LiveCodeBench
1.0.0
Официальный репозиторий для статьи "Livecodebench: Целостная и бесплатная оценка крупных языковых моделей для кода"
? Домашняя страница • Данные •? Таблица лидеров
Livecodebench обеспечивает целостную и без загрязнения оценку возможностей кодирования LLMS. В частности, LiveCodebench непрерывно собирает новые проблемы со временем из конкурсов на трех конкурсных платформах - LeetCode, Atcoder и Codeforces. Затем LiveCodebench также фокусируется на более широком диапазоне возможностей, связанных с кодом, таких как самореализация, выполнение кода и прогноз вывода теста, помимо генерации Just Code. В настоящее время Livecodebench проводит четыре сотен высококачественных проблем кодирования, которые были опубликованы в период с мая 2023 года по март 2024 года.
Вы можете клонировать репозиторий, используя следующую команду:
git clone https://github.com/LiveCodeBench/LiveCodeBench.git
cd LiveCodeBenchМы рекомендуем использовать поэзию для управления зависимостями. Вы можете установить поэзию и зависимости, используя следующие команды:
pip install poetry
poetry install Настройка по умолчанию не устанавливает vllm . Для установки vllm вы можете использовать:
poetry install --with with-gpuМы предоставляем эталон для различных сценариев возможности кода
Поскольку Livecodebench является непрерывно обновленным эталоном, мы предоставляем различные версии набора данных. В частности, мы предоставляем следующие версии набора данных:
release_v1 : первоначальный выпуск набора данных с проблемами, выпущенными в период с мая 2023 года по март 2024 года, содержащий 400 задач.release_v2 : обновленный выпуск набора данных с проблемами, выпущенными в период с мая 2023 года по май 2024, содержащий 511 задач.release_v3 : обновленный выпуск набора данных с проблемами, выпущенными в период с мая 2023 года и июля 2024 года, содержащий 612 задач.release_v4 : обновленный выпуск набора данных с проблемами, выпущенными в период с мая 2023 года и сентября 2024 года, содержащий 713 задач. Вы можете использовать флаг --release_version , чтобы указать версию набора данных, которую вы хотите использовать. В частности, вы можете использовать следующую команду для запуска оценки в наборе данных release_v2 . Выпустить версию по умолчанию в release_latest .
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration --evaluate --release_version release_v2 Мы используем vllm для вывода с использованием открытых моделей. По умолчанию мы используем tensor_parallel_size=${num_gpus} для параллелизации вывода во всех доступных графических процессорах. Его можно настроить с использованием флага --tensor_parallel_size по мере необходимости.
Для выполнения вывода, пожалуйста, предоставьте файл model_name на основе файла ./lcb_runner/lm_styles.py. Сценарий (здесь codegeneration ) может использоваться для указания сценария для модели.
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration Кроме того, флаг --use_cache может использоваться для кэширования сгенерированных выходов, а флаг --continue_existing для использования существующих сброшенных результатов. Если вы хотите использовать модель из локального пути, вы можете дополнительно предоставить флаг --local_model_path с путем к модели. Мы используем n=10 и temperature=0.2 для генерации. Пожалуйста, проверьте файл ./lcb_runner/runner/parser.py для получения более подробной информации о флагах.
Для закрытых моделей API флаг --multiprocess можно использовать для параллелизации запросов с серверами API (регулируемые в соответствии с ограничениями скорости).
Мы вычисляем pass@1 и pass@5 метрик для оценки моделей. Мы используем модифицированную версию Checker, выпущенную с помощью теста apps для вычисления метрик. В частности, мы определили некоторые нецелостные кромки в исходной шашере и исправили их и дополнительно упростили проверку на основе нашего собранного набора данных. Чтобы запустить оценку, вы можете добавить флаг --evaluate :
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration --evaluate Обратите внимание, что ограничения срока могут вызвать небольшие ( < 0.5 ) точки вариации в вычислении pass@1 и pass@5 метрик. Если вы соблюдаете значительное изменение производительности, отрегулируйте флаг --num_process_evaluate до более низкого значения или увеличьте флаг --timeout . Пожалуйста, сообщите о конкретных вопросах, вызванных неправильными тайм -аутами здесь.
