LiveCodeBench
1.0.0
ที่เก็บอย่างเป็นทางการสำหรับกระดาษ "LiveCodeBench: การประเมินแบบองค์รวมและการปนเปื้อนฟรีของแบบจำลองภาษาขนาดใหญ่สำหรับรหัส"
- โฮมเพจ•ข้อมูล•? ลีดเดอร์บอร์ด
LiveCodeBench ให้การประเมินความสามารถในการเข้ารหัสแบบองค์รวมและการปนเปื้อนของ LLMS โดยเฉพาะอย่างยิ่ง LiveCodeBench รวบรวมปัญหาใหม่อย่างต่อเนื่องเมื่อเวลาผ่านไปจากการแข่งขันในสามแพลตฟอร์มการแข่งขัน ได้แก่ LeetCode, Atcoder และ CodeForces ถัดไป LiveCodeBench ยังมุ่งเน้นไปที่ความสามารถที่เกี่ยวข้องกับรหัสที่กว้างขึ้นเช่นการซ่อมแซมตนเองการดำเนินการรหัสและการทดสอบการคาดการณ์เอาท์พุทนอกเหนือจากการสร้างรหัส ปัจจุบัน LiveCodeBench มีปัญหาการเข้ารหัสคุณภาพสูงสี่ร้อยปัญหาที่เผยแพร่ระหว่างเดือนพฤษภาคม 2566 ถึงมีนาคม 2567
คุณสามารถโคลนที่เก็บโดยใช้คำสั่งต่อไปนี้:
git clone https://github.com/LiveCodeBench/LiveCodeBench.git
cd LiveCodeBenchเราขอแนะนำให้ใช้บทกวีสำหรับการจัดการการพึ่งพา คุณสามารถติดตั้งบทกวีและการอ้างอิงโดยใช้คำสั่งต่อไปนี้:
pip install poetry
poetry install การตั้งค่าเริ่มต้นไม่ได้ติดตั้ง vllm ในการติดตั้ง vllm เช่นกันคุณสามารถใช้:
poetry install --with with-gpuเราให้มาตรฐานสำหรับสถานการณ์ความสามารถของรหัสที่แตกต่างกัน
