LiveCodeBench
1.0.0
المستودع الرسمي للورقة "LiveCodeBench: التقييم الشامل والتلوث المجاني لنماذج اللغة الكبيرة للرمز"
؟ الصفحة الرئيسية • البيانات •؟ لوحة المتصدرين
يوفر LiveCodeBench تقييمًا كليًا وخالي من التلوث لقدرات الترميز لـ LLMS. على وجه الخصوص ، يجمع LiveCodeBench بشكل مستمر مشاكل جديدة مع مرور الوقت من المسابقات عبر ثلاث منصات منافسة - LeetCode و Atcoder و Codeforces. بعد ذلك ، يركز LiveCodeBench أيضًا على مجموعة أوسع من القدرات المتعلقة بالشفرة ، مثل الإخلاء الذاتي وتنفيذ الكود والتنبؤ بإخراج الاختبار ، إلى ما بعد مجرد توليد الكود. في الوقت الحالي ، يستضيف LiveCodeBench أربعمائة مشكلات ترميز عالية الجودة تم نشرها بين مايو 2023 و March 2024.
يمكنك استنساخ المستودع باستخدام الأمر التالي:
git clone https://github.com/LiveCodeBench/LiveCodeBench.git
cd LiveCodeBenchنوصي باستخدام الشعر لإدارة التبعيات. يمكنك تثبيت الشعر والتبعيات باستخدام الأوامر التالية:
pip install poetry
poetry install لا يقوم الإعداد الافتراضي بتثبيت vllm . لتثبيت vllm أيضًا يمكنك استخدامه:
poetry install --with with-gpuنحن نقدم معيارًا لسيناريوهات قدرة الكود المختلفة
نظرًا لأن LiveCodeBench هو معيار محدث بشكل مستمر ، فإننا نقدم إصدارات مختلفة من مجموعة البيانات. على وجه الخصوص ، نحن نقدم الإصدارات التالية من مجموعة البيانات:
release_v1 : الإصدار الأولي لمجموعة البيانات مع المشكلات التي تم إصدارها بين مايو 2023 و MAR 2024 تحتوي على 400 مشكلة.release_v2 : الإصدار المحدث لمجموعة البيانات مع المشكلات التي تم إصدارها بين مايو 2023 ومايو 2024 تحتوي على 511 مشكلة.release_v3 : الإصدار المحدث لمجموعة البيانات مع المشكلات التي تم إصدارها بين مايو 2023 و Jul 2024 التي تحتوي على 612 مشكلة.release_v4 : الإصدار المحدث لمجموعة البيانات مع المشكلات التي تم إصدارها بين مايو 2023 و Sep 2024 التي تحتوي على 713 مشكلة. يمكنك استخدام علامة --release_version لتحديد إصدار مجموعة البيانات التي ترغب في استخدامها. على وجه الخصوص ، يمكنك استخدام الأمر التالي لتشغيل التقييم على مجموعة بيانات release_v2 . إصدار إصدار الافتراضات لإصدار release_latest .
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration --evaluate --release_version release_v2 نستخدم vllm للاستدلال باستخدام النماذج المفتوحة. بشكل افتراضي ، نستخدم tensor_parallel_size=${num_gpus} لتوازي الاستدلال عبر جميع وحدات معالجة الرسومات المتاحة. يمكن تكوينه باستخدام علامة --tensor_parallel_size كما هو مطلوب.
لتشغيل الاستدلال ، يرجى تقديم model_name استنادًا إلى ملف ./lcb_runner/lm_styles.py. يمكن استخدام السيناريو (هنا codegeneration ) لتحديد السيناريو للنموذج.
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration بالإضافة إلى ذلك ، يمكن استخدام علامة --use_cache لتخزين المخرجات التي تم إنشاؤها ، ويمكن استخدام علامة --continue_existing لاستخدام النتائج التي تم إلقاؤها. في حال كنت ترغب في استخدام النموذج من مسار محلي ، يمكنك تقديم علامة --local_model_path مع المسار إلى النموذج. نستخدم n=10 ودرجة temperature=0.2 للجيل. يرجى التحقق من ملف ./lcb_runner/runner/parser.py لمزيد من التفاصيل على الأعلام.