Наконец, чтобы получить результаты в разных временных окнах, вы можете использовать файл ./lcb_runner/evaluation/compute_scores.py. В частности, вы можете предоставить флаги --start_date и --end_date (с использованием формата YYYY-MM-DD ), чтобы получить результаты за указанное временное окно. В нашей статье, чтобы противостоять загрязнению в моделях DeepSeek, мы сообщаем только о результатах по проблемам, опубликованным после августа 2023 года. Вы можете повторить эти оценки, используя:
python -m lcb_runner.evaluation.compute_scores --eval_all_file {saved_eval_all_file} --start_date 2023-09-01 Примечание. Мы обрезали большое количество тестовых случаев из исходного теста и создали code_generation_lite , который устанавливается в качестве эталона по умолчанию, предлагая аналогичную оценку производительности гораздо быстрее. Если вы хотите использовать оригинальный эталон, пожалуйста, используйте флаг --not_fast . Мы находимся в процессе обновления результатов таблицы лидеров с помощью этой обновленной настройки.
Примечание: v2 Обновление: для запуска обновления LiveCodeBench, пожалуйста, используйте --release_version release_v2 . Кроме того, если у вас есть существующие результаты от release_v1 , вы можете добавить флаги --continue_existing или лучше --continue_existing_with_eval для повторного использования старых завершений или оценок соответственно.
Для запуска самостоятельного ремонта вам необходимо предоставить дополнительный флаг --codegen_n , который отображает количество кодов, которые были сгенерированы во время генерации кода. Кроме того, флаг --temperature используется для разрешения старого файла eval генерации кода, который должен присутствовать в output каталоге.
python -m lcb_runner.runner.main --model {model_name --scenario selfrepair --codegen_n {num_codes_codegen} --n 1 # only n=1 supported Если у вас есть результаты по меньшей подмножеству или версии эталона, вы можете использовать флаги --continue_existing и --continue_existing_with_eval для повторного использования старых вычислений. В частности, вы можете запустить следующую команду, чтобы продолжить из существующих сгенерированных решений.
python -m lcb_runner.runner.main --model {model_name} --scenario selfrepair --evaluate --continue_existing Обратите внимание, что это только повторно использует сгенерированные образцы и оценки повторного запуска. Чтобы повторно использовать старые оценки, вы можете добавить флаг --continue_existing_with_eval .
Для запуска сценария прогнозирования вывода теста вы можете просто запустить
python -m lcb_runner.runner.main --model {model_name} --scenario testoutputprediction --evaluateДля запуска сценария прогнозирования вывода теста вы можете просто запустить
python -m lcb_runner.runner.main --model {model_name} --scenario codeexecution --evaluateКроме того, мы поддерживаем настройку кроватки с
python -m lcb_runner.runner.main --model {model_name} --scenario codeexecution --cot_code_execution --evaluate В качестве альтернативы, вы можете использовать lcb_runner/runner/custom_evaluator.py для непосредственно оцениваемых поколений моделей в пользовательском файле. Файл должен содержать список выходов моделей, одобно отформатированный для оценки в порядке заданий.
python -m lcb_runner.runner.custom_evaluator --custom_output_file {path_to_custom_outputs}В частности, расположить выходы в следующем формате
[
{ "question_id" : " id1 " , "code_list" : [ " code1 " , " code2 " ]},
{ "question_id" : " id2 " , "code_list" : [ " code1 " , " code2 " ]}
]Чтобы добавить поддержку новых моделей, мы внедрили расширяемую структуру для добавления новых моделей и настройки подсказок.
Шаг 1: Добавьте новую модель в файл ./lcb_runner/lm_styles.py. В частности, расширить класс LMStyle , чтобы добавить новую модель семейства и расширить модель на массив LanguageModelList .
Шаг 2: Поскольку мы используем модели, настроенные на инструкции, мы разрешаем настройку инструкции для каждой модели. Измените файл ./lcb_runner/prompts/generation.py, чтобы добавить новую подсказку для модели в функции format_prompt_generation . Например, подсказка для семейства моделей DeepSeekCodeInstruct выглядит следующим образом
# ./lcb_runner/prompts/generation.py
if LanguageModelStyle == LMStyle . DeepSeekCodeInstruct :
prompt = f" { PromptConstants . SYSTEM_MESSAGE_DEEPSEEK } n n "
prompt += f" { get_deepseekcode_question_template_answer ( question ) } "
return prompt Чтобы отправить модели в таблицу лидеров, вы можете заполнить эту форму. Вам нужно будет заполнить данные модели и предоставить сгенерированный файл оценки с поколениями моделей и пройти@1 баллы. Мы рассмотрим представление и добавим модель в таблицу лидеров соответственно.