เนื่องจาก LiveCodeBench เป็นเกณฑ์มาตรฐานที่ได้รับการปรับปรุงอย่างต่อเนื่องเราจึงจัดทำชุดข้อมูลเวอร์ชันที่แตกต่างกัน โดยเฉพาะอย่างยิ่งเราจัดเตรียมชุดข้อมูลเวอร์ชันต่อไปนี้:
release_v1 : การเปิดตัวชุดข้อมูลเริ่มต้นที่มีปัญหาที่ปล่อยออกมาระหว่างเดือนพฤษภาคม 2566 ถึง มี.ค. 2024 มีปัญหา 400 ปัญหาrelease_v2 : การเปิดตัวชุดข้อมูลที่อัปเดตพร้อมปัญหาที่เผยแพร่ระหว่างเดือนพฤษภาคม 2566 ถึงพฤษภาคม 2567 มีปัญหา 511release_v3 : การเปิดตัวชุดข้อมูลที่อัปเดตพร้อมปัญหาที่เผยแพร่ระหว่างพฤษภาคม 2023 ถึงกรกฎาคม 2024 ที่มีปัญหา 612release_v4 : การเปิดตัวชุดข้อมูลที่อัปเดตพร้อมปัญหาที่เผยแพร่ระหว่างเดือนพฤษภาคม 2566 ถึง ก.ย. 2024 ที่มีปัญหา 713 คุณสามารถใช้ --release_version FLAG เพื่อระบุเวอร์ชันชุดข้อมูลที่คุณต้องการใช้ โดยเฉพาะอย่างยิ่งคุณสามารถใช้คำสั่งต่อไปนี้เพื่อเรียกใช้การประเมินผลในชุดข้อมูล release_v2 รุ่นรีลีสเริ่มต้นเป็น release_latest
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration --evaluate --release_version release_v2 เราใช้ vllm สำหรับการอนุมานโดยใช้โมเดลแบบเปิด โดยค่าเริ่มต้นเราใช้ tensor_parallel_size=${num_gpus} เพื่อขนานการอนุมานใน GPU ที่มีอยู่ทั้งหมด มันสามารถกำหนดค่าได้โดยใช้ธง --tensor_parallel_size ตามที่ต้องการ