بالنسبة لنماذج API المغلقة ، يمكن استخدام علامة --multiprocess المتعلقة بموازاة الاستعلامات لخوادم API (قابلة للتعديل وفقًا لحدود المعدل).
نقوم بحساب pass@1 pass@5 مقاييس لتقييم النماذج. نستخدم نسخة معدلة من المدقق الذي تم إصداره مع معيار apps لحساب المقاييس. على وجه الخصوص ، حددنا بعض حالات الحافة غير المألوفة في المدقق الأصلي وقمنا بإصلاحها وتبسيط المدقق بالإضافة إلى ذلك بناءً على مجموعة البيانات التي تم جمعها. لتشغيل التقييم ، يمكنك إضافة علم --evaluate :
python -m lcb_runner.runner.main --model {model_name} --scenario codegeneration --evaluate لاحظ أن الحدود الزمنية يمكن أن تسبب نقاط تباين بسيطة ( < 0.5 ) في حساب pass@1 pass@5 مقاييس. إذا لاحظت تباينًا كبيرًا في الأداء ، فقم بضبط العلم --num_process_evaluate إلى قيمة أقل أو زيادة علامة --timeout . يرجى الإبلاغ عن مشكلات معينة ناتجة عن مهلة غير لائقة هنا.
أخيرًا ، للحصول على درجات عبر Windows الزمنية المختلفة ، يمكنك استخدام ./lcb_runner/evaluation/compute_scores.py ملف. على وجه الخصوص ، يمكنك توفير علامات- --start_date و --end_date (باستخدام تنسيق YYYY-MM-DD ) للحصول على درجات عبر النافذة الزمنية المحددة. في ورقتنا ، لمواجهة التلوث في نماذج Deepseek ، نقوم فقط بالإبلاغ عن نتائج عن المشكلات التي تم إصدارها بعد أغسطس 2023. يمكنك تكرار تلك التقييمات باستخدام:
python -m lcb_runner.evaluation.compute_scores --eval_all_file {saved_eval_all_file} --start_date 2023-09-01 ملاحظة: قمنا بتقليم عدد كبير من حالات الاختبار من المعيار الأصلي وأنشأنا code_generation_lite والذي تم تعيينه كمعيار افتراضي يقدم تقديرًا مماثلًا للأداء بشكل أسرع. إذا كنت ترغب في استخدام المعيار الأصلي ، فيرجى استخدام علامة --not_fast . نحن بصدد تحديث درجات المتصدرين مع هذا الإعداد المحدث.
ملاحظة: تحديث V2: لتشغيل التحديث LiveCodeBench ، يرجى استخدام --release_version release_v2 . بالإضافة إلى ذلك ، إذا كان لديك نتائج موجودة من release_v1 ، فيمكنك إضافة --continue_existing أو أفضل --continue_existing_with_eval لإعادة استخدام الإكمال أو التقييمات القديمة على التوالي.
لتشغيل الإصلاح الذاتي ، تحتاج إلى توفير علامة إضافية --codegen_n التي ترسم عدد الرموز التي تم إنشاؤها أثناء توليد الكود. بالإضافة إلى ذلك ، يتم استخدام علامة --temperature لحل ملف Eval القديم لتوليد الكود الذي يجب أن يكون موجودًا في دليل output .
python -m lcb_runner.runner.main --model {model_name --scenario selfrepair --codegen_n {num_codes_codegen} --n 1 # only n=1 supported في حالة وجود نتائج على مجموعة فرعية أصغر أو إصدارًا من المعيار ، يمكنك استخدام --continue_existing و --continue_existing_with_eval لإعادة استخدام الحسابات القديمة. على وجه الخصوص ، يمكنك تشغيل الأمر التالي للاستمرار من الحلول التي تم إنشاؤها الحالية.
python -m lcb_runner.runner.main --model {model_name} --scenario selfrepair --evaluate --continue_existing لاحظ أن هذا سيعيد استخدام العينات التي تم إنشاؤها فقط وإعادة التقييم. لإعادة استخدام التقييمات القديمة ، يمكنك إضافة علامة --continue_existing_with_eval .
