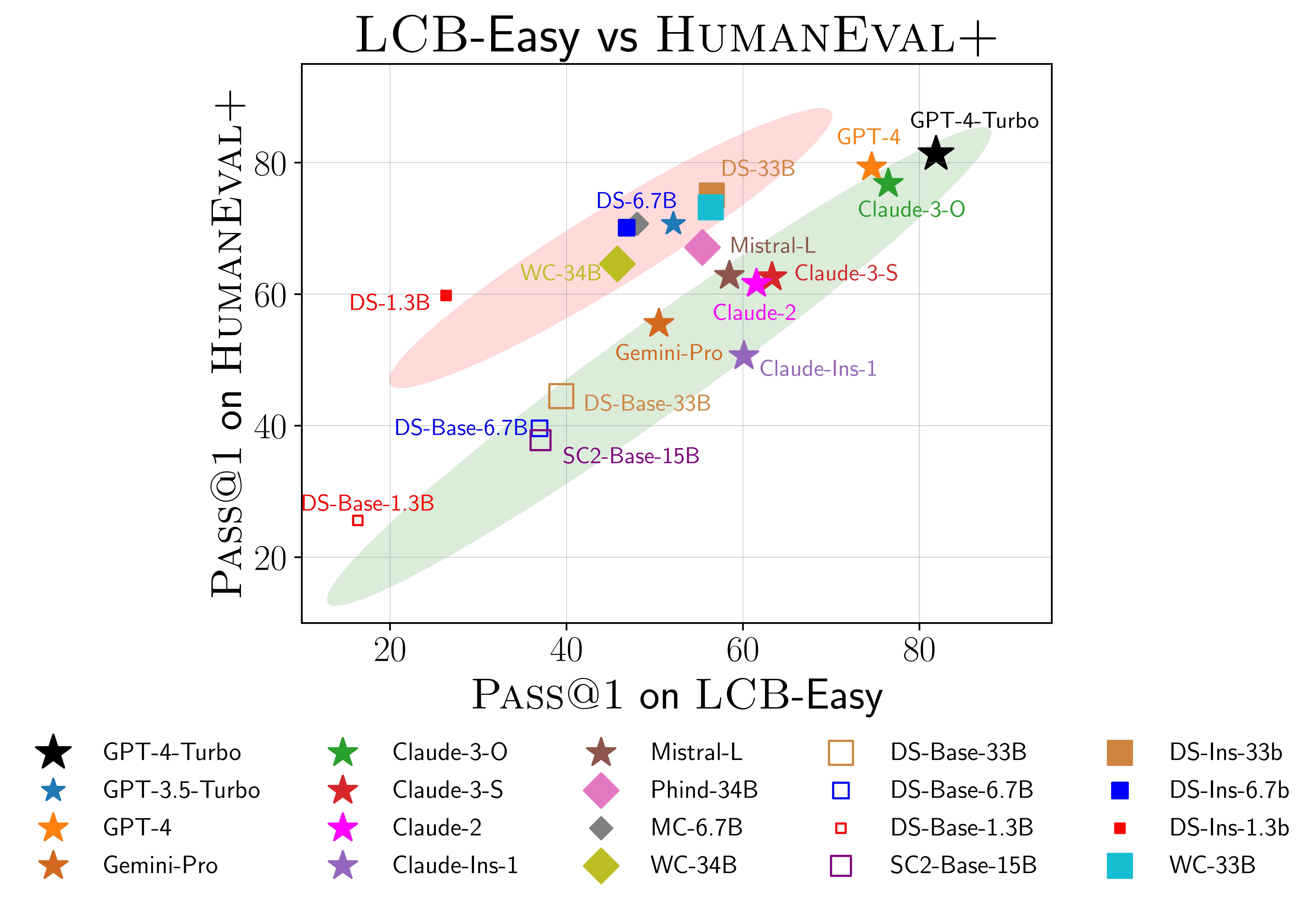
우리는 또한 Humaneval (오른쪽)에 과적이라는 증거를 발견했습니다. 특히 Humaneval에서 잘 수행되는 모델이 LiveCodebench에서 반드시 잘 수행되는 것은 아닙니다. 위의 ScatterPlot에서는 모델이 빨간색과 녹색으로 음영 처리 된 두 그룹으로 클러스터링됩니다. Red Group에는 Humaneval에서는 잘 작동하지만 Livecodebench에서는 잘 작동하지 않는 모델이 포함되어 있으며 Green Group에는 두 가지에서 잘 수행되는 모델이 포함되어 있습니다.
자세한 내용은 당사 웹 사이트 (livecodebench.github.io)를 참조하십시오.
@article { jain2024livecodebench ,
author = { Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, Ion Stoica } ,
title = { LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code } ,
year = { 2024 } ,
journal = { arXiv preprint } ,
}