Мы сохраняем список известных проблем и обновлений в файле Errata.md. В частности, мы документируем проблемы, касающиеся ошибочных тестов и проблем, не поддающихся аутограде. Мы постоянно используем эту обратную связь, чтобы улучшить эвристику выбора проблем, когда мы обновляем LiveCodeBench.
LiveCodeBench может использоваться для оценки производительности LLMS на разных временных окнах (используя дату выпуска проблемы для фильтрации моделей). Таким образом, мы можем обнаружить и предотвратить потенциальное загрязнение в процессе оценки и оценивать LLMS по новым проблемам.
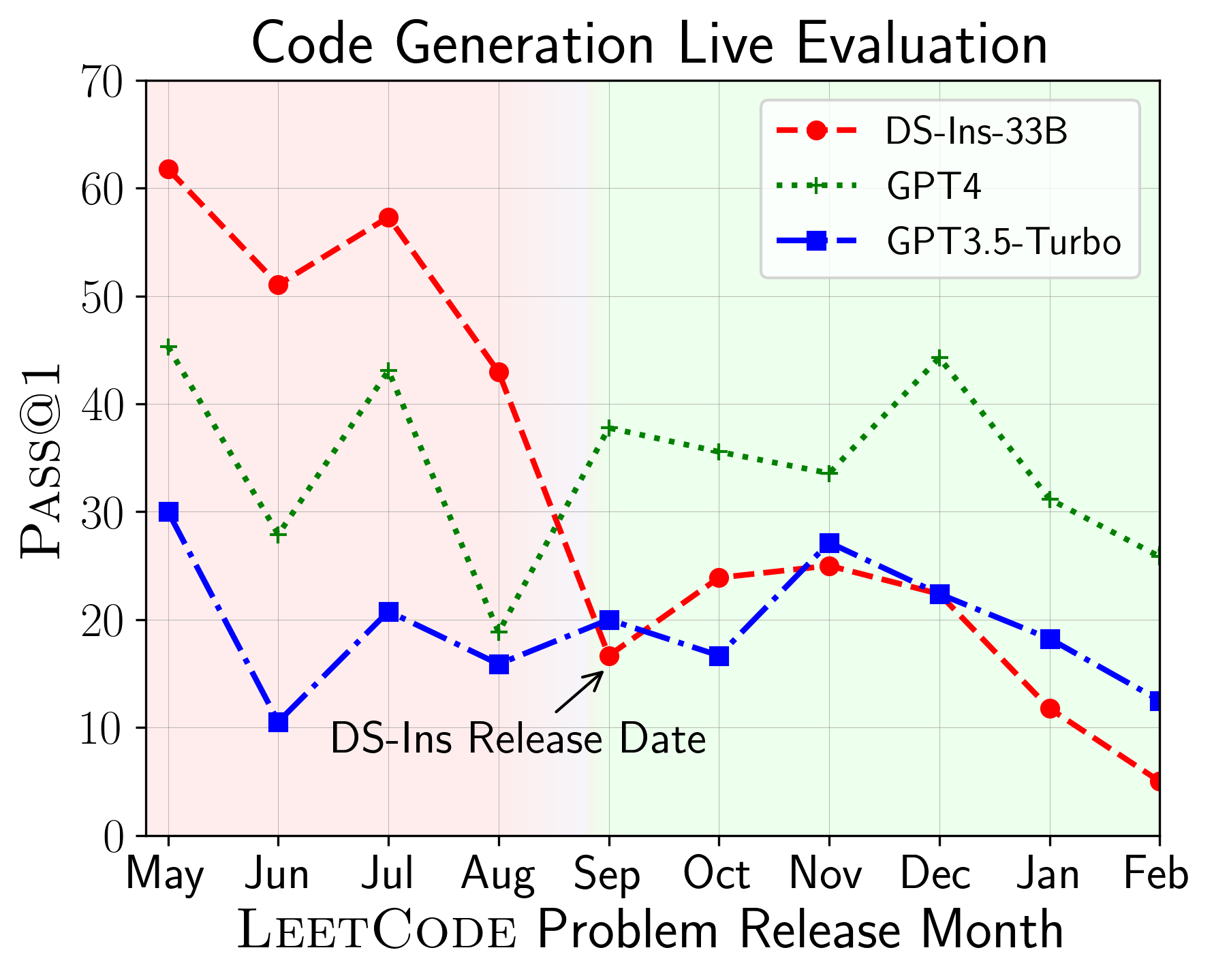