لتشغيل سيناريو التنبؤ بإخراج الاختبار ، يمكنك ببساطة التشغيل
python -m lcb_runner.runner.main --model {model_name} --scenario testoutputprediction --evaluateلتشغيل سيناريو التنبؤ بإخراج الاختبار ، يمكنك ببساطة التشغيل
python -m lcb_runner.runner.main --model {model_name} --scenario codeexecution --evaluateبالإضافة إلى ذلك ، فإننا ندعم إعداد COT مع
python -m lcb_runner.runner.main --model {model_name} --scenario codeexecution --cot_code_execution --evaluate بدلاً من ذلك ، يمكنك استخدام lcb_runner/runner/custom_evaluator.py لتقييم الأجيال النموذجية مباشرة في ملف مخصص. يجب أن يحتوي الملف على قائمة بمخرجات النموذج ، تم تنسيقها بشكل معتدل للتقييم بترتيب المشكلات القياسية.
python -m lcb_runner.runner.custom_evaluator --custom_output_file {path_to_custom_outputs}على وجه الخصوص ، ترتيب المخرجات بالتنسيق التالي
[
{ "question_id" : " id1 " , "code_list" : [ " code1 " , " code2 " ]},
{ "question_id" : " id2 " , "code_list" : [ " code1 " , " code2 " ]}
]لإضافة دعم لنماذج جديدة ، قمنا بتطبيق إطار عمل قابل للتمديد لإضافة نماذج جديدة وتخصيص المطالبات بشكل معتدل.
الخطوة 1: أضف نموذجًا جديدًا إلى ملف ./lcb_runner/lm_styles.py. على وجه الخصوص ، قم بتوسيع فئة LMStyle لإضافة عائلة نموذجية جديدة وتوسيع النموذج إلى صفيف LanguageModelList .
الخطوة 2: نظرًا لأننا نستخدم النماذج المضبوطة بالتعليمات ، فإننا نسمح بتكوين التعليمات لكل نموذج. تعديل ملف ./lcb_runner/prompts/generation.py لإضافة مطالبة جديدة للنموذج في وظيفة format_prompt_generation . على سبيل المثال ، يبدو أن مطالبة عائلة النماذج DeepSeekCodeInstruct
# ./lcb_runner/prompts/generation.py
if LanguageModelStyle == LMStyle . DeepSeekCodeInstruct :
prompt = f" { PromptConstants . SYSTEM_MESSAGE_DEEPSEEK } n n "
prompt += f" { get_deepseekcode_question_template_answer ( question ) } "
return prompt لتقديم نماذج إلى لوحة المتصدرين ، يمكنك ملء هذا النموذج. ستحتاج إلى ملء تفاصيل النموذج وتزويد ملف التقييم الذي تم إنشاؤه بأجيال نموذجية وتمرير درجات@1. سنراجع التقديم وإضافة النموذج إلى المتصدرين وفقًا لذلك.
نحافظ على قائمة بالمشكلات والتحديثات المعروفة في ملف errata.md. على وجه الخصوص ، نحن نوثق المشكلات المتعلقة بالاختبارات الخاطئة والمشاكل غير القابلة للتطبيق الذاتي. نحن نستخدم هذه الملاحظات باستمرار لتحسين الاستدلال على مشكلاتنا أثناء تحديث LiveCodeBench.
يمكن استخدام LiveCodeBench لتقييم أداء LLMs على النوافذ الزمنية المختلفة (باستخدام تاريخ إصدار المشكلة لتصفية النماذج). وبالتالي يمكننا اكتشاف ومنع التلوث المحتمل في عملية التقييم وتقييم LLMs على مشاكل جديدة .