สำหรับการเรียกใช้การอนุมานโปรดระบุ model_name ตามไฟล์ ./lcb_runner/lm_styles.py สถานการณ์ (ที่นี่ codegeneration ) สามารถใช้เพื่อระบุสถานการณ์สำหรับโมเดล
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration นอกจากนี้ -การตั้งค่าสถานะ --use_cache สามารถใช้ในการแคชเอาต์พุตที่สร้างขึ้นและ -การตั้งค่าสถานะ --continue_existing สามารถใช้เพื่อใช้ผลลัพธ์ที่ถูกทิ้งที่มีอยู่ ในกรณีที่คุณต้องการใช้โมเดลจากเส้นทางท้องถิ่นคุณสามารถให้ธง --local_model_path ด้วยเส้นทางไปยังโมเดล เราใช้ n=10 และ temperature=0.2 สำหรับการสร้าง โปรดตรวจสอบ./lcb_runner/runner/parser.py ไฟล์สำหรับรายละเอียดเพิ่มเติมเกี่ยวกับธง
สำหรับโมเดล API แบบปิด -การตั้งค่าสถานะ --multiprocess สามารถใช้ในการสืบค้นแบบขนานไปยังเซิร์ฟเวอร์ API (ปรับได้ตามขีด จำกัด อัตรา)
เราคำนวณ pass@1 และ pass@5 ตัวชี้วัดสำหรับการประเมินแบบจำลอง เราใช้ตัวตรวจสอบเวอร์ชันที่แก้ไขแล้วพร้อมเกณฑ์มาตรฐาน apps เพื่อคำนวณตัวชี้วัด โดยเฉพาะอย่างยิ่งเราระบุกรณีขอบที่ไม่ได้รับการจัดการบางอย่างในตัวตรวจสอบเดิมและแก้ไขและทำให้ตัวตรวจสอบง่ายขึ้นตามชุดข้อมูลที่เรารวบรวม ในการเรียกใช้การประเมินผลคุณสามารถเพิ่มค่าสถานะ --evaluate :