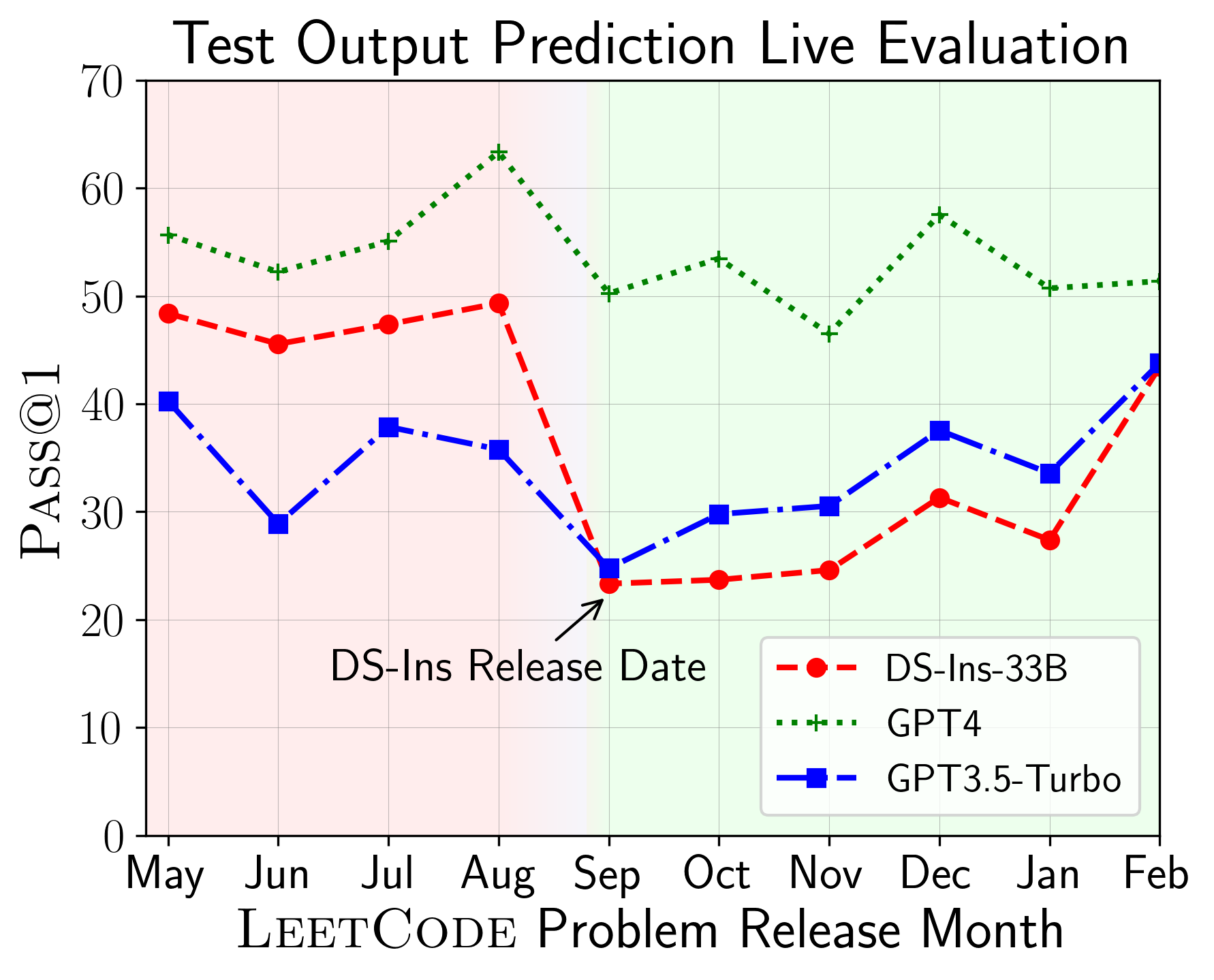
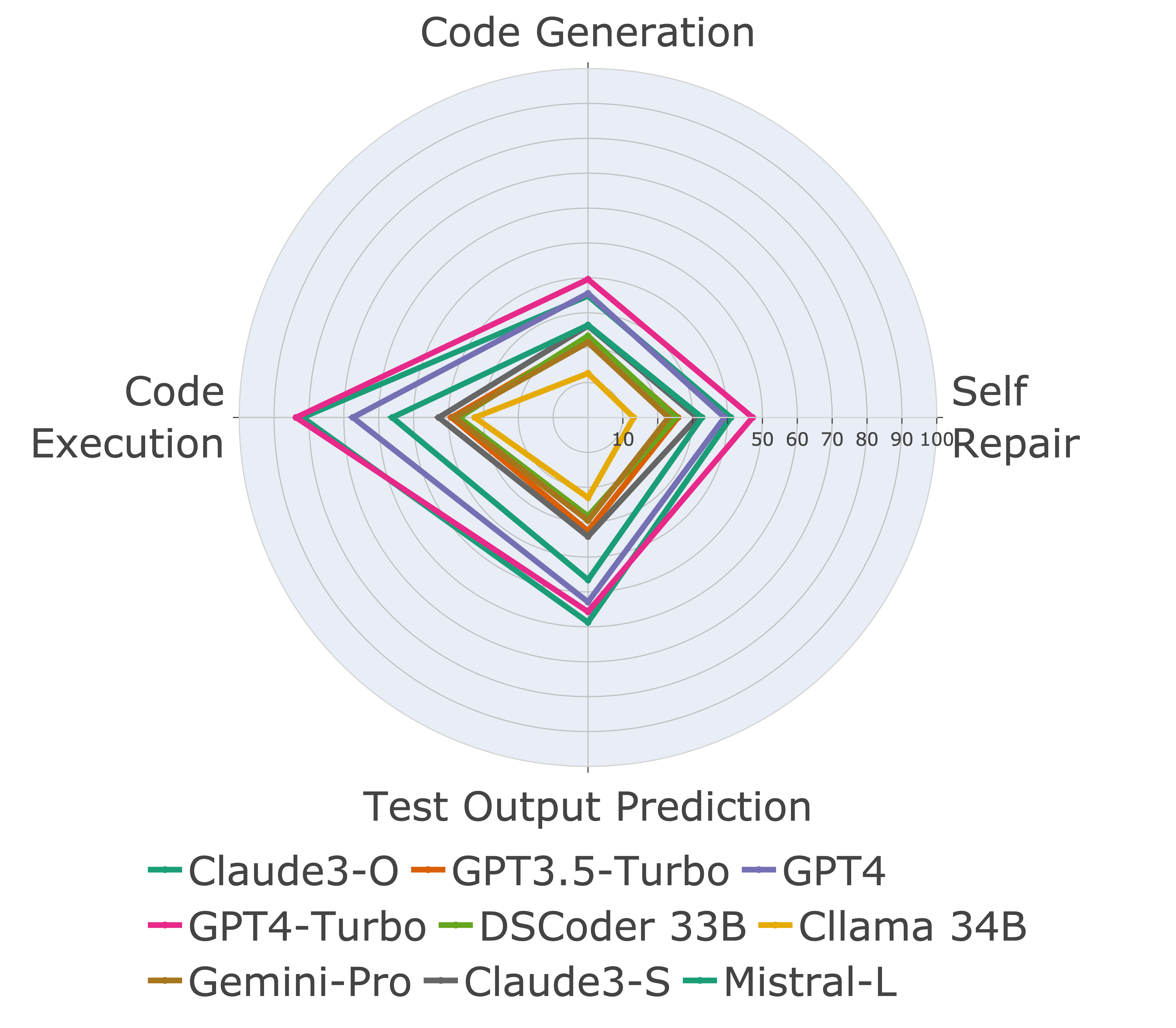
Затем мы оцениваем модели по различным возможностям кода и обнаруживаем, что относительные характеристики моделей меняются по задачам (слева). Таким образом, он подчеркивает необходимость целостной оценки LLM для кода.