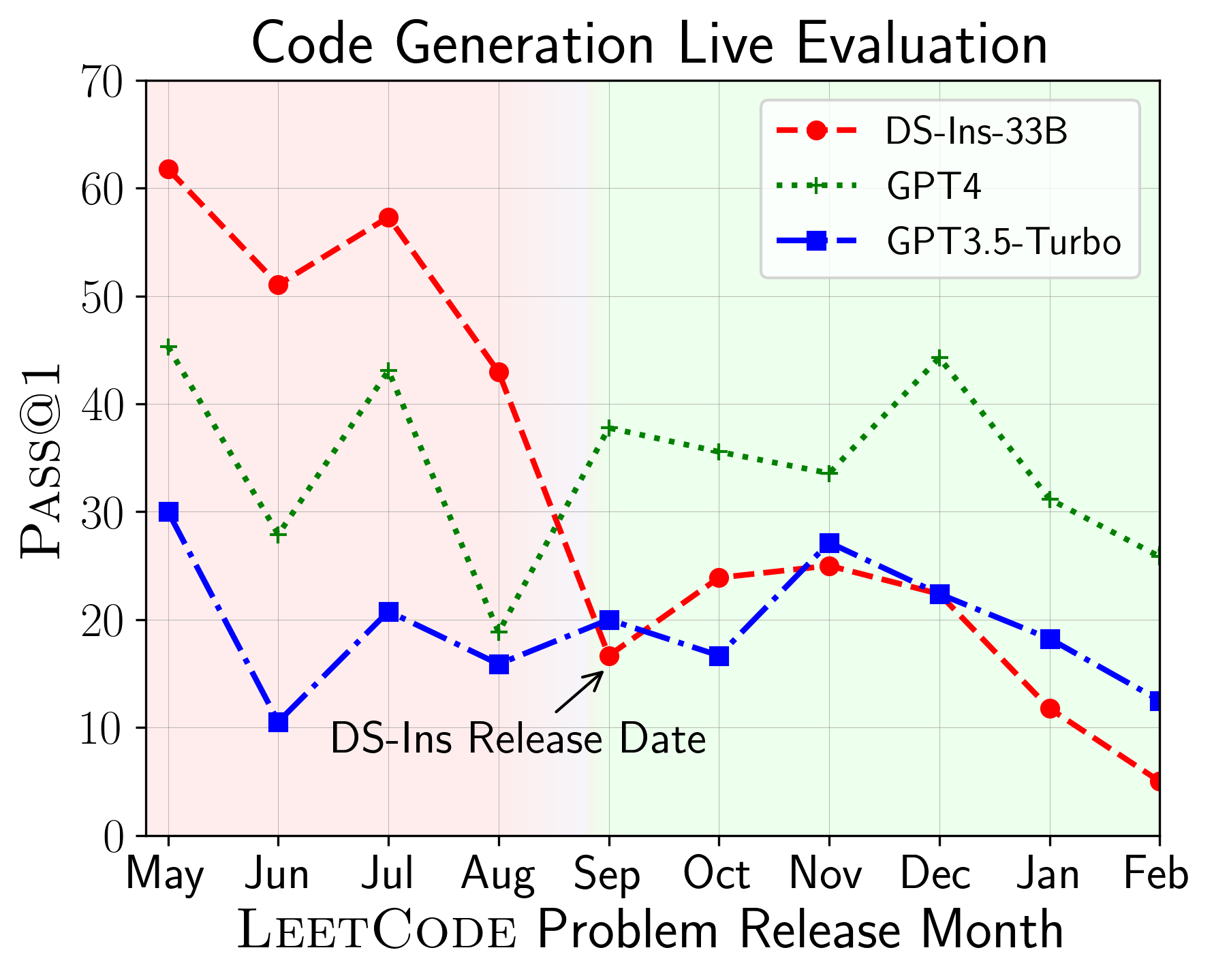
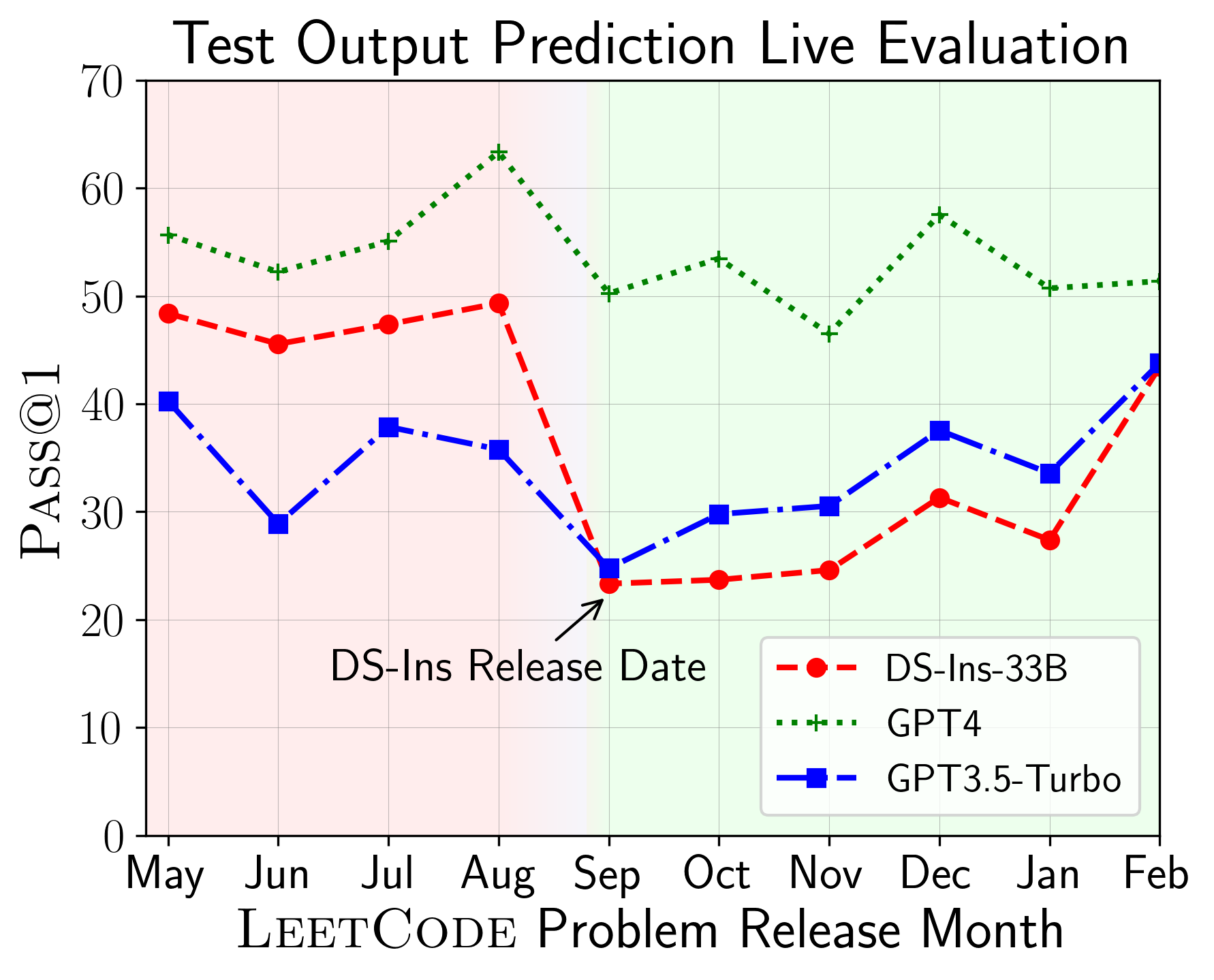
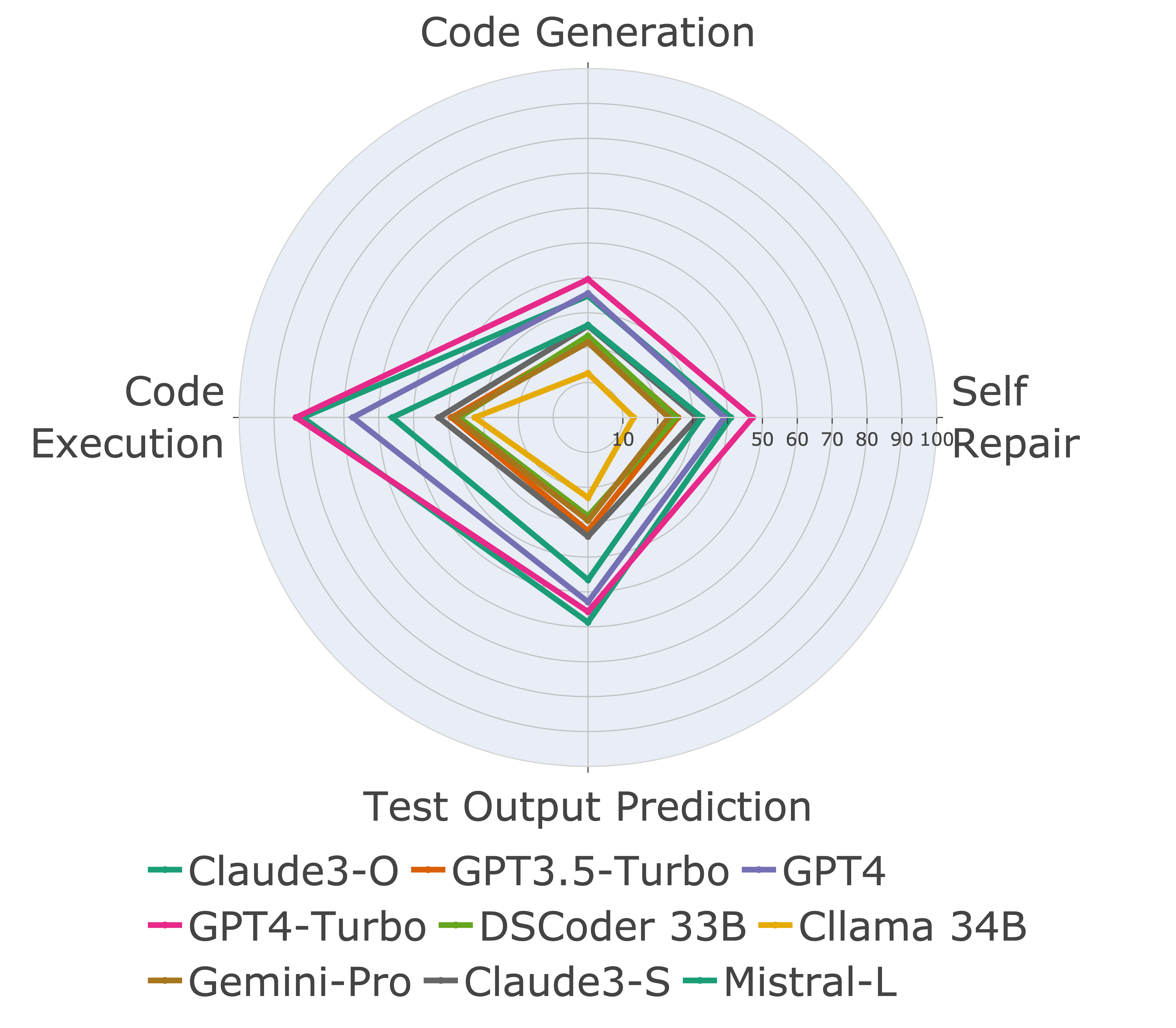
بعد ذلك ، نقوم بتقييم النماذج على إمكانيات الكود المختلفة ونجد أن العروض النسبية للنماذج تتغير على المهام (يسار). وبالتالي ، فإنه يسلط الضوء على الحاجة إلى التقييم الشامل لـ LLMs للرمز.