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration --evaluate โปรดทราบว่าการ จำกัด เวลาอาจทำให้เกิดการเปลี่ยนแปลงเล็กน้อย ( < 0.5 ) จุดในการคำนวณของ pass@1 และ pass@5 ตัวชี้วัด หากคุณสังเกตเห็นการเปลี่ยนแปลงที่สำคัญในประสิทธิภาพให้ปรับธง --num_process_evaluate ให้เป็นค่าที่ต่ำกว่าหรือเพิ่มค่า --timeout โปรดรายงานปัญหาเฉพาะที่เกิดจากการหมดเวลาที่ไม่เหมาะสมที่นี่
ในที่สุดเพื่อให้ได้คะแนนผ่านหน้าต่างเวลาที่แตกต่างกันคุณสามารถใช้./lcb_runner/evaluation/compute_scores.py ไฟล์ โดยเฉพาะอย่างยิ่งคุณสามารถให้ --start_date และ --end_date ตั้งค่าสถานะ (ใช้รูปแบบ YYYY-MM-DD ) เพื่อรับคะแนนผ่านหน้าต่างเวลาที่กำหนด ในบทความของเราเพื่อตอบโต้การปนเปื้อนในแบบจำลอง Deepseek เราจะรายงานผลเกี่ยวกับปัญหาที่ปล่อยออกมาหลังจากเดือนสิงหาคม 2566 คุณสามารถทำซ้ำการประเมินเหล่านั้นโดยใช้:
python -m lcb_runner.evaluation.compute_scores --eval_all_file {saved_eval_all_file} --start_date 2023-09-01 หมายเหตุ: เราได้ตัดแต่งเคสทดสอบจำนวนมากจากเกณฑ์มาตรฐานดั้งเดิมและสร้าง code_generation_lite ซึ่งตั้งค่าเป็นเกณฑ์มาตรฐานเริ่มต้นที่เสนอการประมาณประสิทธิภาพที่คล้ายกันเร็วกว่ามาก หากคุณต้องการใช้เกณฑ์มาตรฐานดั้งเดิมโปรดใช้ธง --not_fast เราอยู่ในขั้นตอนการอัปเดตคะแนนลีดเดอร์บอร์ดด้วยการตั้งค่าที่อัปเดตนี้