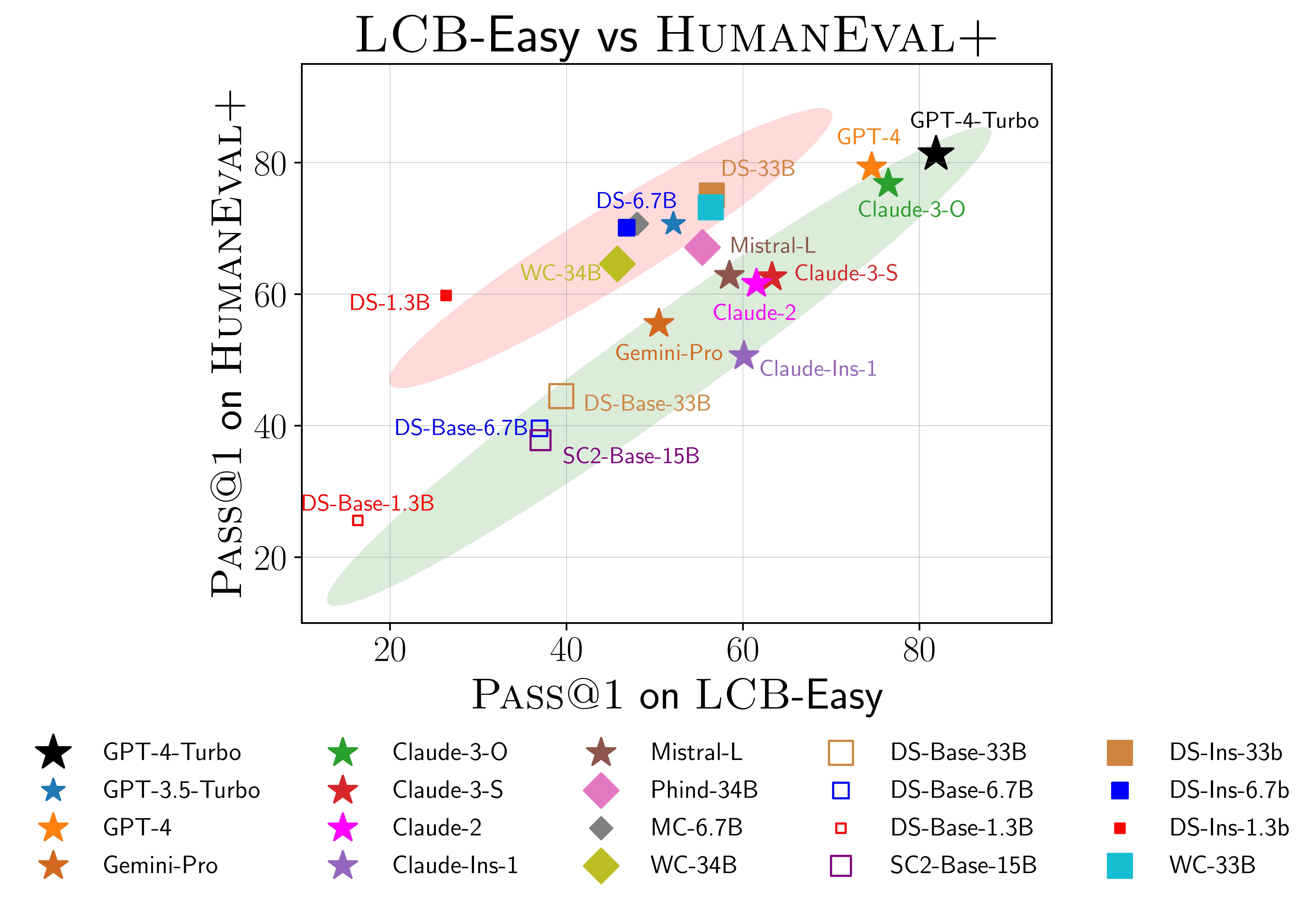
Мы также находим доказательства возможного переживания на гумане (справа). В частности, модели, которые хорошо работают на Humaneval, не обязательно хорошо работают на Livecodebench. На приведенной выше графике мы обнаруживаем, что модели сгруппируются в две группы, затененные красным и зеленым. Красная группа содержит модели, которые хорошо работают на гумане, но плохо на Livecodebench, в то время как зеленая группа содержит модели, которые хорошо работают на обоих.
Для получения более подробной информации, пожалуйста, обратитесь к нашему веб -сайту по адресу livecodebench.github.io.
@article { jain2024livecodebench ,
author = { Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, Ion Stoica } ,
title = { LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code } ,
year = { 2024 } ,
journal = { arXiv preprint } ,
}