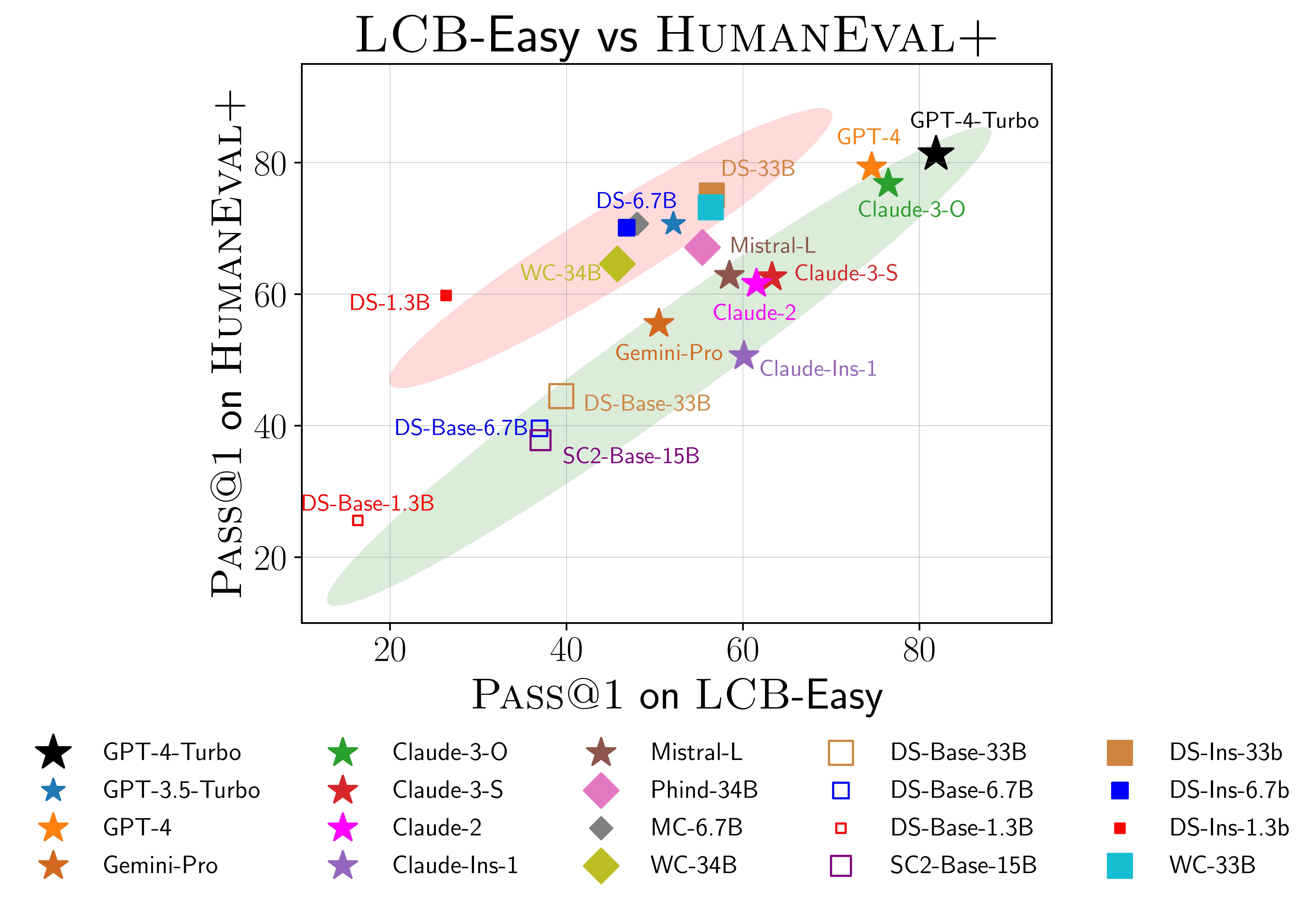
نجد أيضًا أدلة على إمكانية التورط على Humaneval (يمين). على وجه الخصوص ، لا تؤدي النماذج التي تؤدي بشكل جيد على Humaneval بالضرورة أداءً جيدًا على LiveCodeBench. في scatterplot أعلاه ، نجد أن النماذج يتم تجميعها في مجموعتين ، مظللة باللون الأحمر والأخضر. تحتوي المجموعة الحمراء على نماذج تؤدي أداءً جيدًا على Humaneval ولكنها ضعيفة في LiveCodeBench ، بينما تحتوي المجموعة الخضراء على نماذج تعمل بشكل جيد على كليهما.
لمزيد من التفاصيل ، يرجى الرجوع إلى موقعنا على موقع LiveCodeBench.github.io.
@article { jain2024livecodebench ,
author = { Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, Ion Stoica } ,
title = { LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code } ,
year = { 2024 } ,
journal = { arXiv preprint } ,
}