หมายเหตุ: การอัปเดต V2: หากต้องการเรียกใช้การอัปเดต liveCodeBench โปรดใช้ --release_version release_v2 นอกจากนี้หากคุณมีผลลัพธ์ที่มีอยู่จาก release_v1 คุณสามารถเพิ่ม --continue_existing หรือดีกว่า --continue_existing_with_eval ธงเพื่อนำความสำเร็จเก่าหรือการประเมินกลับมาใช้ใหม่ตามลำดับ
สำหรับการซ่อมแซมตัวเองคุณจะต้องจัดทำธง --codegen_n เพิ่มเติมที่แมปกับจำนวนรหัสที่สร้างขึ้นระหว่างการสร้างรหัส นอกจากนี้ -ธง --temperature ใช้เพื่อแก้ไขไฟล์การสร้างรหัสเก่าซึ่งจะต้องมีอยู่ในไดเรกทอรี output
python -m lcb_runner.runner.main --model {model_name --scenario selfrepair --codegen_n {num_codes_codegen} --n 1 # only n=1 supported ในกรณีที่คุณมีผลลัพธ์ในชุดย่อยขนาดเล็กหรือรุ่นของเกณฑ์มาตรฐานคุณสามารถใช้ --continue_existing และ --continue_existing_with_eval ธงเพื่อนำการคำนวณแบบเก่ามาใช้ซ้ำ โดยเฉพาะอย่างยิ่งคุณสามารถเรียกใช้คำสั่งต่อไปนี้เพื่อดำเนินการต่อจากโซลูชันที่สร้างขึ้นที่มีอยู่
python -m lcb_runner.runner.main --model {model_name} --scenario selfrepair --evaluate --continue_existing โปรดทราบว่าสิ่งนี้จะนำตัวอย่างที่สร้างขึ้นมาใช้ใหม่และการประเมินซ้ำอีกครั้ง ในการนำการประเมินแบบเก่ากลับมาใช้ใหม่คุณสามารถเพิ่ม --continue_existing_with_eval Flag
สำหรับการเรียกใช้สถานการณ์การทำนายผลการทดสอบคุณสามารถเรียกใช้ได้
python -m lcb_runner.runner.main --model {model_name} --scenario testoutputprediction --evaluateสำหรับการเรียกใช้สถานการณ์การทำนายผลการทดสอบคุณสามารถเรียกใช้ได้
python -m lcb_runner.runner.main --model {model_name} --scenario codeexecution --evaluateนอกจากนี้เรารองรับการตั้งค่า COT ด้วย
python -m lcb_runner.runner.main --model {model_name} --scenario codeexecution --cot_code_execution --evaluate หรือคุณสามารถใช้ lcb_runner/runner/custom_evaluator.py เพื่อประเมินรุ่นรุ่นโดยตรงในไฟล์ที่กำหนดเอง ไฟล์ควรมีรายการของโมเดลเอาต์พุตจัดรูปแบบ appropiritive สำหรับการประเมินผลตามลำดับของปัญหามาตรฐาน
python -m lcb_runner.runner.custom_evaluator --custom_output_file {path_to_custom_outputs}โดยเฉพาะอย่างยิ่งจัดเรียงผลลัพธ์ในรูปแบบต่อไปนี้
[
{ "question_id" : " id1 " , "code_list" : [ " code1 " , " code2 " ]},
{ "question_id" : " id2 " , "code_list" : [ " code1 " , " code2 " ]}
]เพื่อเพิ่มการสนับสนุนสำหรับรุ่นใหม่เราได้ใช้เฟรมเวิร์กที่ขยายได้เพื่อเพิ่มโมเดลใหม่และปรับแต่งพรอมต์ได้อย่างเหมาะสม
ขั้นตอนที่ 1: เพิ่มโมเดลใหม่ลงในไฟล์./lcb_runner/lm_styles.py โดยเฉพาะอย่างยิ่งขยายคลาส LMStyle เพื่อเพิ่มตระกูลรุ่นใหม่และขยายโมเดลไปยังอาร์เรย์ LanguageModelList
ขั้นตอนที่ 2: เนื่องจากเราใช้โมเดลที่ปรับแต่งคำสั่งเราจึงอนุญาตให้กำหนดค่าคำสั่งสำหรับแต่ละรุ่น แก้ไขไฟล์ ./lcb_runner/prompts/generation.py เพื่อเพิ่มพรอมต์ใหม่สำหรับรุ่นในฟังก์ชัน format_prompt_generation ตัวอย่างเช่นพรอมต์สำหรับตระกูล DeepSeekCodeInstruct ของแบบจำลองมีลักษณะดังนี้
# ./lcb_runner/prompts/generation.py
if LanguageModelStyle == LMStyle . DeepSeekCodeInstruct :
prompt = f" { PromptConstants . SYSTEM_MESSAGE_DEEPSEEK } n n "
prompt += f" { get_deepseekcode_question_template_answer ( question ) } "
return prompt ในการส่งโมเดลไปยังกระดานผู้นำคุณสามารถกรอกแบบฟอร์มนี้ คุณจะต้องกรอกรายละเอียดแบบจำลองและให้ไฟล์การประเมินที่สร้างขึ้นด้วยรุ่นรุ่นและคะแนน PASS@1 เราจะตรวจสอบการส่งและเพิ่มโมเดลลงในกระดานผู้นำตาม
เราเก็บรักษารายการปัญหาและการอัปเดตที่ทราบในไฟล์ errata.md โดยเฉพาะอย่างยิ่งเราจัดทำเอกสารปัญหาเกี่ยวกับการทดสอบที่ผิดพลาดและปัญหาที่ไม่สามารถตอบสนองได้ เราใช้ความคิดเห็นนี้อย่างต่อเนื่องเพื่อปรับปรุงการเลือกฮิวริสติกการเลือกปัญหาของเราในขณะที่เราอัปเดต LiveCodeBench
LiveCodeBench สามารถใช้ในการประเมินประสิทธิภาพของ LLMs ในช่วงเวลาที่แตกต่างกัน (ใช้วันที่วางปัญหาเพื่อกรองโมเดล) ดังนั้นเราสามารถตรวจจับและป้องกันการปนเปื้อนที่อาจเกิดขึ้นในกระบวนการประเมินและประเมิน LLMs เกี่ยวกับปัญหา ใหม่
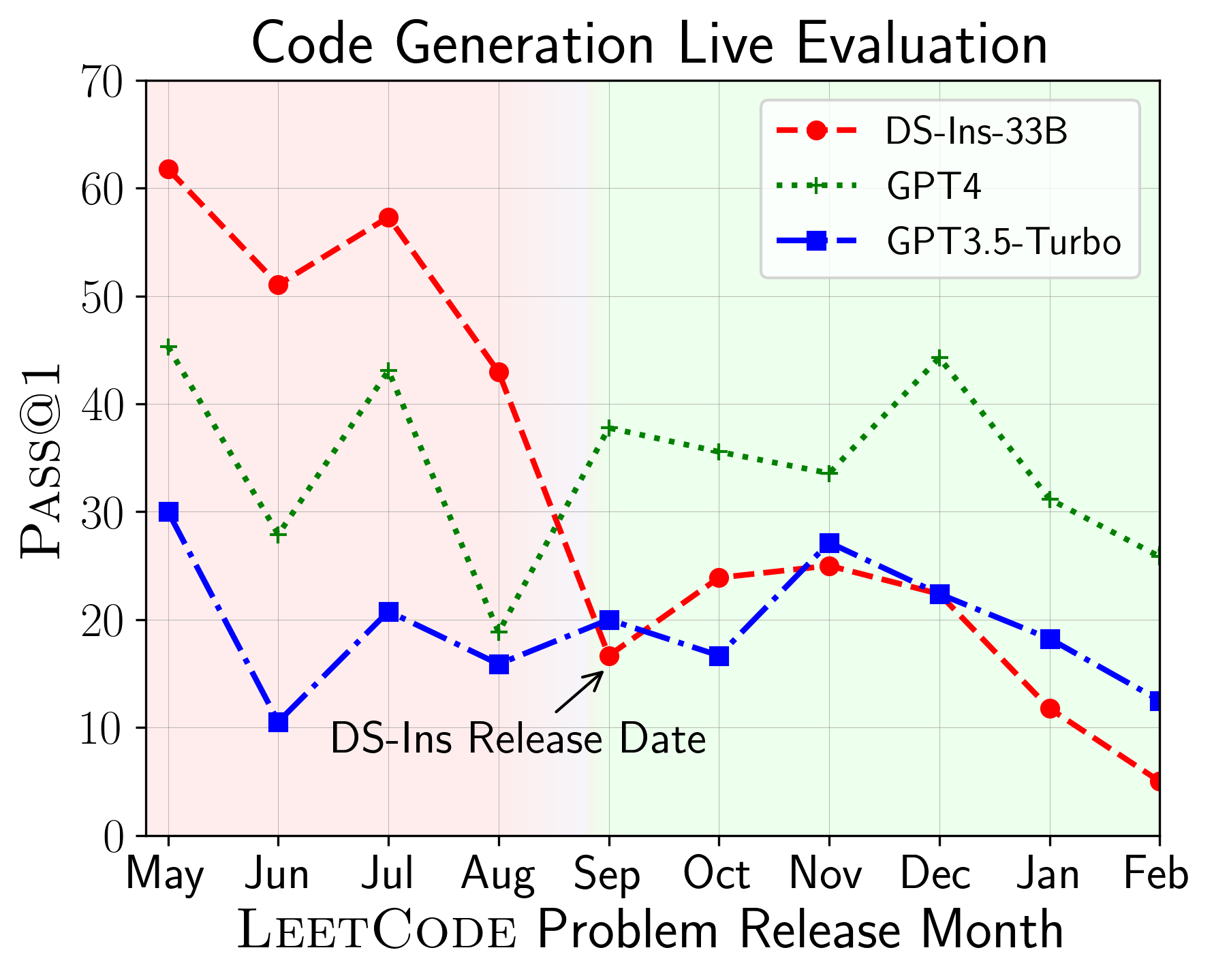
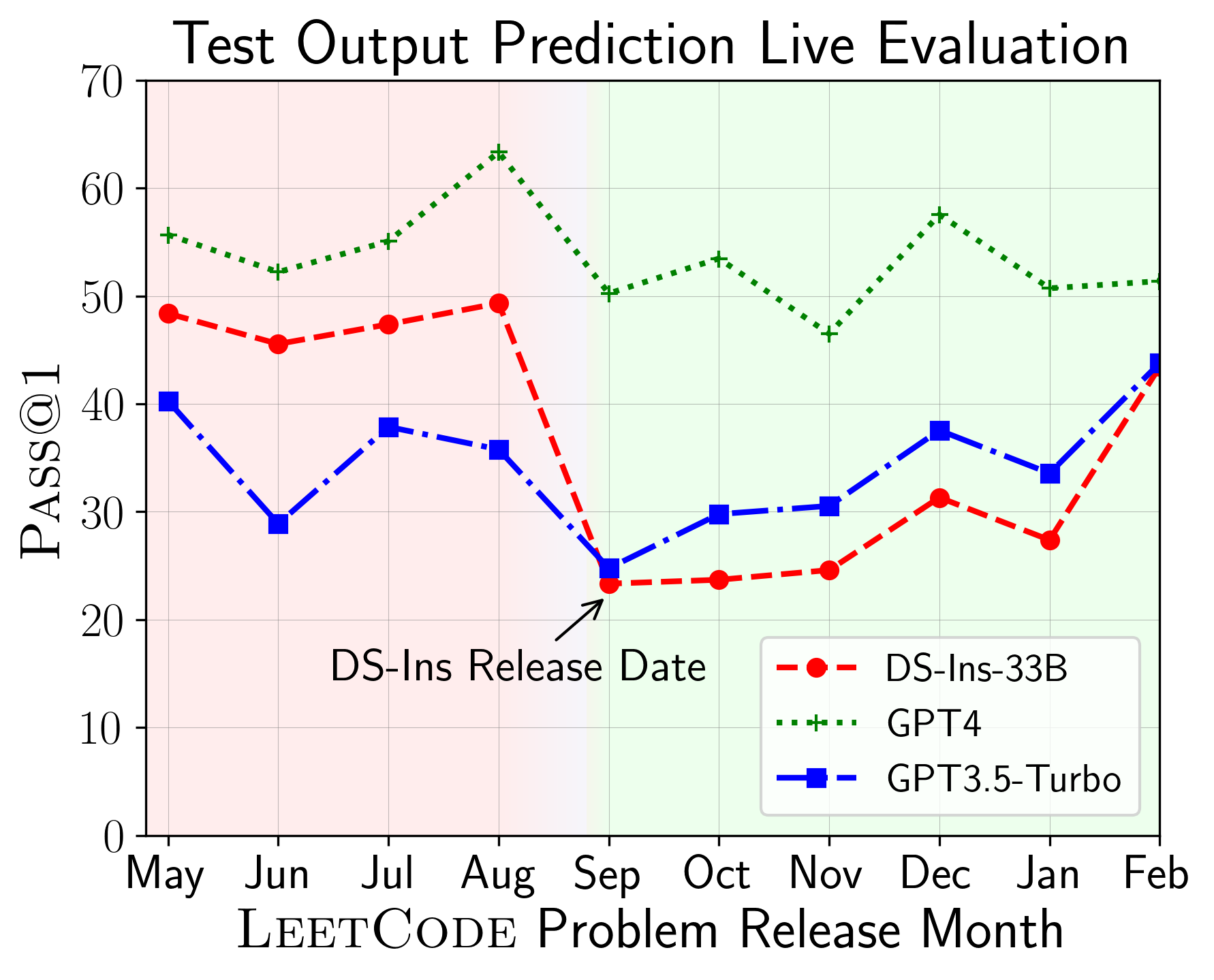
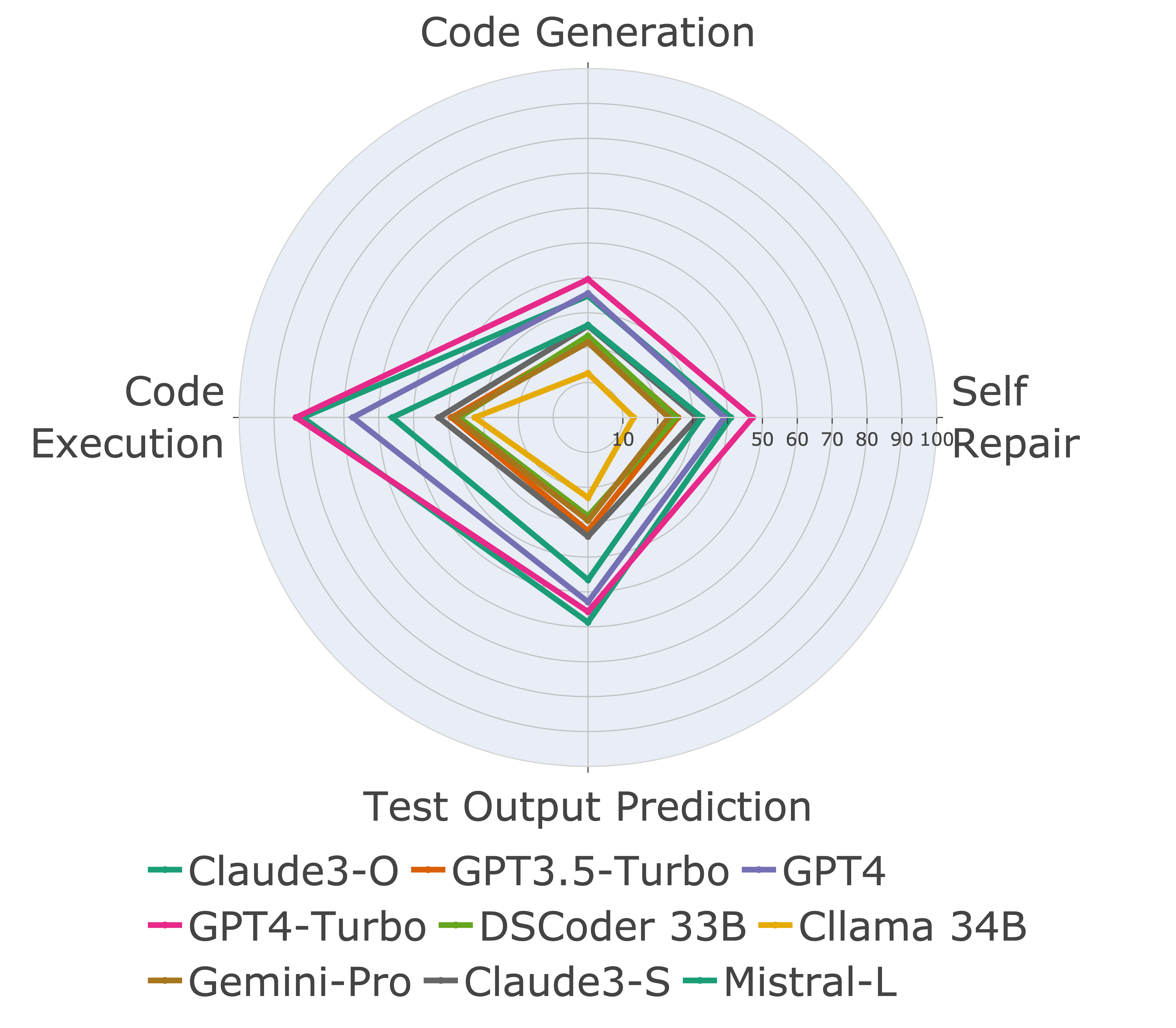
ต่อไปเราจะประเมินโมเดลเกี่ยวกับความสามารถในการใช้รหัสที่แตกต่างกันและพบว่าการแสดงที่สัมพันธ์กันของโมเดลมีการเปลี่ยนแปลงมากกว่างาน (ซ้าย) ดังนั้นจึงเน้นถึงความจำเป็นในการประเมินแบบองค์รวมของ LLM สำหรับรหัส
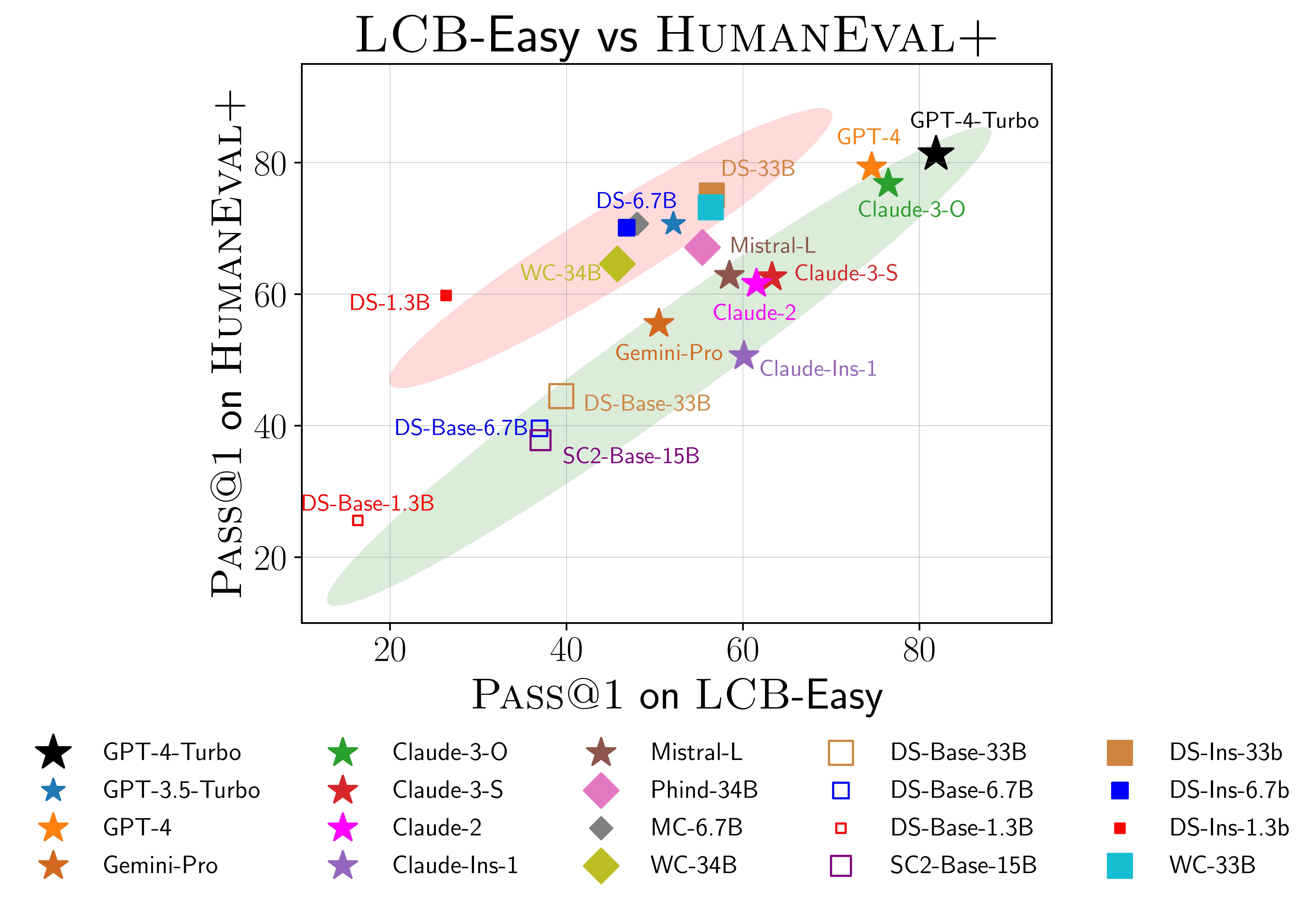
นอกจากนี้เรายังพบหลักฐานว่ามีความเป็นไปได้มากเกินไปเกี่ยวกับ Humaneval (ขวา) โดยเฉพาะอย่างยิ่งแบบจำลองที่ทำงานได้ดีบน Humaneval ไม่จำเป็นต้องทำงานได้ดีบน LiveCodeBench ใน scatterplot ด้านบนเราพบว่าโมเดลได้รับการจัดกลุ่มเป็นสองกลุ่มโดยแรเงาด้วยสีแดงและสีเขียว กลุ่มสีแดงมีแบบจำลองที่ทำงานได้ดีบนมนุษย์ แต่ไม่ดีใน LiveCodeBench ในขณะที่กลุ่มสีเขียวมีแบบจำลองที่ทำงานได้ดีทั้งคู่
สำหรับรายละเอียดเพิ่มเติมโปรดดูเว็บไซต์ของเราที่ LiveCodeBench.github.io
@article { jain2024livecodebench ,
author = { Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, Ion Stoica } ,
title = { LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code } ,
year = { 2024 } ,
journal = { arXiv preprint } ,
}

